Архитектура трансформаторов нарушила все аспекты области НЛП, будь то таблицы лидеров для конкретных задач или промышленные приложения, которые вы чаще всего встречали бы используемой моделью трансформатора. Аналогичным образом Куан Сюй и др. al опубликовал свою работу «SeaD: End-to-end Text-to-SQL Generation with Schema-A Denoising» с основной гипотезой, согласно которой, утверждая, что архитектуры Sequence to Sequence, основанные на трансформаторе тока, достаточно мощны, чтобы преодолеть недостатки, подобные заявленному «SQL запросы с разным порядком предложений могут иметь одно и то же семантическое значение и возвращать одинаковые результаты при выполнении. Взаимозаменяемость токенов может сбивать с толку модель, основанную на генерации S2S. Во-вторых, грамматическое ограничение, вызванное структурной логической формой, игнорируется во время автоагрессивного декодирования, поэтому модель может предсказывать SQL с недопустимой логической формой. В-третьих, связывание схемы, которое, как предполагалось, является ключевым моментом задачи преобразования текста в SQL, в оригинальной модели S2S специально не рассматривается ». для решения задачи преобразования текста в SQL с использованием архитектуры seq2seq.
Кроме того, в этом посте я предложу дополнительный блок преобразователя поверх этого подхода S2S, который может оказаться очень полезным там, где существует очень небольшое лексическое перекрытие между входной последовательностью и схемой или данными, представленными в таблице. Более того, это позволило бы обеспечить сходство на основе векторов по сгенерированным объектам SQL для выполнения связывания объектов. Я объясню весь процесс более подробно ниже.
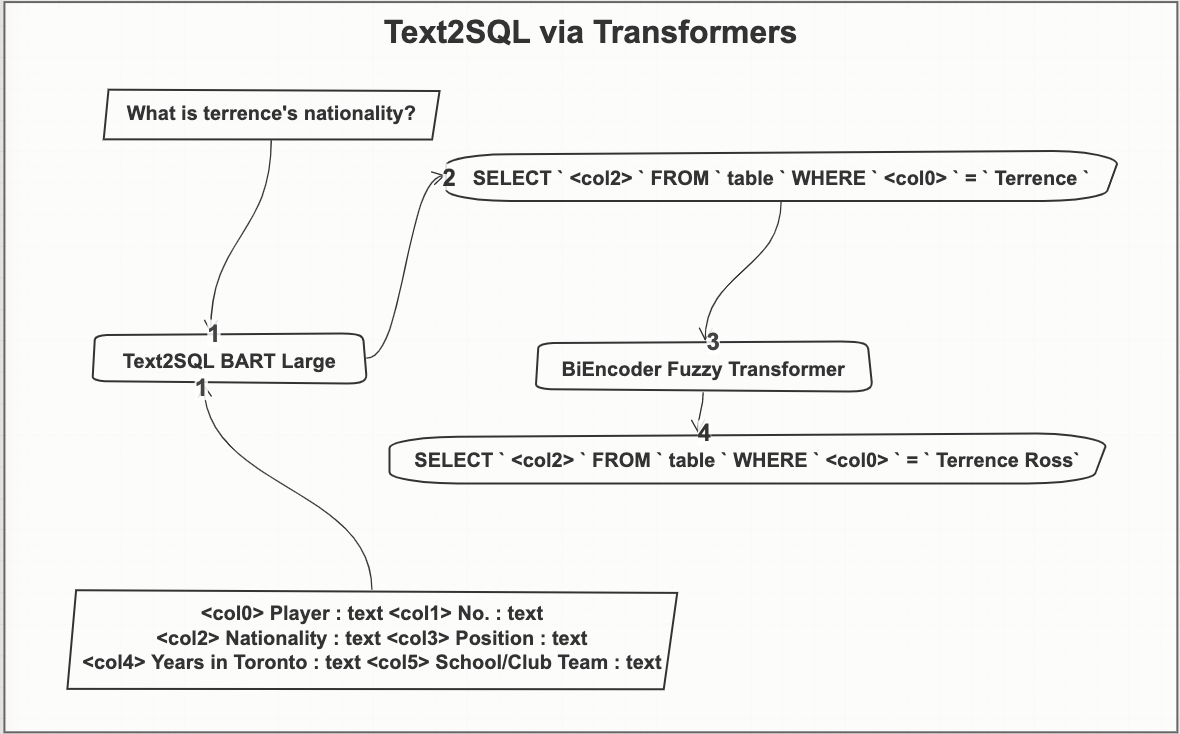
Ниже приведен общий рабочий процесс надежной генерации SQL-запросов путем размещения двух преобразователей один за другим.
