В мире высокоскоростных вычислений легко забыть о распределении ресурсов.
Модели на основе трансформеров очень мощные, но при этом очень ресурсоемкие. В связи с этим их обучение и развертывание могут возникнуть с трудностями. К счастью, без графического процессора нельзя не искать альтернативы — и, тем более, иногда они находят.

Привет! В этом посте мы (и это не королевские мы, но успех этих экспериментов был в немалой степени обусловлен помощью моего коллеги Риккардо, так что я не хочу изображать из себя единственного интеллектуала, стоящего за этим) сравним несколько моделей архитектуры для решения проблем распознавания именованных объектов (NER) и обсуждения их производительности. Как было предложено, одна из этих архитектур включает в себя компонент преобразователя, и хотя ее производительность, возможно, была лучшей, с учетом времени обучения и вывода, а также ее воздействия на окружающую среду, это может быть не лучшим вариантом.
Данные
Будем надеяться, что в реальном сценарии у нас сначала возникнет проблема, а затем мы соберем данные, необходимые для ее решения. Однако мы хотели изучить только несколько архитектур и вариантов использования больших языковых моделей (LLM), поэтому взяли некоторые данные под рукой. Это оказались данные списков вакансий из LinkedIn (см. предыдущую статью для справки). Мы использовали описание должности и данные о связанных с ней навыках.
Проблема (первоначальная)
Рассматривая отдельные навыки, такие как «гибкие методы», «коммуникация», «C++» и т. д., мы создали четыре категории: бизнес, программное обеспечение, технические и технологии*. Каждый навык был внесен в одну из этих четырех. Нашей задачей тогда было подготовить LLM, который усвоил бы эти навыки и правильно их обозначил.
*Если вам интересно, в чем разница между техническими и технологическими навыками, то технические навыки — это те навыки, которые связаны с технологиями, но не зависят от какой-либо конкретной технологии (например, объектно-ориентированное программирование), тогда как технологические навыки могут быть конкретными примерами, такими как программирование на Python. .
Модельные архитектуры
Мы использовали отличную библиотеку spaCy для настройки и обучения нескольких моделей. Документация немного сумбурна и иногда даже устарела (компонента StaticVectors.v2 нигде нет?), но дизайн настолько умен, что я аплодирую стоя каждый раз, когда загружаю пакет.
Модели в целом
Модели SpaCy настраиваются в одном файле .cfg. В нем перечислены компоненты конвейера обработки данных и его особенности/параметры. Для нашей задачи мы использовали двухкомпонентную установку: первый компонент передавал наши токены в векторы (tok2vec), второй компонент затем выполнял задачу NER на основе этих векторов. Компонент NER не изменился в ходе этих экспериментов и остался стандартной моделью SpaCy парсер на основе переходов. Однако мы экспериментировали с компонентом tok2vec. Он состоит из двух частей: встроенной и кодирующей. Короче говоря, часть внедрения присваивает каждому токену плотный непрерывный вектор. Затем, используя эти векторы, кодер вычисляет матрицу, в которой значения, связанные с токенами, основаны на их контексте. Подробнее об этом можно прочитать здесь.
Ниже приведен пример файла конфигурации. Раздел nlp определяет компоненты конвейера. В свою очередь, в разделе компонентов компоненты указывают свои подмодули. Наконец, для каждого подмодуля указаны и определены его тип и параметры:
[nlp]
lang = "en"
pipeline = ["tok2vec","ner"]
batch_size = 1000
tokenizer = {"@tokenizers":"spacy.Tokenizer.v1"}
[components]
[components.ner]
factory = "ner"
...
[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
state_type = "ner"
...
[components.ner.model.tok2vec]
@architectures = "spacy.Tok2VecListener.v1"
...
[components.tok2vec]
factory = "tok2vec"
...
Подробнее о файлах конфигурации можно прочитать здесь.
Базовая конфигурация
Для начала мы использовали модель SpaCy по умолчанию. Он использует встраивание, которое учитывает несколько лексических атрибутов, затем для кодирования использует свертки с активацией maxout.
Ниже приведен файл конфигурации частей встраивания и кодирования tok2vec.
[components.tok2vec.model.embed]
@architectures = "spacy.MultiHashEmbed.v2"
width = ${components.tok2vec.model.encode.width}
attrs = ["NORM","PREFIX","SUFFIX","SHAPE"]
rows = [5000,1000,2500,2500]
include_static_vectors = false
[components.tok2vec.model.encode]
@architectures = "spacy.MaxoutWindowEncoder.v2"
width = 96
depth = 4
window_size = 1
maxout_pieces = 3
HashEmbedCNN
По сути, это предыдущая архитектура с увеличенным размером окна, используемым для слоя внедрения, и дополнительным сверточным слоем с увеличенным по сравнению с обычным размером окна.
