Векторизованная логистическая регрессия

Лежащая в основе любого алгоритма искусственной нейронной сети (ИНС) математика может быть сложной для понимания. Более того, матричные и векторные операции, используемые для представления вычислений с прямой и обратной связью во время пакетного обучения модели, могут увеличить нагрузку на понимание. В то время как краткие матричные и векторные обозначения имеют смысл, разбор таких обозначений до тонких рабочих деталей таких матричных операций принесет больше ясности. Я понял, что лучший способ понять такие тонкие детали — рассмотреть минимальную сетевую модель. Я не мог найти лучшего алгоритма, чем логистическая регрессия, для изучения того, что происходит под капотом, потому что у него есть все прибамбасы ИНС, такие как многомерные входные данные, веса сети, смещение, операции прямого распространения, активации, которые применяют нелинейные функция, функция потерь и обратное распространение на основе градиентов. Моя цель в этом блоге — поделиться своими заметками и выводами о матричных и векторных операциях, которые являются основой модели логистической регрессии.
Краткий обзор логистической регрессии
Несмотря на свое название, логистическая регрессия — это алгоритм классификации, а не алгоритм регрессии. Обычно он используется для двоичной классификации, чтобы предсказать вероятность принадлежности экземпляра к одному из двух классов, например, предсказать, является ли электронное письмо спамом или нет. Таким образом, в логистической регрессии зависимая или целевая переменная считается категориальной переменной. Например, электронное письмо, являющееся спамом, представлено как 1, а не спам как 0. Основная цель модели логистической регрессии — установить взаимосвязь между входными переменными (признаками) и вероятностью целевой переменной. Например, учитывая характеристики электронной почты как набора входных функций, модель логистической регрессии найдет связь между такими функциями и вероятностью того, что электронная почта является спамом. Если «Y» представляет выходной класс, например, электронное письмо является спамом, «X» представляет входные функции, вероятность может быть обозначена как π = Pr (Y = 1 | X, βi), где βi представляет параметры логистической регрессии. которые включают веса модели 'wi' и параметр смещения 'b'. По сути, логистическая регрессия предсказывает вероятность Y = 1 с учетом входных функций и параметров модели. В частности, вероятность π моделируется как S-образная логистическая функция, называемая сигмовидной функцией, задаваемая выражением π = e^z/(1 + e^z) или, что то же самое, π = 1/(1 + e^-z), где z = βi. X. Сигмовидная функция допускает гладкую кривую, ограниченную от 0 до 1, что делает ее пригодной для оценки вероятностей. По сути, модель логистической регрессии применяет сигмовидную функцию к линейной комбинации входных признаков, чтобы предсказать вероятность от 0 до 1. Обычный подход к определению выходного класса экземпляра — пороговое значение прогнозируемой вероятности. Например, если прогнозируемая вероятность больше или равна 0,5, экземпляр классифицируется как относящийся к классу 1; в противном случае он классифицируется как класс 0.