Первый преобразователь S2S BART-Large генерирует запрос SQL, когда вы вводите вопрос на естественном языке и схему таблицы. На втором этапе второй преобразователь генерирует векторы для всех сущностей, присутствующих в предложении where сгенерированного SQL. Эти векторы не представляют семантическое представление, а скорее основанное на заклинании или нечеткое представление, поэтому, например, если у нас есть следующая генерация запроса, `Выберите ‹col0› из таблицы, где ‹col1› = bank`. Мы можем посмотреть, где действительно существует банк, в любой ячейке столбца col1, который является псевдо-именем столбца, который находится во втором индексе в списке столбцов схемы. Более того, вектор, который мы сгенерируем для банка сущностей, не будет ближе к вектору, например, денег, однако это встраивание на основе заклинаний, поэтому он будет ближе к таким словам, как группа, койка, поскольку такие слова требуют меньше всего количество правок персонажей, чтобы сделать их идентичными. Для более глубокого понимания, пожалуйста, прочтите этот пост Встраивание для исправления орфографии.
Итак, давайте закончим с первой частью головоломки, где мы будем генерировать SQL-запрос. Я уже предварительно обучил модель S2S, используя некоторые идеи, упомянутые в предыдущей статье. Вот как мы можем использовать модель для вывода.
Наша модель производит следующий вывод SQL: «SELECT` ‹col2› `FROM` table `WHERE` ‹col0› `=` Terrence `". Обратите внимание, что мы использовали вопрос и схему из одного из образцов из тестового набора набора данных WikiSQL. Таблица выглядит так:
Теперь вы можете заметить, что наша модель предсказала в SQL-предложении where как «Player =` Terrence` », поскольку мы упомянули только имя игрока, теперь этот SQL-запрос не будет выполняться в приведенной выше таблице. Здесь на помощь приходит наша вторая модель, которая спасает положение. Мы можем кодировать все ячейки из категориальных столбцов приведенной выше таблицы как векторы и выполнять векторное подобие на основе подобия на основе заклинаний. В этом случае вектор слов «Терренс» и «Терренс Росс» должен быть ближе друг к другу по сравнению с именами других игроков. Это поможет нам, и мы сможем заменить этот бит в запросе, что приведет к окончательному запросу «ВЫБРАТЬ НАЦИОНАЛЬНОСТЬ ИЗ таблицы WHERE Player =‘ Terrence Ross ».
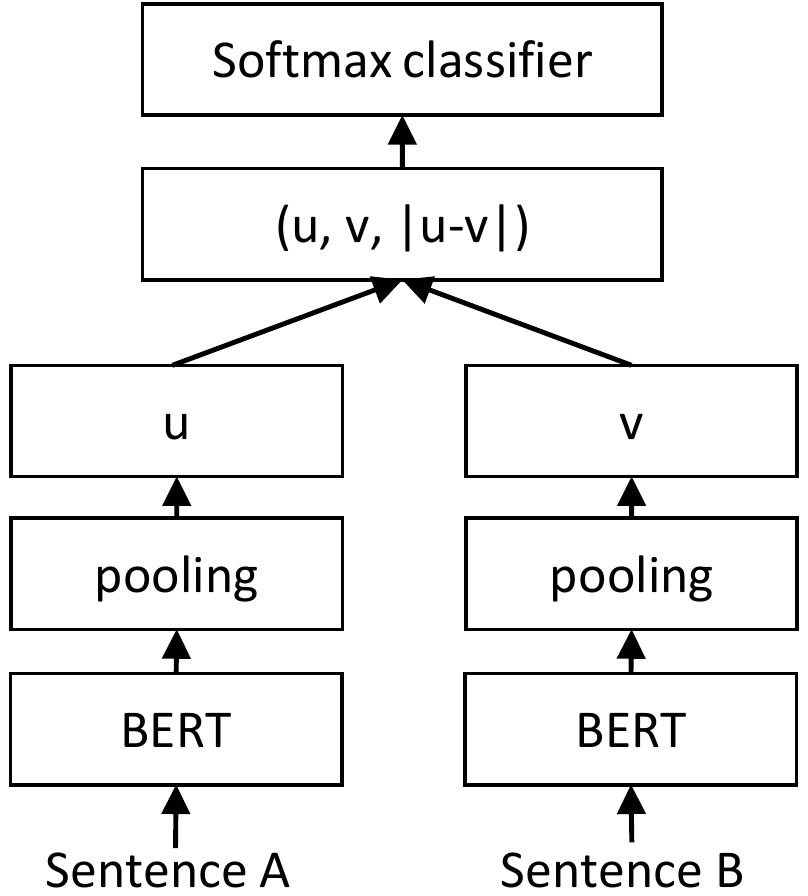
Давайте посмотрим, как это можно реализовать, здесь я также предварительно обучил модель преобразователя, которая способна создавать вложения на основе сходства на уровне символов путем точной настройки архитектуры Sentence BERT (сиамский BERT) на парах слов на уровне символов. Архитектура выглядит следующим образом:
Теперь перейдем к последней части реализации:
Вы можете найти полную записную книжку для этого подхода здесь.
В заключение, трансформаторы дают вам много энергии даже без минимального увеличения объема данных и очистки, они обеспечивают результаты выше среднего. Вышеупомянутый метод обеспечивает точность 65,32% на тестовом наборе набора данных WikiSQL.
Ссылки:
https://github.com/salesforce/WikiSQL
SeaD: сквозное преобразование текста в SQL с шумоподавлением с учетом схемы: Куан Сю. и др.
Sentence-BERT: встраивание предложений с использованием сиамских BERT-сетей: Реймерс, Нильс и Гуревич, Ирина