Отмечу только изменения в конфигурации:
[components.tok2vec.model.embed]
@architectures = "spacy.HashEmbedCNN.v2"
width = ${components.tok2vec.model.encode.width}
window_size = 2
[components.tok2vec.model.encode]
@architectures = "spacy.MaxoutWindowEncoder.v2"
width = 128
window_size = 1
Активация Mish
Опять же, мы основывались на предыдущем варианте (HashEmbedCNN), но вместо maxout мы использовали Функцию активации Mish.
Отмечая только изменения в конфигурация:
[components.tok2vec.model.encode] @architectures = "spacy.MishWindowEncoder.v2" window_size = 2
Кодер BiLSTM
В этом варианте мы добавили двунаправленный кодер с длинной краткосрочной памятью (BiLSTM) с двумя рекуррентными слоями после сверточной сети базовой конфигурации.
Отмечаем только изменения в конфигурация:
[components.tok2vec.model.encode] @architectures = "spacy.TorchBiLSTMEncoder.v1" depth = 2 dropout = 0.1
Модель трансформера
Наконец, мы использовали библиотеку spacy-transformers, чтобы использовать базовую модель RoBERTa из Трансформеров Hugging Face. Следует отметить, что модель-трансформер несколько более причудлива, чем базовая архитектура tok2vec, описанная выше. Трансформаторы создают контекстно-зависимые внедрения. Кроме того, выходные векторы кодера используются в качестве входных вместе с последовательными входными векторами. Для дальнейшего объяснения, пожалуйста, обратитесь к этой статье, процитированной до смерти.
Ниже представлена конфигурация tok2vec, теперь трансформера:
[components.transformer.model] @architectures = "spacy-transformers.TransformerModel.v3" name = "roberta-base" [components.transformer.model.get_spans] @span_getters = "spacy-transformers.strided_spans.v1" window = 128 stride = 96
Используя архитектуру преобразователя, также необходимо обновить подмодуль [components.ner.model.tok2vec], чтобы он стал TransformerListener, вместо Tok2VecListener по умолчанию.
Примечания по обучению и оценке
Из-за экспериментального характера проекта мы использовали только 20 706 входных предложений для обучения, 2 951 предложение для тестирования и максимально увеличили количество шагов обновления до 10 000. Также существовал набор данных из 1925 предложений, включающий в себя сущности, совершенно невидимые для модели.
В NER каждый объект в тексте идентифицируется своим позиционным индексом и меткой. Например, (17, 31, 'Technical') будет означать, что слово с индексом от 17 до 31 получило метку «Техническое» — и, следовательно, оно распознается как сущность. Для оценки spaCy просматривает позиции и метки каждого объекта в прогнозируемом наборе объектов и сравнивает их с позициями и метками основных истинных объектов. Идеальное совпадение с данным объектом считается истинным положительным результатом. Ложноположительные результаты — это те, которые входят в прогнозируемый набор, но отсутствуют в наборе основной истины. Аналогичным образом, ложноотрицательные результаты — это объекты, присутствующие в основном наборе истинности, но отсутствующие в прогнозируемом наборе.
