Точность, полнота, специфичность, прецизионность и оценка F1.
Предположим, авиакомпания владеет 100 самолетами и хочет проверить каждый из них, чтобы убедиться, что они безопасны для путешествий. Вам нужно предсказать, находится ли самолет в неисправном или в идеальном состоянии для путешествий. У вас есть 2 исхода. Поскольку у вас есть 2 результата, проблема становитсяпроблемой бинарной классификации. Для реализации этой классификации вам необходимо запустить контролируемый алгоритм машинного обучения. Вы выбрали алгоритм и запустили код.
Ну и что теперь?
Как узнать, дает ли этот алгоритм лучший результат? Как узнать, насколько точно этот конкретный алгоритм выполняет свою классификацию? Как вы это измеряете?
Не волнуйтесь, именно здесь в дело вступает Матрица Путаницы.
Что такое матрица неточностей?
Матрица путаницы — это, по сути, показатель производительности и оценщик алгоритма машинного обучения. Это визуальный способ прочитать результат вашей модели.
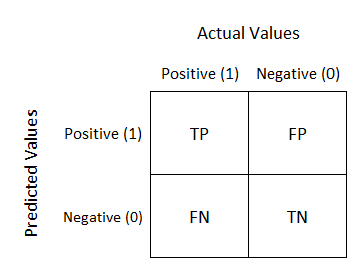
Он создает комбинации результатов постановки задачи, поскольку они являются возможными результатами алгоритма. Здесь, в сценарии двоичной классификации, как следует из рисунка выше, существует 4 комбинации. Давайте поймем это с точки зрения самолета.
Примечание:
Здесь я рассмотрел следующее:
Неисправность = ВЕРНО или ПОЛОЖИТЕЛЬНО
Идеальное состояние = ЛОЖНО или ОТРИЦАТЕЛЬНО
Возможные классификации:
- Настоящий положительный результат (TP):
Вы предсказали, что это правда, и это на самом деле правда.
Сценарий: Вы предсказали, что самолет неисправен, и он действительно неисправен.

2. Ложное срабатывание (FP):
Вы предсказали, что это правда, но это на самом деле ложь.
Сценарий:Вы предсказали, что самолет неисправен, но на самом деле он отлично функционирует.

3. Ложноотрицательный результат (FN):
Вы предсказывали, что это ложно, но это на самом деле правда.
Сценарий:Вы предсказали, что самолет будет работать идеально, но на самом деле он неисправен.

4. Истинно отрицательный результат (TN):
Вы предсказали, что это ложно, и это на самом деле неверно.
Сценарий:Вы предсказали, что самолет будет идеально функционировать, и на самом деле он работает идеально.

Нам требуется большое количество истинно положительных и истинно отрицательных результатов. Поскольку модель машинного обучения не может обеспечить 100 % точные результаты, она неизбежно дает ошибочные классификации, что приводит к ложноположительным результатам и ложноотрицательным результатам, как показано выше.
Теперь вернемся к ситуации с нашим самолетом. Давайте рассмотрим 100 самолетов, которые необходимо проверить. Из этих самолетов 70 неисправны, а 30 прекрасно работают. Нам нужна наша модель, чтобы классифицировать, какие самолеты готовы к взлету, а какие направляются к катастрофе в облаках.
Матрица путаницы будет выглядеть так:
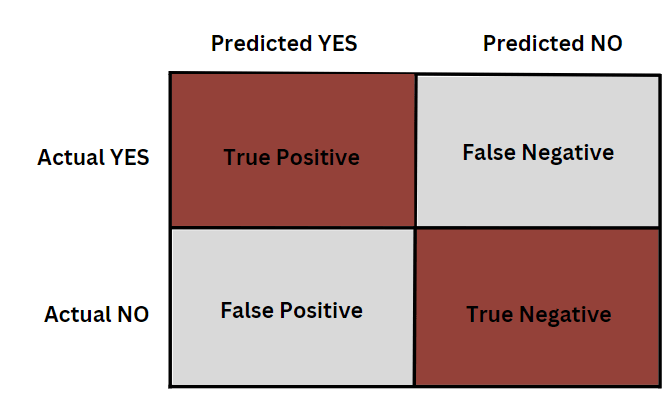
Учитывая наш сценарий с самолетом, наша матрица путаницы будет выглядеть следующим образом:

В нашем случае у авиастроительной компании 100 самолетов, из них 70 неисправны и 30 находятся в идеальном состоянии. Скажем, наша модель машинного обучения выполнила свою задачу классификации. Из 70 неисправных самолетов 55 правильно классифицированы как неисправные, но ошибочно классифицированы 15 как исправные. Аналогичным образом, из 30 идеально работающих самолетов 25 были правильно классифицированы как идеальные, а 5 ошибочно классифицированы как неисправные.
Следовательно, наши TP = 55, FP = 5, TN = 25, FN = 15. Давайте визуализируем это в матрице путаницы:

