
Нейронные сети на основе трансформаторов произвели революцию в области обработки естественного языка и компьютерного зрения благодаря своей бесспорно высокой производительности, но большинство современных моделей достигают миллиардов-триллионов параметров, поэтому это связано с высокими затратами с точки зрения вычисления и время для обучения модели.
Чтобы устранить эти ограничения, в новой статье Компонируемые расширения с сохранением функций для архитектур-трансформеров исследовательская группа из Google DeepMind и Университета Тулузы представляет преобразования расширения параметров для нейронных сетей на основе трансформаторов, сохраняя при этом функциональность, позволяя расширение возможностей модели по мере необходимости.

Команда резюмирует свой основной вклад: шесть компонуемых преобразований, сохраняющих функции для архитектуры на основе Transformer: 1) размер внутреннего представления MLP, 2) количество голов внимания, 3) размер выходного представления голов внимания, 4) размер входного внимания. представление, 5) размер представлений входных/выходных слоев преобразователя, 6) количество слоев.
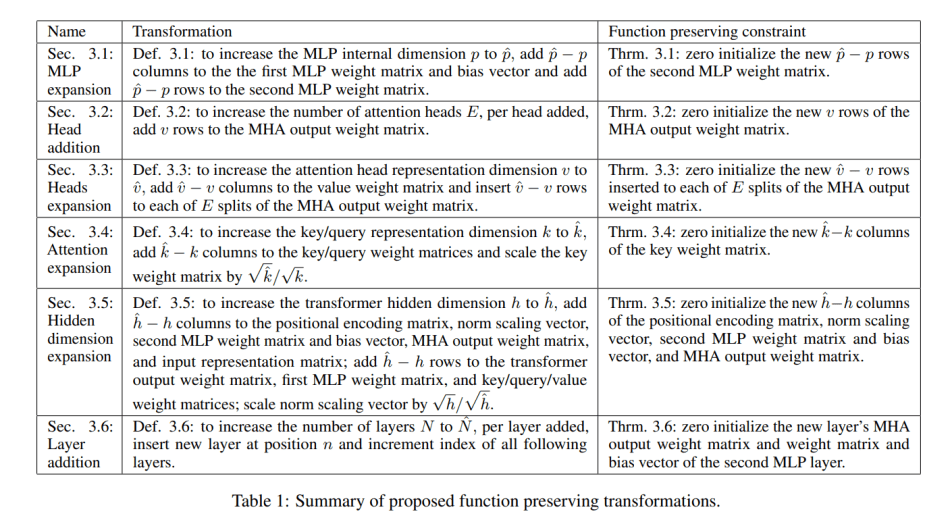
Расширение MLP применяется для расширения масштаба MLP за счет расширения размерности его внутреннего представления посредством преобразований матрицы параметров; Преобразование добавления головок используется для добавления произвольного числа новых головок в компонент MHA; Преобразование «Расширение голов» предназначено для расширения измерения представления, генерируемого головами внимания; Преобразование расширения внимания применяется для расширения пар ключей и представлений запроса, которые используются для создания матрицы весов внимания; Преобразование расширения скрытого измерения может расширить размерность представления, созданного слоями преобразователя. Преобразование добавления слоев используется для вставки нового уровня в архитектуру Transformer.
Для каждой функции, сохраняющей функцию, команда предоставляет доказательство точного сохранения функции при минимальных ограничениях инициализации. Они считают, что их работа позволяет более эффективно обучать более крупным и мощным моделям за счет постепенного расширения архитектуры.
Статья Компонируемые расширения с сохранением функций для архитектур-трансформеров на arXiv.
Автор: Геката Хе | Редактор: Чейн Чжан

Мы знаем, что вы не хотите пропустить ни одной новости или научного открытия. Подпишитесь на нашу популярную рассылку Synced Global AI Weekly, чтобы получать еженедельные обновления об искусственном интеллекте.