Барабанная дробь
А теперь о результатах. Глядя на оценки F1 на тестовом наборе, мы видим, что модель кодера BiLSTM сравнительно хорошо справилась с моделью на основе трансформатора:
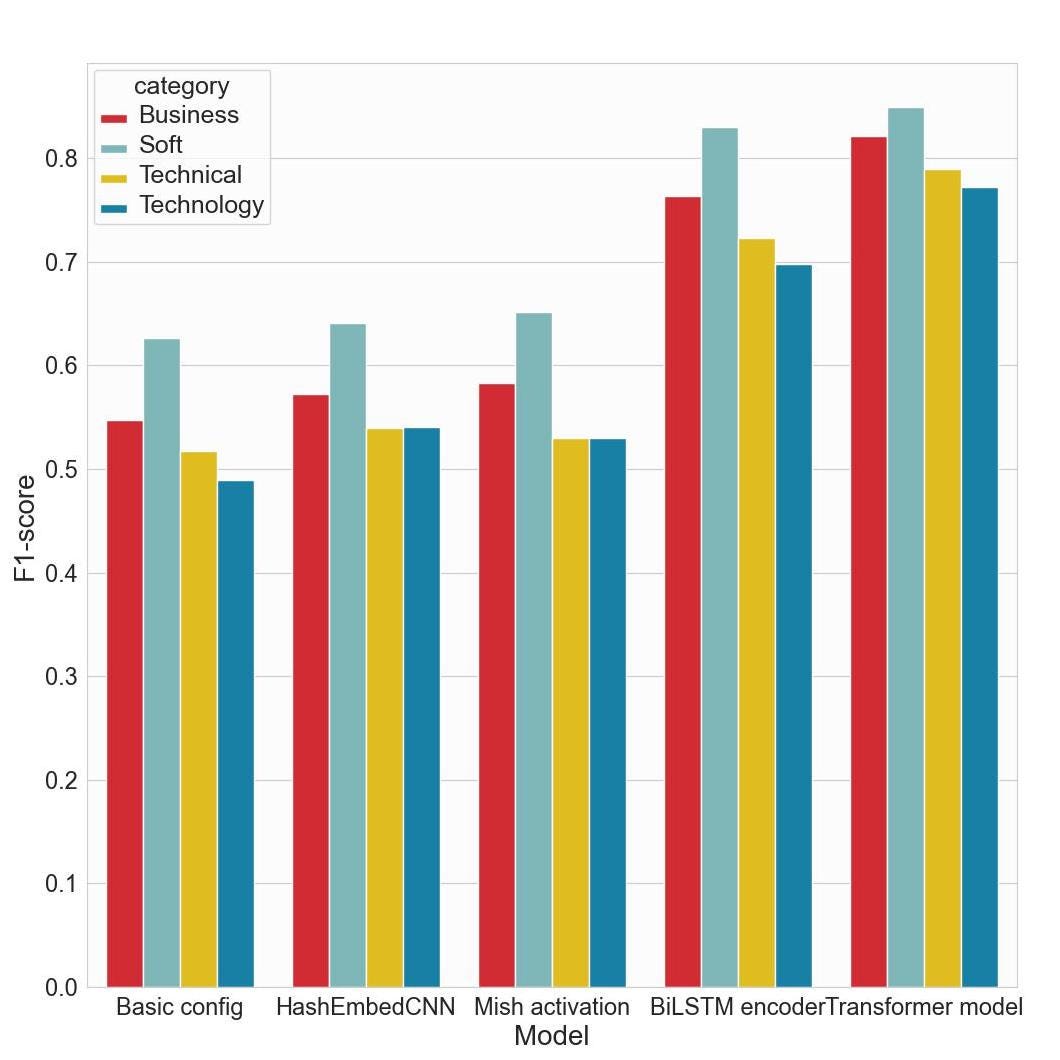
Однако по точности он даже превзошел его:

Более точно метриками оценки были:
- Модель кодера BiLSTM:
- точность: 83,47
- отзыв: 66,92
- f1: 74,28 - Модель трансформатора:
- точность: 82,88
- отзыв: 77,85
- f1: 80,29
Это означает, что хотя модель BiLSTM и не «выдает» столько меток, сколько ее аналог-трансформер, они попадают в нужные места. Было бы интересно побудить модель делать больше предположений, уменьшив штраф за ложноположительные метки.
