Вы когда-нибудь задумывались, как развивалась область обработки естественного языка? Вы находитесь в нужном месте. Это первый блог из серии блогов, в которых описываются различные концепции НЛП и развитие этой области.
Сегодня мир вокруг нас управляется искусственным интеллектом. Мы часто слышим это, но почему мы так говорим? Что ж, мы живем в эпоху, когда компьютеры очень мощные, Интернет очень быстрый, программное обеспечение с открытым исходным кодом (в основном) и, что наиболее важно, когда миллиарды людей генерируют данные, которые можно использовать для получения очень осязаемых идей, которые могут быть очень прибыльными для бизнеса и имеют право улучшить образ жизни человека и дать ощущение роскоши. Но как? Моя цель — объяснить это в паре историй с несколькими фрагментами линейного кода, в которых каждый может попробовать и убедить себя.
Перед погружением давайте попробуем понять несколько важных терминов, которые вы часто слышите. (PS: Я пытаюсь написать серию рассказов, это первый.)
Что такое искусственный интеллект? Прежде чем я отвечу на это, я должен сказать вам, что означает интеллект: «Способность обрабатывать информацию для принятия обоснованных/будущих решений называется интеллектом». И поэтому искусственный интеллект, простыми словами, означает «построение алгоритмов, которые могут обрабатывать информацию для принятия решений». Поэтому мы стремимся искусственно создать этот интеллект в компьютерах. но как мы это делаем? Этого можно достичь с помощью мощных компьютеров, огромных объемов данных и современных алгоритмов/моделей для обработки данных. Благодаря техническому прогрессу мы ежедневно генерируем огромное количество данных, например. когда вы загружаете изображение в свою учетную запись в социальной сети, вы создаете данные изображения, которые будут использоваться для классификации изображений, когда вы заказываете онлайн на Amazon или любой другой онлайн-платформе, вы создаете данные, связанные с вашим выбором, и помогаете рекомендательным системам обучать модель лучше, чтобы в следующий раз, когда вы зайдете на amazon, он показывал рекомендации для похожих товаров.
Машинное обучение: это подмножество искусственного интеллекта. В этом подклассе ИИ мы обучаем алгоритм делать это без явного программирования машины для этого.
Представьте себе случай с вашей электронной почтой. Вы часто получаете электронные письма от спамеров, которые вы удаляете (иногда нажатие на спам-письма может быть очень опасным). Эти электронные письма содержат такие тексты, как «Вознаграждение», «Деньги», «Имущество», «Бесплатно» и т. д., чтобы заставить щелкнуть ссылки, отправить детали и т. д. Чтобы отфильтровать подобные спам-письма, мы должны следовать:
(1) алгоритм должен будет идентифицировать упомянутые слова и фразы,
(2) напишите алгоритм, чтобы пометить электронное письмо как спам или ветчину, используя имеющееся у вас электронное письмо (для успешного выполнения этого потребуется несколько цепочек if и else)
(3) Протестируйте новые электронные письма и спрогнозируйте точность спам-фильтра.
Но проблема возникает, когда спамер медленно узнает об алгоритме путем обратного проектирования и начинает использовать альтернативные или разные слова в электронной почте. Теперь необходимо соответствующим образом отредактировать спам-фильтр. И это становится бесконечным процессом. Следовательно, есть четвертый шаг,
(4) т.е. непрерывно повторять шаги 1, 2 и 3.
Здесь машинное обучение играет важную роль. Можно построить модель машинного обучения, используя старую электронную почту, помеченную как СПАМ или HAM (не спам), и соответствующим образом классифицировать новые электронные письма. Модель машинного обучения изучает функции, слова, текст из набора электронных писем. Кроме того, любые изменения в спам-сообщениях (отраженные спамером для обхода фильтра) могут быть автоматически выбраны спам-фильтром ML, и, следовательно, вмешательство программиста не потребуется.
В приведенном ниже коде показано, как мы можем классифицировать электронную почту, используя простой код Python:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
from nltk.corpus import stopwords
import string
# Load the dataset
data = pd.read_csv('spam.csv')
# Remove punctuation and stop words from the 'Email' column
def preprocess_text(text):
no_punct = "".join([c for c in text if c not in string.punctuation])
words = no_punct.split()
no_stop_words = " ".join([word for word in words if word not in stopwords.words('english')])
return no_stop_words
data['Email'] = data['Email'].apply(lambda x: preprocess_text(x))
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(data['Email'], data['Label'], test_size=0.2, random_state=42)
# Vectorize the 'Email' column
vectorizer = CountVectorizer()
X_train_transformed = vectorizer.fit_transform(X_train)
X_test_transformed = vectorizer.transform(X_test)
# Train a Naive Bayes classifier
nb = MultinomialNB()
nb.fit(X_train_transformed, y_train)
# Predict on the test set
predictions = nb.predict(X_test_transformed)
# Evaluate the model
print("Accuracy:", metrics.accuracy_score(y_test, predictions))
# Now you can use the trained model to classify new emails
new_email = ["Your new email content here"]
new_email_transformed = vectorizer.transform(new_email)
new_email_prediction = nb.predict(new_email_transformed)
print("New email is", "spam" if new_email_prediction else "ham")
Если вы не понимаете этот код, вы можете обратиться к подробному объяснению и попробовать сами пример набора данных в следующем блоге.
