Группа визуальной геометрии в Оксфордском университете использовала финансированиеEPSRC (Совет по инженерным и физическим исследованиям) для создания прототипа компьютерного зрения для Sotera. Прототип был ориентирован на конкретный вариант использования в рамках более широкой деятельности Sotera: можем ли мы использовать фотографию объекта, чтобы распознать его на предыдущих изображениях?
Набор инструментов наследия Sotera позволит людям фотографировать объекты наследия, находящиеся под угрозой. Если они будут найдены позже или появятся в сети, мы сможем распознать их по новой фотографии. Это требует, чтобы компьютерное зрение могло распознавать объект, о котором оно узнало из старой фотографии, когда оно видит новую фотографию объекта, которая может сильно отличаться. Это также должно работать с плохо сделанными фотографиями, а не только с высоким разрешением и хорошо освещенными изображениями.
Для этого проекта мы сотрудничали с Восточным музеем в Даремском университете, который поделился своим оцифрованным набором данных коллекции, включающим около 40 000 экспонатов в музее. Он состоял из фотографий в папках и текстового файла с подробной информацией о каждом объекте, который был создан для архивных и кураторских целей. Оксфорд поставил перед нами задачу предоставить им чистые данные — это оказалось одной из самых больших проблем для проектов Computer Vision, которая привела к тому, что команда Sotera многое узнала о наборах данных.
В этом посте мы делимся некоторыми из того, что мы узнали. Это полезный пример для других организаций, работающих с большими наборами данных, в частности для других организаций, занимающихся вопросами наследия, оцифровывающих свои коллекции.
Восточный музей открылся в 1960 году. Их коллекция варьируется от Древнего Египта до современного Китая. Это единственный музей на севере Англии, полностью посвященный искусству и археологии великих культур Северной Африки и Азии. Коллекция состоит примерно из 40 000 предметов от доисторических времен до наших дней. Полученный нами набор данных состоит из изображений 26 418 объектов, которые мы сократили до окончательного набора данных из 12 401 объекта, наиболее подходящего для подтверждения концепции Sotera.
У музея не было записей метаданных, которые мы могли бы использовать, поэтому мы создали новую запись метаданных из их онлайн-систем, преимущественно из Откройте для себя», которая подается через API (не общедоступный), который извлекает объекты из «Adlib (их программное обеспечение для управления музейными коллекциями).
Что нам было нужно для этого проекта, так это непротиворечивые данные для каждого объекта. Онлайн-системы предоставили больше, чем нам было нужно, поэтому мы решили оставить большую часть данных в системе на случай, если они понадобятся для будущих проектов. Как правило, у каждого файла был инвентарный номер, который был тем же именем файла для связанных изображений. Далее следовали название предмета, дата создания, описание, размеры, материал, место производства, изображенные люди, тематика, изображения (при необходимости) и примечания. Когда наборы данных формируются в течение многих десятилетий, информация часто не вводится последовательно или в одном и том же порядке. Мы написали код, чтобы исправить это, а также удалить данные, которые могут запутать машинное обучение, такие как заметки куратора в свободной форме.
Очистка метаданных — используемые решения
Номера объектов
Мы извлекли номера экспонатов Восточного музея из каталога музейных экспонатов путем поиска в HTML-коде страниц Discover и IIF (International Image Interoperability Format), который идентифицировал 26 418 экспонатов. Мы использовали номера элементов для доступа к страницам IIIF и Discover для элемента, что было возможно, поскольку их URL-адреса содержали номера элементов. Мы использовали страницу IIF для извлечения изображений с высоким разрешением, а затем извлекли информацию об элементе со страницы «Обнаружение». Все объекты должны иметь одинаковые номера элементов или постоянные идентификаторы (PID). Большинство PID имеют уникальный идентификатор, который связан с текущим адресом метаданных. В отличие от URL-адресов, идентификаторы PID позволяют обновлять местоположение объекта, чтобы идентификатор постоянно указывал на нужное место без нарушения.