Ресурсоёмкость
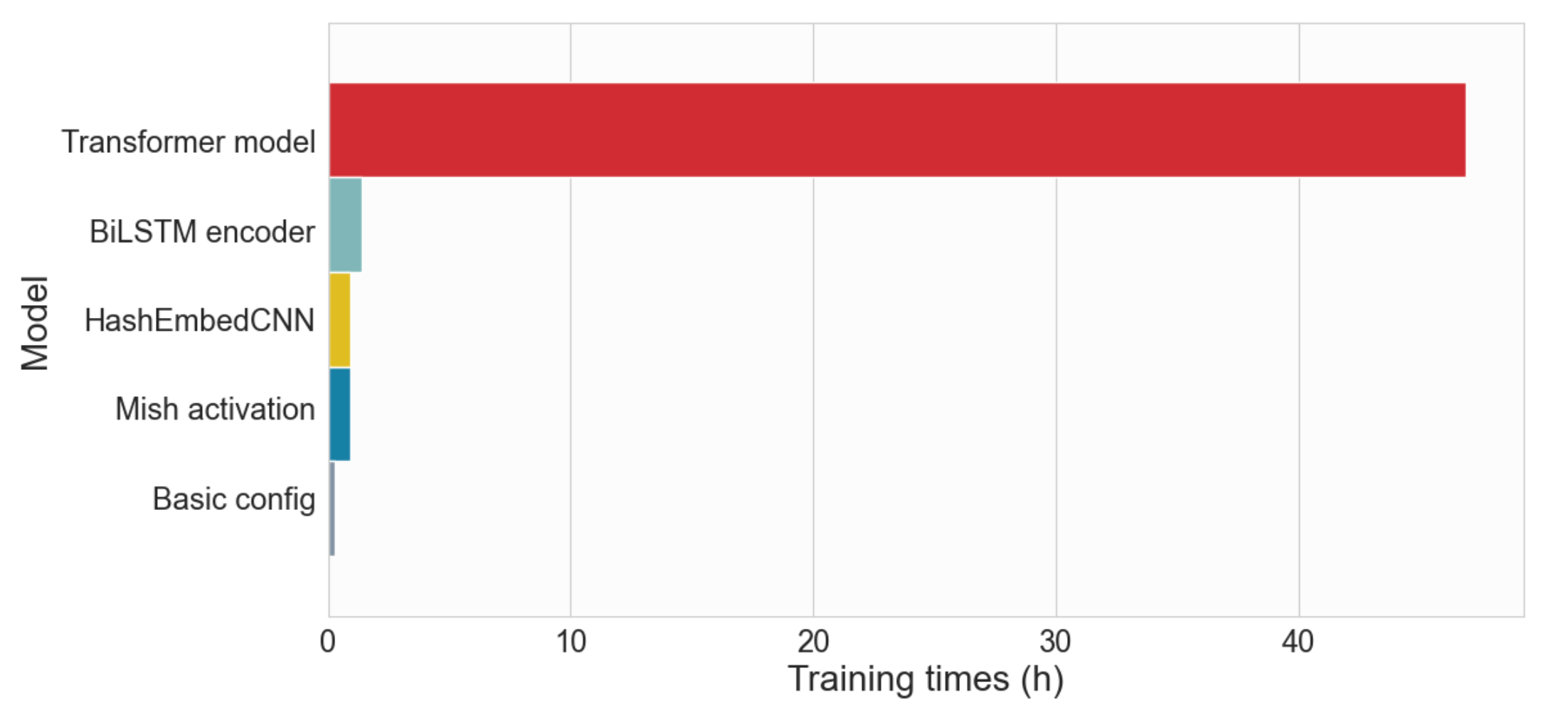
Однако в чем модель BiLSTM является настоящим победителем по сравнению с моделью трансформатора, так это во времени обучения и вывода. Как уже отмечалось, для экспериментов мы не использовали графические процессоры. Все вышеперечисленное было обучено на 15-дюймовом MacBook Pro 2017 года с использованием четырехъядерного процессора Intel Core i7 с тактовой частотой 2,8 ГГц. Имея это в виду, давайте посмотрим на время обучения для каждой модели.
- Время обучения:
- Базовая конфигурация: 16 минут 59 секунд
- HashEmbedCNN: 56 минут 12 секунд
- Активация Mish: 53 минуты 56 секунд
- Кодер BiLSTM: 1 час 24 минуты
- Модель трансформатора: 46 часов 56 минут
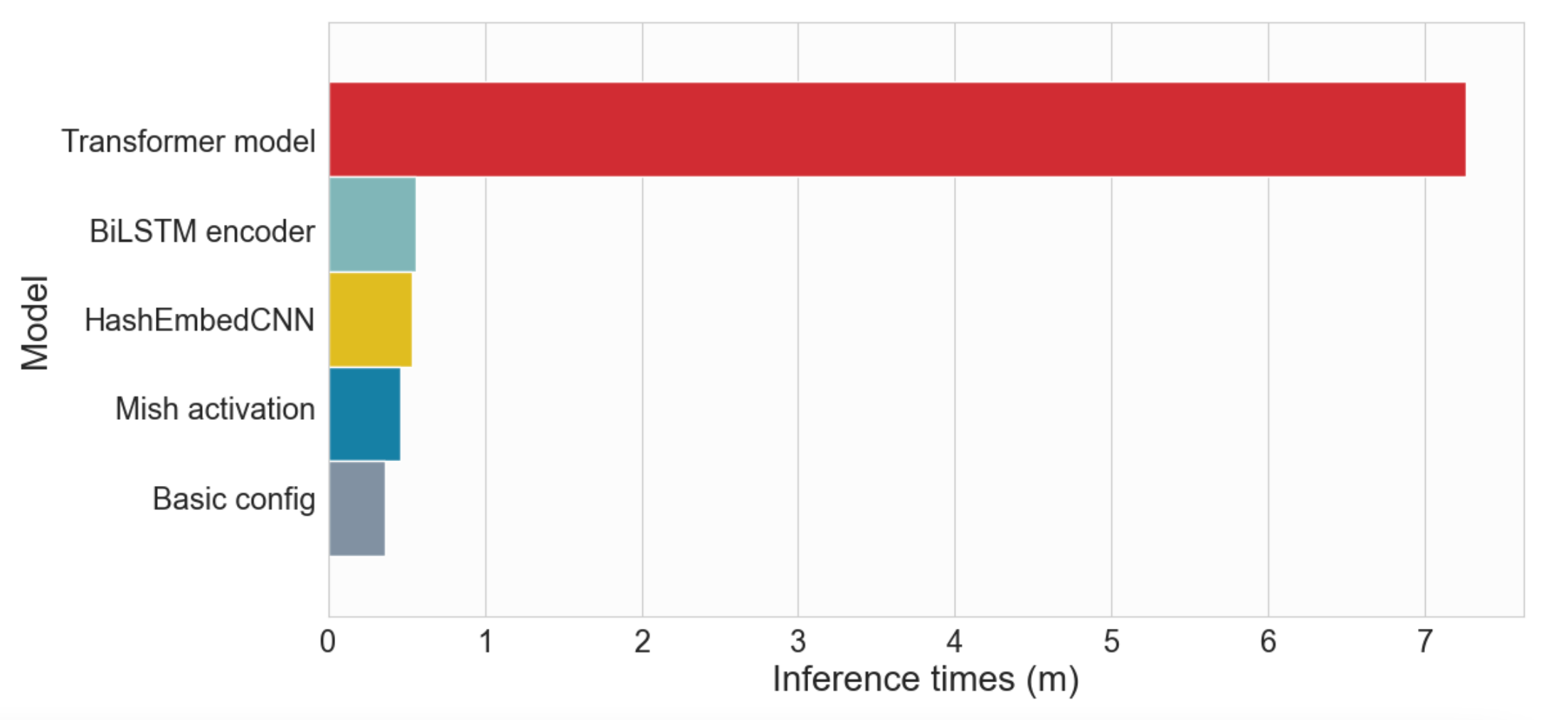
- Время вывода на тестовом наборе:
- Базовая конфигурация: 21,79 с
- HashEmbedCNN: 32,05 с
- Активация Mish: 27,70 с
- Кодер BiLSTM: 33,71 с
- Модель трансформера: 7м16с
Подожди, есть еще
Помните набор данных о несогласии? Смотреть прогнозы довольно интересно. Не претендуя на научную строгость, мы могли бы предположить, что разные архитектуры лучше подходят для обобщения разных типов навыков из-за того, как эти навыки контекстуализируются.