Модель логистической регрессии обучается путем подгонки модели к обучающим данным, а затем минимизации функции потерь для настройки параметров модели. Функция потерь оценивает разницу между прогнозируемой и фактической вероятностью выходного класса. Наиболее распространенной функцией потерь, используемой при обучении модели логистической регрессии, является функция логарифмических потерь, также известная как функция потерь двоичной перекрестной энтропии. Формула для функции Log Loss выглядит следующим образом:
L = — ( y * ln(p) + (1 — y) * ln(1 — p) )
Где:
- L представляет потерю журнала.
- y — двоичная метка истинной истины (0 или 1).
- p - прогнозируемая вероятность выходного класса.
Модель логистической регрессии корректирует свои параметры, минимизируя функцию потерь с помощью таких методов, как градиентный спуск. Учитывая набор входных признаков и их метки классов истинности, обучение модели выполняется в несколько итераций, называемых эпохами. В каждую эпоху модель выполняет операции прямого распространения для оценки потерь и операции обратного распространения для минимизации функции потерь и корректировки параметров. Все такие операции в эпоху используют матричные и векторные вычисления, как показано в следующих разделах.
Матричные и векторные обозначения
Обратите внимание, что я использовал скрипты LaTeX для создания математических уравнений и матричных/векторных представлений, встроенных в этот блог в виде изображений. Если кого-то интересуют сценарии LaTeX, не стесняйтесь обращаться ко мне; Я буду рад поделиться.
Как показано на схематической диаграмме выше, бинарный классификатор логистической регрессии используется в качестве примера для упрощения иллюстраций. Как показано ниже, матрица X представляет количество входных экземпляров m. Каждый входной экземпляр содержит число признаков «n» и представлен в виде столбца, вектора входных признаков в матрице X, что делает его матрицей размера (n x m). Верхний индекс (i) представляет собой порядковый номер входного вектора в матрице X. Нижний индекс «j» представляет собой порядковый индекс функции во входном векторе. Матрица Y размера (1 x m) фиксирует метки истинности, соответствующие каждому входному вектору в матрице X. Веса модели представлены вектором-столбцом W размера (n x 1), содержащим «n» весовых параметров, соответствующих каждому функция во входном векторе. Хотя имеется только один параметр смещения «b», для иллюстрации операций с матрицей/вектором рассматривается матрица B размера (1 x m), содержащая «m» числа одного и того же параметра смещения b.
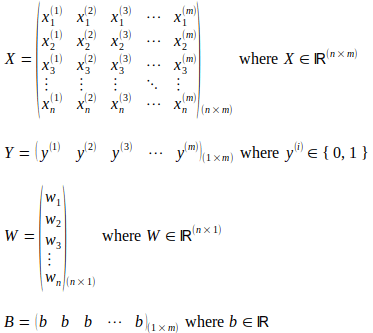
Прямое распространение
Первым шагом в операции прямого распространения является вычисление линейной комбинации параметров модели и входных признаков. Обозначение такой матричной операции показано ниже, где оценивается новая матрица Z:

Обратите внимание на использование транспонирования матрицы весов W. Вышеупомянутая операция в расширенном представлении матрицы выглядит следующим образом:

Приведенная выше матричная операция приводит к вычислению матрицы Z размера (1 x m), как показано ниже:

Следующим шагом является получение активаций путем применения сигмовидной функции к вычисленным линейным комбинациям для каждого входа, как показано в следующей матричной операции. Это приводит к активационной матрице A размера (1 x m).
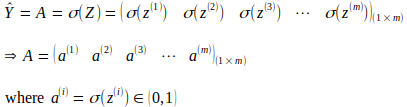
Обратное распространение
Обратное распространение или обратное распространение — это метод вычисления вклада каждого параметра в общую ошибку или потери, вызванные неправильными прогнозами в конце каждой эпохи. Вклад отдельных потерь оценивается путем вычисления градиентов функции потерь по отношению к (относительно) каждого параметра модели. Градиент или производная функции - это скорость изменения или наклон этой функции по отношению к параметру, при котором другие параметры рассматриваются как константы. При оценке для определенного значения параметра или точки знак градиента указывает, в каком направлении функция увеличивается, а величина градиента указывает на крутизну склона. Функция логарифмических потерь, как показано ниже, представляет собой выпуклую функцию в форме чаши с одной точкой глобального минимума. Таким образом, в большинстве случаев градиент функции логарифмических потерь относительно параметра указывает направление, противоположное глобальным минимумам. После оценки градиентов значение каждого параметра обновляется с использованием градиента параметра, обычно с использованием метода, называемого градиентным спуском.
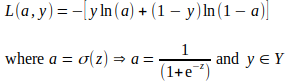
Градиент для каждого параметра вычисляется с использованием цепного правила. Цепное правило позволяет вычислять производные функций, состоящих из других функций. В случае логистической регрессии логарифмическая потеря L является функцией активации «a» и метки истинности «y», в то время как сама «a» является сигмоидной функцией «z», а «z» является линейной функцией веса «w» и смещение «b», подразумевая, что функция потерь L представляет собой функцию, состоящую из других функций, как показано ниже.

Используя цепное правило частных производных, градиенты параметров веса и смещения можно вычислить следующим образом:
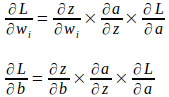
Получение градиентов для одного экземпляра ввода
Прежде чем мы рассмотрим матричные и векторные представления, которые вступают в игру как часть обновления параметров за один раз, мы сначала получим градиенты, используя один входной экземпляр, чтобы лучше понять основу для таких представлений.
Предполагая, что «a» и «z» представляют собой вычисленные значения для одного входного экземпляра с меткой достоверности «y», градиент функции потерь относительно «a» может быть получен следующим образом. Обратите внимание, что этот градиент является первой величиной, необходимой для оценки цепного правила для последующего получения градиентов параметров.

