
Я хочу показать некоторые эффективные способы извлечения функций из изображений с помощью числовой векторизации.
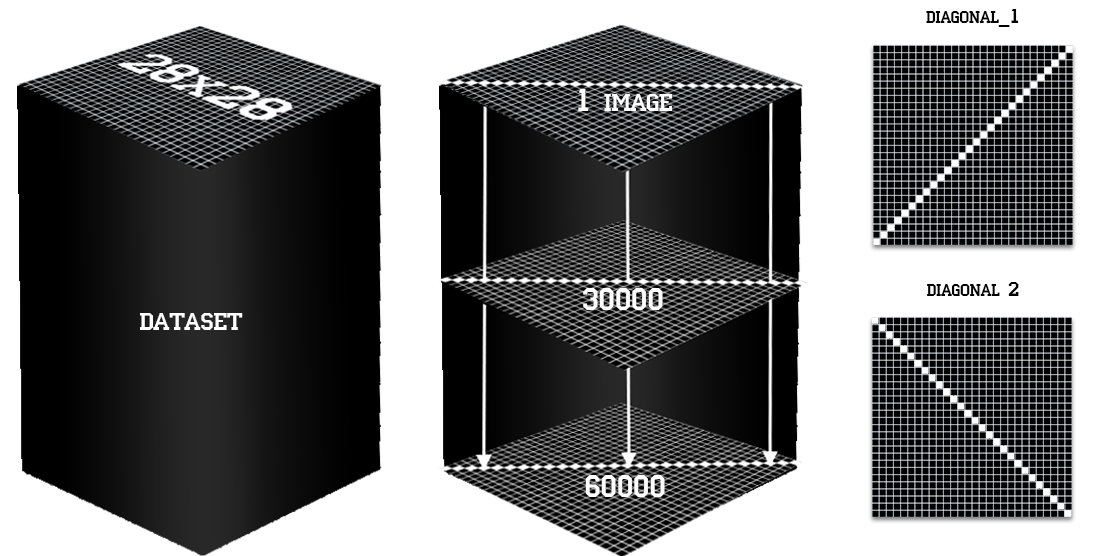
В качестве объекта экспериментов я выбрал набор данных Fashion MNIST.
Набор данных состоит из:
- 60000 и 10000 поездов / тестовых изображений;
- каждое изображение имеет размер 28x28 пикселей;
- и они представляют 10 разных видов одежды.
В качестве изображения набор данных поезда можно представить в виде 60000 листов квадратной бумаги (28х28 dim) 10 разных цветов, которые накладываются друг на друга:

Векторизованный подход к манипулированию данными позволяет обойти 60000 циклов «for» и извлечь такое же количество значений за 1 операцию.
Но перед стартом мы собираемся:
- преобразовать наш набор данных в форму (28, 28, 60000);
- инициализировать некоторые переменные: «m» как количество изображений, «h» и «w» как высоту и ширину изображения;
- создать массив numpy для хранения новых функций;
- разделите все входные значения пикселей на 255.
Первые две характеристики будут коэффициентами вариации (CV) диагональных и антидиагональных пикселей изображения:
Эта схема поможет вам лучше понять, какие именно характеристики были получены:
- взять 28 значений диагональных пикселей (и антидиагональных) каждого изображения (28, 60000);
- вычислить стандартное отклонение (std) этих 28 диагональных значений;
- вычислить среднее из этих 28 диагональных значений;
- разделите стандартное значение на среднее значение и получите 1 значение (CV) для каждого изображения (1, 60000);
- сохраните эти 60000 значений как один столбец (функцию).
Чтобы увидеть физический смысл этих функций, мы можем сделать следующее:
Из графика мы можем понять, какие пиксели мы возьмем для вычисления первого признака (CV диагонали всех изображений).
Но пока не ясно, как это выглядит с точки зрения машинного обучения, поэтому мы можем построить еще один график:
Как видим, всего 2 столбца позволяют отделить «ботильоны» и почти все «сандалии» от других классов.
Давайте добавим еще несколько функций.
Идея этой особенности состоит в том, чтобы определять «формы» картинок: «брюки» имеют прямоугольную форму, ориентированную вертикально, а кроссовки - горизонтальную.
