Выведите свои тренировочные сценарии на новый уровень

Если вы устали переписывать один и тот же шаблонный код ваших обучающих конвейеров в PyTorch, я нашел довольно интересное решение, которое может облегчить вам жизнь. Не волнуйтесь, это не тяжелая библиотека, которая изменит ваш образ действий.
Это скорее легкая оболочка, которая инкапсулирует логику обучения в одном классе. Он построен на основе PyTorch, совсем недавно, но я тестировал его, и я думаю, что пока он выполняет то, что обещает.
Он называется Tez, и сегодня мы увидим его в действии на забавной задаче классификации текста с несколькими ярлыками. Вот что мы расскажем:
- Использование библиотеки 🤗Datasets для загрузки данных и управления ими
- Определение процесса обучения с помощью Tez and Transformers
- Обучение облегченной модели SqueezeBert решению задачи классификации с несколькими метками и достижение +0,9 AUC по данным проверки и тестирования.
Давайте прямо сейчас!
PS *: Прежде чем продолжить это руководство, позвольте поблагодарить Abhishek Thakur, который приложил усилия и энергию для создания Tez и обеспечения доступа к глубокому обучению для более широкого сообщества.
PS **: весь код, а также обученная модель доступны в моем репозитории на Github.
Создание необычного классификатора настроений на GoEmotion 🧱
Вы, вероятно, знакомы с построением моделей анализа настроений, основанных на двоичных (например, обзоры фильмов IMDB) или мультиклассовых данных (например, обзоры продуктов Amazon).
Сегодня мы по-прежнему сосредоточимся на анализе настроений, но сделаем кое-что другое.
При поиске набора данных на веб-сайте Huggingface я наткнулся на интересный сайт под названием GoEmotions: он содержит 58 тысяч тщательно отобранных комментариев Reddit, разбитых на 28 категорий, включая нейтральные.
Данные представлены на английском языке и предназначены для классификации по нескольким категориям с интересными категориями, отражающими поведение людей в социальных сетях. Мне пришлось попробовать этот набор данных!
Вот 28 разных эмоций:
[‘admiration’, ‘amusement’, ‘anger’, ‘annoyance’, ‘approval’, ‘caring’, ‘confusion’, ‘curiosity’, ‘desire’, ‘disappointment’, ‘disapproval’, ‘disgust’, ‘embarrassment’, ‘excitement’, ‘fear’, ‘gratitude’, ‘grief’, ‘joy’, ‘love’, ‘nervousness’, ‘optimism’, ‘pride’, ‘realization’, ‘relief’, ‘remorse’, ‘sadness’, ‘surprise’, ‘neutral’]
Я нахожу этот набор данных интересным, потому что он предоставляет размеченные данные о подробных эмоциях, таких как любопытство, благодарность или удивление, эмоции, которые довольно трудно обнаружить с помощью типичных наборов данных.
Я также считаю, что такой набор данных имеет большое значение. Развертывание модели, которая классифицирует текстовые данные по этим эмоциям, может иметь несколько приложений:
- Оценка поведения клиентов посредством детального анализа их отзывов
- Выявление ядовитых комментариев или языка вражды в социальных сетях
- Создание агента для оценки тона ваших писем (электронных писем, отчетов, сообщений в блогах)
- Обогащение наборов данных метаданными: например, вы можете использовать эту модель для дополнения синопсиса фильма тегами после его анализа с помощью модели.
И список продолжается. Расскажите в комментариях, какие еще приложения вы можете придумать.
1 - Настройте свою среду 💻
Чтобы воспроизвести это руководство, вам понадобится рабочая установка python 3. Я бы выбрал Anaconda, но вы можете использовать любой менеджер пакетов, какой захотите.
Затем вам нужно будет установить:
- PyTorch (желательно последняя версия)
- 🤗трансформаторы: библиотека, которая предоставляет тысячи предварительно обученных моделей для выполнения таких задач с текстами, как классификация, перевод, генерация текста на более чем 100 языках.
- 🤗Datasets: легкая библиотека, предоставляющая однострочные загрузчики данных и предварительную обработку для многих общедоступных наборов данных (включая GoEmotions).
- Tez: супер-простой и легкий трейнер для PyTorch
Вам также понадобятся scikit-learn и pandas для обычной обработки и обработки данных.
Вы должны быть готовы: давайте начнем код!
Сначала тот же старый импорт:
2 - Получить данные из 🤗Datasets
Данные могут быть легко извлечены из библиотеки 🤗Datasets, извлечены в поезде, проверке и тестовом разбиении и преобразованы в фреймы данных pandas.
Вот краткий обзор данных: каждый комментарий имеет список соответствующих идентификаторов, которые соответствуют одной из 28 эмоций.
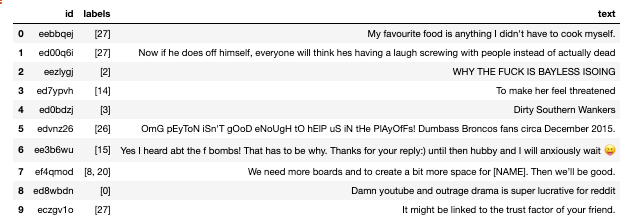
Преобразуя каждую метку в исходное значение, мы можем получить более полное представление.