Учитывая градиент функции потерь относительно «a», градиент функции потерь относительно «z» может быть получен с использованием следующего цепного правила:

Приведенное выше цепное правило подразумевает, что градиент «a» относительно «z» также должен быть получен. Обратите внимание, что «а» вычисляется путем применения сигмовидной функции к «z». Следовательно, градиент «a» относительно «z» может быть получен с помощью выражения сигмовидной функции следующим образом:

Приведенный выше вывод выражается через «e», и кажется, что для оценки градиента «a» относительно «z» необходимы дополнительные вычисления. Мы знаем, что «а» вычисляется как часть прямого распространения. Следовательно, чтобы исключить любые дополнительные вычисления, приведенную выше производную можно полностью выразить через «а» следующим образом:

Подставив вышеуказанные термины, выраженные через «а», градиент «а» по отношению к «z» будет следующим:

Теперь, когда у нас есть градиент функции потерь относительно «a» и градиент «a» относительно «z», градиент функции потерь относительно «z» можно оценить следующим образом:

Мы прошли долгий путь в оценке градиента функции потерь относительно «z». Нам все еще нужно оценить градиенты функции потерь по параметрам модели. Мы знаем, что «z» — это линейная комбинация параметров модели и характеристик входного экземпляра «x», как показано ниже:

Используя цепное правило, градиент функции потерь относительно параметра веса «wi» оценивается, как показано ниже:

Точно так же градиент функции потерь относительно «b» оценивается следующим образом:

Матричное и векторное представление обновлений параметров с использованием градиентов
Теперь, когда мы понимаем формулы градиента для параметров модели, полученные с использованием одного входного экземпляра, мы можем представить формулы в матричной и векторной формах с учетом всей обучающей партии. Сначала мы векторизуем градиенты функции потерь относительно «z», заданной следующим выражением:
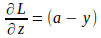
Векторная форма приведенного выше для всего количества экземпляров m:

Точно так же градиенты функции потерь для каждого веса «wi» могут быть векторизованы. Градиент функции потерь относительно веса «wi» для одного экземпляра определяется выражением:

Векторная форма приведенного выше для всех весов во всех входных экземплярах «m» оценивается как среднее значение градиентов «m» следующим образом:

Точно так же результирующий градиент функции потерь относительно «b» для всех «m» входных экземпляров вычисляется как среднее значение градиентов отдельных экземпляров следующим образом:
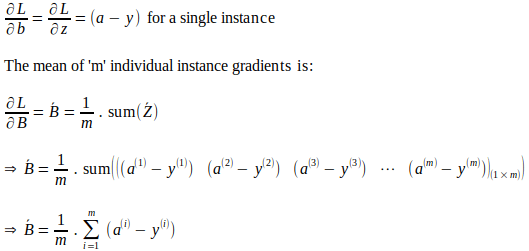
Учитывая вектор градиента весов модели и общий градиент смещения, параметры модели обновляются следующим образом. Обновления параметров, как показано ниже, основаны на методе, называемом градиентным спуском, где используется скорость обучения. Скорость обучения — это гиперпараметр, используемый в методах оптимизации, таких как градиентный спуск, для управления размером шага корректировок, вносимых в каждую эпоху в параметры модели на основе вычисленных градиентов. По сути, скорость обучения действует как коэффициент масштабирования, влияющий на скорость и сходимость алгоритма оптимизации.

Заключение
Как видно из матричных и векторных представлений, проиллюстрированных в этом блоге, логистическая регрессия позволяет минимальной сетевой модели понять тонкие рабочие детали таких матричных и векторных операций. Большинство библиотек машинного обучения инкапсулируют такие мельчайшие математические детали, но вместо этого предоставляют четко определенные программные интерфейсы на более высоком уровне, такие как прямое или обратное распространение. Хотя понимание всех таких тонких деталей может и не требоваться для разработки моделей с использованием таких библиотек, такие детали проливают свет на математическую интуицию, лежащую в основе таких алгоритмов. Однако такое понимание, безусловно, поможет перенести лежащие в основе математические интуиции на другие модели, такие как ANN, рекуррентные нейронные сети (RNN), сверточные нейронные сети (CNN) и генеративно-состязательные сети (GAN).