Благодаря хорошо подготовленным изображениям (не повернутым, не перекошенным и т. Д.) Мы получили четкое разделение.
Построение полных расчетов для этих двух классов покажет мощь этой функции для такого типа изображений.
Рассчитайте эту функцию для всего набора данных:
Следующие 4 функции будут представлены расчетами 4 квадрантов ([: 14,: 14], [: 14, 14:], [14 :, 14:], [14 :,: 14]) каждого из 60000 изображений. .
Расчеты следующие:
- разделите наш набор данных на 4 поднабора данных с формой (14, 14, 60000);
- рассчитать для каждого квадранта стандартное отклонение всех 60000 изображений;
- затем таким же образом получают среднее значение квадрантов;
- и, наконец, разделите std на среднее значение и получите CV.
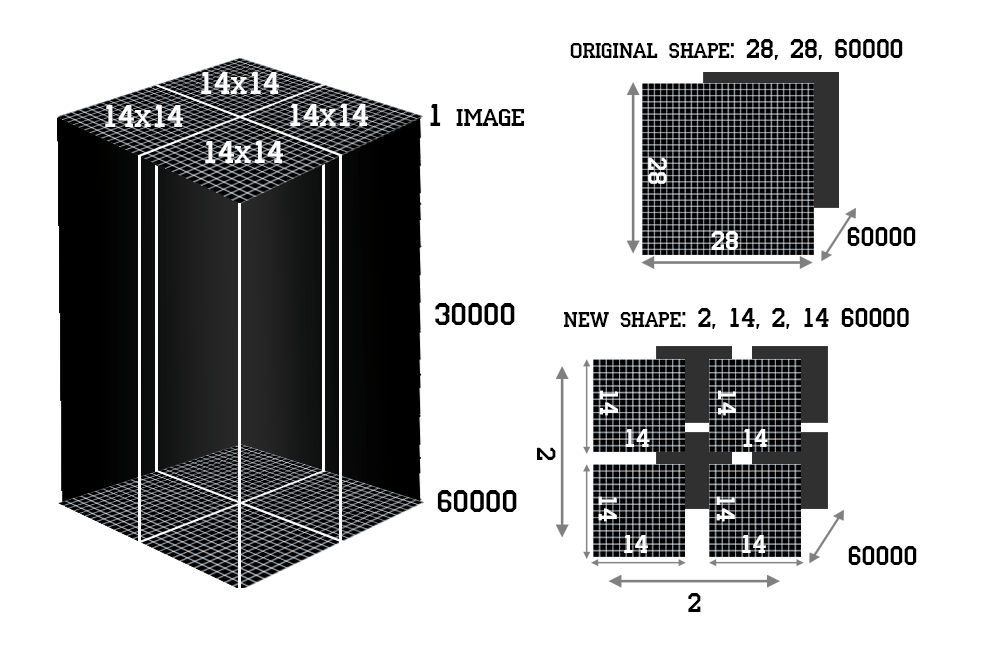
Глядя на картинку выше, мы можем написать код для векторизованных вычислений:
Таким же образом мы можем вычислить CV для диагоналей и антидиагоналей этого квадранта и CV всей его суммы:
- разделить наш набор данных на 4 поднабора данных с формой (14, 14, 60000) (сделано выше);
- взять две диагонали каждого изображения из каждого квадранта;
- вычислить стандартное отклонение для каждой диагонали;
- получить средние двух диагоналей.
- разделить стандартные значения на средние.
- затем суммировать стандартные диагонали и антидиагонали, суммировать среднее значение, разделить их и получить CV.
Таким образом, мы получим 12 новых функций.
Чтобы иметь четкое представление о том, что нужно рассчитывать, я создал игрушечный пример с двумя «изображениями» 4х4.