Показатели:
1. Точность: как часто классификатор верен?
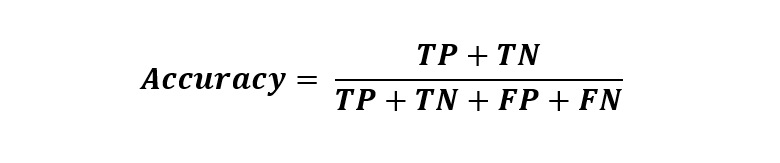
Точность представляет собой общее количество правильных классификаций по общему количеству экземпляров.
Здесь ( 55 + 25 ) / ( 25 + 15 + 55 + 5)
= 80/100
= 80%
Насколько надежна точность?
Точность не дает точных результатов, если набор данных несбалансирован. Рассмотрим тот же сценарий, но предположим, что классификатор классифицировал все 70 неисправных самолетов как неисправные. Однако все 30 идеальных самолетов были классифицированы как неисправные. Это дало бы нам высокую точность модели, но имеет расхождение в результатах. Это также может нанести ущерб бизнесу. Поскольку 30 из идеальных самолетов были классифицированы как неисправные, компании пришлось выделить дополнительное время и ресурсы для проверки еще 30 самолетов. Это может привести к денежным потерям компании. Следовательно, точность не всегда обеспечивает наилучшие результаты.
2. Припоминаемость/Чувствительность/Истинно положительный уровень: Если на самом деле ДА, как часто классификатор прогнозирует ДА?

Напоминание, также называемое Чувствительность, представляет собой долю прогнозируемых правильных истинных положительных результатов по отношению к общему количеству фактических положительных результатов, независимо от его прогноза. Это метрика, которая оценивает способность модели предсказывать истинные положительные результаты из фактических положительных.
Здесь Напомнить = 55 / ( 55 + 15 )
= 55 / 70
= 0.785
В идеале Показатель запоминания должен быть близок к 1, чтобы можно было предположить, что классификатор является хорошей моделью. Это означает, что количество положительных экземпляров, предсказанное классификатором, должно быть почти равным общему количеству фактических положительных экземпляров. Ложноотрицательные результаты также должны быть низкими, чтобы получить долю от 1. Оценка 0,785 означает, что классификатор спрогнозировал 78,5 процентов действительно неисправных самолетов как неисправные. Оставшиеся 21,5 процента были предсказаны как идеальные.
3. Специфичность/истинно отрицательный уровень:

Специфичность – это показатель, который оценивает способность модели предсказывать истинные отрицательные результаты из предсказанных отрицательных результатов.
Здесь 25 / ( 5 + 25 )
= 25 / 30
= 0.83
Оценка 0,83 предполагает, что модель может хорошо прогнозировать.
4. Точность. Когда он предсказывает ДА, как часто он оказывается верным?
Точность – это, по сути, доля фактических истинных положительных результатов по отношению к прогнозируемым положительным, независимо от их истинного значения. Он измеряет степень правильной классификации модели правильного положительного экземпляра среди всех ее положительных предсказанных экземпляров.

Здесь Точность = 55 / (55 + 5).
= 55 / 60
= 0.916
Точность становится высокой только тогда, когда количество ложных срабатываний приближается к 0. Здесь мы можем сделать вывод, что наша модель правильно классифицировала большинство положительных случаев благодаря своему высокому баллу 0,916. Это говорит о том, что модель правильно предсказала, что 91,6% из всех неработающих экземпляров классификации оказались неисправными. Остальные 8,4 процента были ошибочно предсказаны как идеальные.
Как и во многих концепциях в области науки о данных, существует компромисс между отзывом и точностью. Чем больше мы увеличиваем один показатель, тем меньше будет другой. Иногда, в зависимости от сценария, нам хотелось бы максимизировать либо полноту, либо точность за счет другого показателя. Мы предпочли бы правильно определить количество неисправных самолетов (Высокая полнота), чем точно определить количество идеальных самолетов (Высокая точность). Стоимость человеческой жизни важнее ресурсов компании. Поэтому, когда мы хотим найти оптимальное сочетание высокой точности и высокой полноты, мы можем объединить эти два показателя, используя показатель F1.
5. Оценка F1
Оценка F1 представляет собой среднее гармоническое значение точности и полноты, учитывающее оба показателя в следующем уравнении:
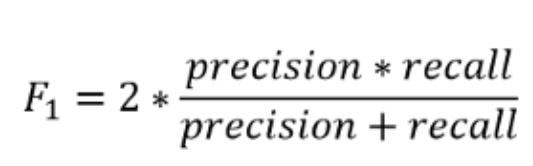
Гармоническое среднее поощряет аналогичные значения точности и полноты. То есть, чем больше показатели точности и полноты отклоняются друг от друга, тем хуже среднее гармоническое. Если мы хотим создать модель классификации с оптимальным балансом точности и полноты, мы пытаемся максимизировать оценку F1.
В сценарии с самолетом оценка F1 равна 2*(0,916*0,785)/(0,916+0,785) = 0,845.
Более глубокое и математическое объяснение результатов Формулы-1 будет рассмотрено в последующих блогах.
Я надеюсь, что, по крайней мере, ваше замешательство по поводу Матрицы Путаницы теперь прояснилось! Если вам понравился этот пост, вам будет полезно немного похлопать его в ладоши 👏. Я всегда открыт для ваших вопросов и предложений.
Вы можете связаться со мной по адресу:
LinkedIn: www.linkedin.com/in/vmadhuuu
Гитхаб: https://github.com/vmadhuuu
Спасибо за чтение!