Имя объекта
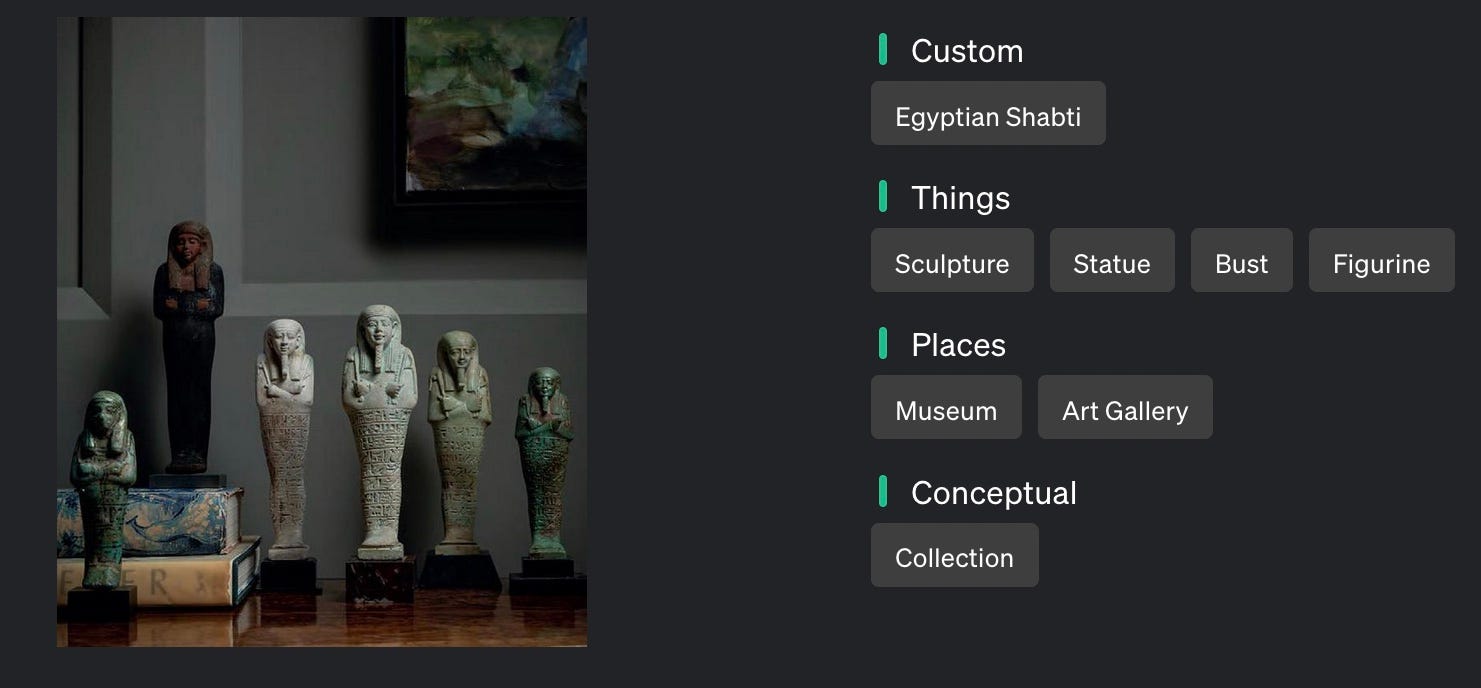
Соглашения об именовании объектов не были согласованы, поэтому мы написали сценарий, чтобы изменить это в наборе данных, ссылаясь на электронную таблицу с номерами/именами объектов, созданную руководителем отдела данных музея. В рамках этой конвенции оставались и другие несоответствия. Мы запустили несколько скриптов, чтобы исправить это, например. Шабти также назывались Статуэтки или Ушабти, и нам нужно было выбрать одно имя для одних и тех же предметов.
Мы устранили проблемы с форматированием, возникавшие во время извлечения данных, например, было добавлено «uc», а первая буква имени, которая сейчас находится в скобках, удалена. Мы также запустили скрипт для удаления информации о материалах в круглых скобках, когда она повторяется в столбцах описания и материалов, например. строка 7: «Человеческая фигурка (бронза) uc(i)sis и uc(h)orus figurine» была преобразована в: «isis and horus figurine».
Дата создания
Многие предметы из Древнего Египта были датированы только династическим периодом. Мы обновили древнеегипетские даты, чтобы использовать хронологию стандартизированных датировок Метрополитен-музея, и добавили годы в дополнение к названиям периодов династии для согласованного форматирования с другими периодами времени.
Описание
Мы обсуждали запуск скрипта для очистки повторяющихся описаний типологии общих объектов, однако решили, что для более долгосрочных целей предпочтительнее иметь больше информации, поэтому оставили эту информацию.
Размеры
Мы обсудили очистку перечисленных размеров, чтобы просто использовать самый большой размер для общего представления о масштабе объекта, однако мы решили, что для будущих расширенных параметров машинного обучения предпочтительнее иметь больше информации, поэтому мы сохранили все данные измерений, но теперь работали над тем, чтобы привести их в соответствие с нашими целями.