Забавные факты:
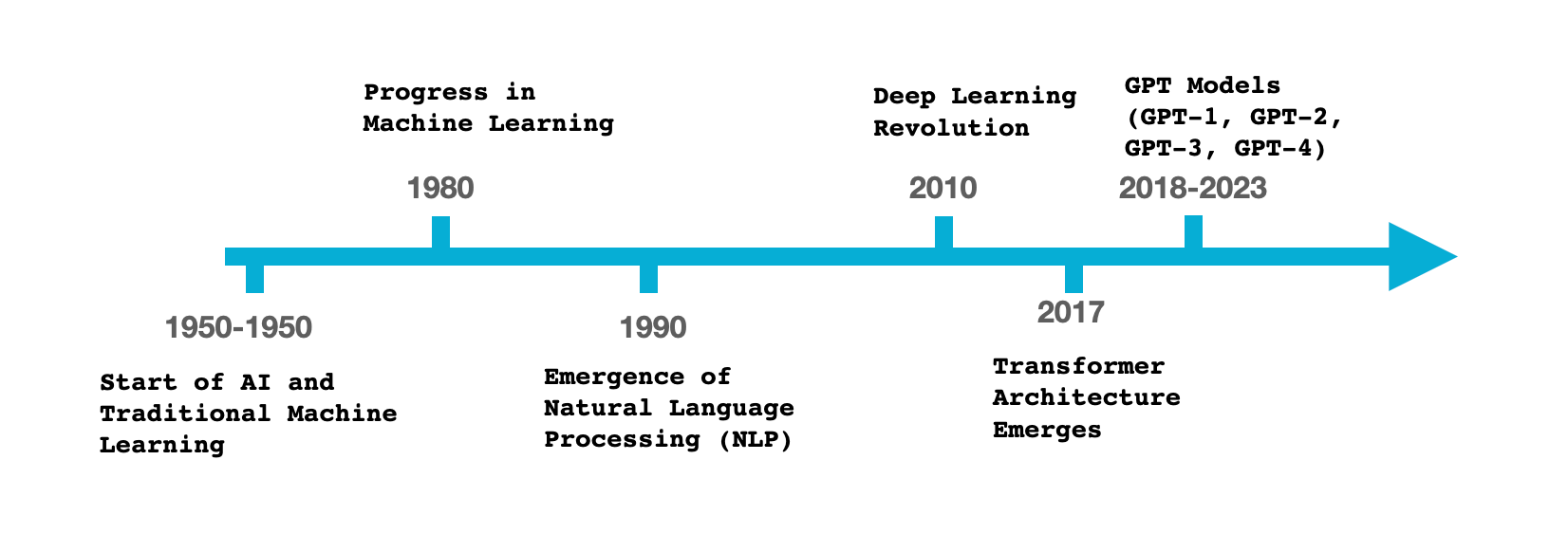
Искусственный интеллект (ИИ) уходит своими корнями в 1950-е годы. Область ИИ была официально рождена и названа на Дартмутской конференции в 1956 году, где группа исследователей, включая Аллена Ньюэлла, Герберта А. Саймона, Джона Маккарти, Марвина Мински и Артура Сэмюэля, собралась, чтобы обсудить возможность создания машин, которые может имитировать человеческий интеллект. Некоторые из ключевых документов и примеров, которые сыграли решающую роль в эту эпоху, включают:
- «Вычислительные машины и интеллект» Алана Тьюринга (1950): Тьюринг предложил знаменитый тест Тьюринга для измерения способности машины демонстрировать интеллектуальное поведение, эквивалентное поведению человека или неотличимое от него.
- Разработка персептрона Фрэнком Розенблаттом (1957): персептрон — это тип искусственной нейронной сети, который можно рассматривать как один из самых ранних типов алгоритмов машинного обучения.
- Артур Сэмюэл разработал программу игры в шашки, в которой использовался метод, который мы теперь назвали бы обучением с подкреплением (1959).
- «Программы со здравым смыслом» Джона Маккарти (1959): в этой статье Маккарти предложил получателя советов, гипотетическую программу, которая способна представлять информацию в форме, аналогичной логике предикатов, и решать проблемы, манипулируя представленной информацией.
Примечание. Информация, которой я делюсь, получена из различных источников + мое понимание. Я не занимался прогнозированием профессионально, это просто хобби. Поэтому, если вы считаете какую-то тему неправильной или ошибочной, пожалуйста, оставьте комментарий. Я сделаю все возможное, чтобы исправить их как можно скорее.