Чтобы правильно передать данные в классификатор, нам нужно преобразовать метки в горячие векторы.
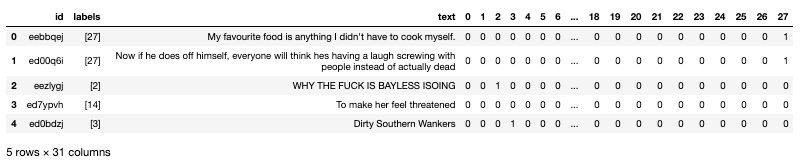
Быстрый взгляд на распределение целей между обучением, проверкой и тестированием показывает, что оно следует той же схеме. (идентификатор 27 соответствует нейтральной эмоции, которая помечена в 30% данных)

Прежде чем приступить к обучению модели, давайте кратко рассмотрим некоторые обзоры, основанные на их эмоциях:
Восхищение
Wow, your posting history is a real... interesting ride. --- I've never heard the insult 'Galaxy-Brain' before, but it's a wonderful! I'm gonna have to use it more often. --- That or spot up shooting. I like the confidence though, he’s not scared to expand his game. --- Congratulations!! Colorado is an amazing place! I just moved away a year ago and miss it terribly :) Best of luck to you! --- Your artwork is amazing. ---
Развлечения
A stork bite your baby?!?! *kidding* --- I like how because it’s on topic you assume everyone involved is making it their entire being. Lmao. --- It's funny cause you say socialists have an "ignorance of economics" while posting on an anarcho-capitalist sub :) I think you clearly fundamentally misunderstand socialism. --- Oh hahaha, is it a reputable vendor? --- This just made my day! Thanks for the laugh!! ---
Гнев
[NAME], don't f**king front the pass if your help defender is [NAME] he will not help you --- I will kill you all --- How aren’t you in f**king school --- I hate betting unders. --- How dare you disrespect [NAME]. ---
Забота
Yes. One of her fingers is getting a sore on it and there’s concern it may push her into needing braces. --- Most important!!! ALWAYS AIM THE HEAD! [NAME] arrows are pretty fat woodsticks, so keep aiming on the head on long distance. Thats it --- special for you my dude :) --- you did drug her though, and assault her by undressing her and taking her photo. you committed multiple crimes. you need professional help. --- Sure, they can help nurse [NAME] back to health. ---
3 - Определите набор данных PyTorch 🗂
Это не изменится: вам все равно нужно будет определить, как ваши данные будут загружаться и предварительно обрабатываться.
Мы определим токенизатор внутри конструктора класса. Токенизатор будет вызываться каждый раз при обращении к выборке для преобразования текста в идентификаторы токенов и маски внимания.
Идентификаторы токенов и маски внимания позже будут переданы в модель для генерации прогнозов.
- Идентификаторы токенов - это индексы токенов: они представляют собой просто числовые представления токенов, составляющих последовательности, которые будут использоваться моделью в качестве входных данных.
- Маска внимания - это необязательный аргумент, используемый при группировании последовательностей вместе. Этот аргумент указывает модели, на какие токены следует обращать внимание, а на какие - нет.
Обратите внимание, что:
- Мы использовали SqueezeBertTokenizer, потому что модель, которую мы будем использовать, - это SqueezeBert (подробнее см. Ниже).
- Максимальная длина - 35, поскольку она соответствует максимальной длине комментариев.
4 - Где происходит волшебство: определите Модель ⚡️
При использовании Tez вам просто нужно будет определить свой код как класс, унаследованный от tez.Model.
Этот класс реализует специальные методы, которые вам придется перезаписать.
Заполнить каждый метод довольно просто. Давайте сделаем их по очереди:
Конструктор __init__ определит модель магистрали, которую мы будем использовать. Опробовав мощные, но очень большие модели, такие как bert-base-uncased и roberta-base, я решил выбрать SqueezeBERT, который был в 4,3 раза больше. быстрее, чем bert-base-uncased, с той же производительностью. Остальные параметры вполне стандартные: слой отсева, слой вывода с количеством классов и количеством шагов обучения.
- Что касается методов fetch_optimizer и fetch_scheduler, я использовал примеры, которые я нашел в репо. Не стесняйтесь попробовать другие настройки, если они вам не подходят
- потеря: поскольку мы имеем дело с классификацией с несколькими метками, мы будем использовать двоичную кросс-энтропию для каждого выходного нейрона. Это соответствует BCEWithLogitsLoss в PyTorch.
- monitor_metrics. Что касается показателей, мы могли бы вычислить оценку F1 или AUC для каждой цели отдельно, но, поскольку это приводит к отображению большого количества показателей, я просто выбрал микро AUC. Уловка здесь заключается в том, чтобы развернуть пакеты целей и выходов в одномерных векторах и вычислить AUC между ними. Поскольку цели независимы друг от друга, это имеет смысл.
- вперед: здесь мы определяем, как модель выполняет прямой проход для входных данных. Этот метод должен возвращать кортеж, состоящий из вывода, потерь и показателей.
5 - Начать обучение ⏱
Мы почти там! Теперь запустим обучение. Если вы знакомы с Keras API, это выглядит очень похоже: обучение модели является однострочным.
Tez также предоставляет обратные вызовы, которые позволяют вам добавлять некоторые функции во время обучения вашей модели. Мы воспользуемся двумя из них:
- TensorBoardLogger для регистрации метрик обучения и проверки в Tensorboard
- EarlyStopping для проверки лучшей модели и преждевременного прекращения обучения
БАМ! Всего за 2 эпохи модель достигла потрясающих результатов проверки 0,922 AUC.