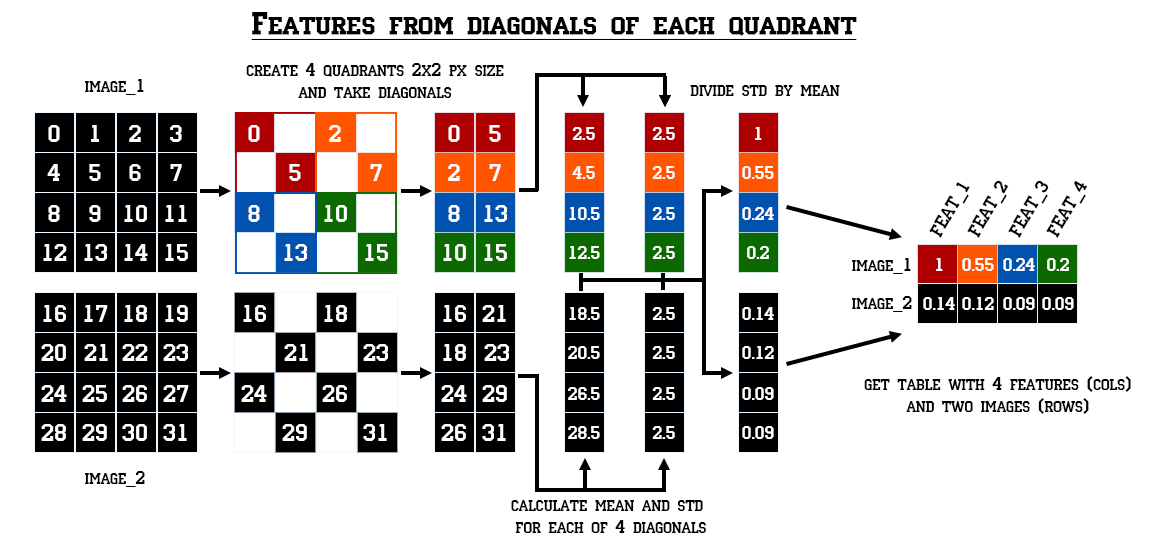

Чтобы получить эти функции для всего набора данных, нам понадобится несколько строк кода:
Здесь и далее время от времени мы будем получать значения Nan из-за деления на ноль: в этих вычислениях некоторые квадранты некоторых изображений пусты, а средние значения их пикселей равны нулю. Чтобы решить эту проблему, мы будем использовать «np.nan_to_num» для преобразования нанов в нули после всех вычислений.
Для просмотра объектов в режиме 3D просмотра мы можем использовать библиотеку mayavi. Здесь я добавлю видео, но не стесняйтесь читать мою другую статью со ссылками на уже созданный инструмент трехмерной визуализации Mayavi.
В видео мы шаг за шагом видим, что каждая следующая добавленная функция отделяет все классы друг от друга: некоторые хорошо разделены, некоторые еще нет. Для исследования данных в многомерном пространстве вы можете использовать библиотеку с открытым исходным кодом Google: https://experiments.withgoogle.com/visualizing-high-dimensional-space.
Фактически, мы можем получить множество функций из изображений: иногда это может быть более полезным, чем развертывание сетей CNN, потому что таким образом вы можете извлечь некоторые конкретные функции, которые ускорят конвергенцию вашей нейронной сети. Например, чтобы классифицировать объекты по форме (круг, квадрат, прямоугольник и т. Д.), Вам может потребоваться определить только несколько конкретных функций для достижения хороших результатов.
Давайте двигаться дальше. Эти 28 функций очень «просто» получить:
- вычислить стандартное количество строк и столбцов и просуммировать их;
- вычислить среднее значение строк и столбцов - просуммировать;
- разделите стандартное значение на среднее значение и получите резюме.
Чтобы рассчитать это, нам понадобится 1 строка кода:
Следующие 150 объектов не векторизованы полностью из-за особенностей их извлечения. Итак, я дам код, как их получить, и вы сможете изучить его, чтобы понять, что именно рассчитывается. Кроме того, я буду признателен за любые предложения, как сделать их полностью векторизованными.
В любом случае их смысл может быть не так важен, потому что основная цель - повысить точность прогноза модели классификации, которая будет их использовать. Насколько эти функции полезны для этой задачи, мы рассмотрим во второй части этой статьи.
Здесь вы можете скачать полный код для извлечения функций. Создавайте эксперименты и получайте собственные мощные функции, которые могут улучшить задачи классификации. Не забывайте делиться ими в комментариях!