Хотя кодер BiLSTM превзошел другие модели, не являющиеся трансформерами, по всем аспектам тестового набора, он совершенно не заметил никаких деловых или мягких навыков (бизнес, похоже, является сложной категорией) в контрольном наборе. Тем не менее, она работает на удивление хорошо (по сравнению с другими моделями), когда дело доходит до маркировки навыков, связанных с технологиями. Для сравнения: из 31 уникального навыка, включенного в контрольную выборку, 12 были деловыми, 3 — программными, 10 — техническими и 6 — связанными с технологиями. Исходя из этого, также возможно, что кодировщику BiLSTM просто повезло, что он уловил одну из связанных с технологией проблем, которые часто встречались в наборе данных (и эта способность «привязываться» к определенным навыкам также может объяснить его большую эффективность). оценки точности). Для подтверждения/опровержения любой из этих гипотез потребуются дальнейшие эксперименты.
Заключительные замечания
Наконец, следует отметить, что характер этого проекта был весьма экспериментальным с целью намекнуть на общие особенности архитектуры моделей. Гораздо больше строгости потребуется, особенно на этапе очистки и форматирования данных, где удобство и скорость имеют приоритет, и поэтому некоторые объекты остаются без меток, а некоторые метки также отбрасываются. Надеюсь, в будущем мы сможем вернуться к этой проблеме и уделить ей внимание и заботу, которых она заслуживает.
А пока веселитесь!
Опять же, я хотел бы отдать должное моему коллеге Риккардо Скотту, который внес большой вклад в этот проект. Найдите его средний аккаунт здесь и его LinkedIn здесь.