После обучения на 8 эпохах модель достигла 0,97 AUC по данным поездов и 0,95 по данным проверки.
Давайте теперь посмотрим, какова оценка модели на тестовых данных, и оценим ее эффективность в каждом классе.

Удивительно, правда? Модель имеет +0,8 балла AUC во всех классах, кроме класса 21 (что соответствует гордости).
Протестируйте модель на произвольном тексте
Давайте протестируем модель на произвольном тексте. (Вы найдете реализацию score_sentence в моем репо)
score_sentence("i miss my friends")
#sadness 0.863369
#disappointment 0.20503707
#neutral 0.05794677
#remorse 0.02818036
#annoyance 0.023128381
score_sentence("i miss my friends")
#sadness 0.863369
#disappointment 0.20503707
#neutral 0.05794677
#remorse 0.02818036
#annoyance 0.023128381
score_sentence("you might have a point, but i strongly disagree with you")
#disapproval 0.77016926
#annoyance 0.11454596
#approval 0.08423975
#disappointment 0.04763091
#disgust 0.04497903
score_sentence("i'm feeling very confident about this situation")
#optimism 0.456496
#approval 0.43606034
#admiration 0.1233574
#caring 0.096342765
#realization 0.07383881
score_sentence("try to be safe my friend")
#caring 0.73572147
#optimism 0.0856328
#neutral 0.071999945
#sadness 0.06158314
#approval 0.038069934
Заключение и дальнейшая работа 🔜
В этом руководстве была возможность применить современную языковую модель под названием SqueezeBert к набору данных с несколькими метками, содержащим 50 тыс. Обзоров и 28 классов.
Использование Tez было очень эффективным для организации конвейера обучения при сохранении большой степени настройки. После нескольких строк кода обученная модель достигла потрясающей оценки AUC 0,95 на тестовых данных.
Но путешествие на этом не заканчивается: пришло время развернуть модель в Интернете, чтобы другие люди могли взаимодействовать с ней через конечную точку API: если вам интересна эта тема, вы можете взглянуть на one из моих предыдущих статей, в которых я развернул генеративную модель в бессерверной архитектуре с помощью AWS Lambda.
Спасибо за прочтение! Не стесняйтесь обращаться ко мне, если у вас есть вопросы.
Если вас интересует код, вы можете найти его в моем репо.
Если вам нравится Tez, вы можете проверить его и (пометить) здесь!