Материалы
Мы определили предпочтительные определения и типологии материалов, например. мы использовали термин керамика (археологический термин) вместо керамики (музейный термин) и шабти вместо ушабти. Мы обсудили сокращение списков материалов до последнего материала в списке, однако снова решили сохранить все описания для дальнейшего использования. например: «материалы — неорганический материал — порода — осадочная порода — карбонатная порода — известняк» можно было бы сократить до «известняк».
Например, некоторые материалы были перепутаны с цветом, который они представляют; гранит, золото, алебастр и бирюза — все это и материал, и цвет. Мы запустили скрипт для удаления ссылок на «цвета»: например: «материалы — цвет — цвета — хроматические цвета — фиолетовые цвета — переменные фиолетовые цвета — гранит» были заменены просто на «гранит».
Место производства
Мы сохранили длинные описания мест производства, которые идут от географического региона к конкретному местоположению, а не сокращали до одного дескриптора, чтобы сохранить данные для будущего использования. Например. «Азия — Западная Азия — Ирак — мухафаза Ди-Кар — район Нассрия — Талль-эль-Мукайир».
Период производства
Мы убрали правила датирования, чтобы сопоставить «Дату создания» с альтернативным «Периодом производства», поэтому у нас была только одна дата для каждого объекта, потому что у некоторых объектов были обе даты, что могло привести к путанице. алгоритм машинного обучения.
Изображения
Многие из записей объектов имели пробел в столбце изображений, что могло указывать на то, что их не фотографировали. Тем не менее, мы провели перекрестную проверку с электронными таблицами, подготовленными руководителем отдела данных Восточного музея, чтобы подтвердить номер объекта, пути к файлам изображений и эскизы изображений, чтобы найти отсутствующие изображения, и смогли найти или создать пути к отсутствующим файлам изображений, где это возможно.
Мы исключили объекты, не относящиеся к этому проекту, включая 2D-объекты, такие как бумага и фотографии. Мы запустили скрипт для удаления записей, сделанных из неактуальных материалов: «материалы — изделия из волокна — бумага»; «материалы — волокнистые изделия — бумага — фотобумага».
Окончательная очистка была выполнена вручную, так как было определено, что это более эффективно, чем написание сценария. Для этого мы вручную создали оставшиеся недостающие 178 «имен объектов».
Резюме
Коллекция Музея Востока была создана для демонстрации ряда различных пожертвованных коллекций, охватывающих большую территорию от Северной Африки до Юго-Восточной Азии. Преобладающей целью музея является академическое исследование и обучение восточным языкам. Таким образом, многие соглашения об именах основаны на стандартах языка и наследия, а не на археологических стандартах. Как это часто бывает с традиционными академическими музейными коллекциями, ввод данных в базу данных происходит в течение многих лет, и результирующая база данных часто представляет собой сложную стратиграфию данных, которая развивалась благодаря различным кураторам и соглашениям о вводе данных.
На нашем пути к созданию последовательной записи метаданных для коллекции Восточного музея мы узнали, что описание объекта, происхождение и дата создания являются наивысшим приоритетом для академических и исторических целей, часто называемых в музеях «данными надгробий», используемыми для создавать этикетки объектов для выставки. Однако для набора данных машинного обучения идеальна согласованная ссылка на идентификатор объекта или постоянный идентификатор (PID), материал и размеры с соответствующими изображениями объекта. Если они включены, эти изображения должны иметь пути к файлам изображений и миниатюры, соответствующие записям.
У большинства объектов в коллекции отсутствовали фотофиксации (около 65%). Около 24 000 объектов мы исключили из окончательных метаданных, так как у них отсутствовали соответствующие изображения, необходимые для наших целей.
Результат
Проведенная нами работа по преобразованию набора данных Восточного музея из набора данных музея в набор данных машинного обучения сделала возможным проект компьютерного зрения, но также предоставила пример для других в секторе наследия. использовать при решении схожих задач при разработке наборов коллекций и цифровых гуманитарных проектах.
Для Sotera проект также дал ценные коммерческие уроки того, как мы будем обращаться с данными и управлять ими в будущем, и показал, что мы можем использовать Computer Vision для идентификации украденных объектов в секторах страхования и наследия.
Полученный в результате прототип Computer Vision, созданный Visual Geometry Group, имел успех, и вы можете подробнее прочитать об этом здесь.
Следующие шаги
Sotera — это стартап Insurtech, который использует компьютерное зрение и машинное обучение, чтобы точно понять, что представляют собой объекты, чтобы более точно оценить их риск. У нас также есть некоммерческий пакет Heritage Toolkit, который будет использовать нашу технологию для записи объектов наследия, находящихся под угрозой. Если вы управляете музеем с цифровым набором данных, мы хотели бы работать с вами. Пожалуйста, свяжитесь с нами.