Модели больших языков (LLM), такие как GPT-4, произвели революцию в области ИИ, продемонстрировав исключительную производительность в различных задачах рассуждения. Однако большая часть этих исследований была ограничена статической средой, такой как решение математических задач или ответы на вопросы, основанные на фактах. В связи с этим возникает вопрос: можно ли использовать LLM для сложных интерактивных задач в реальном физическом мире? Представьте, что у вас есть агент, который может помочь в выполнении повседневных задач; могут ли LLM достичь этого?

Возьмем, к примеру, задачу проверки электронной проводимости неизвестного объекта, которая есть в бенчмарке ScienceWorld. Агент ИИ должен будет перемещаться по нескольким комнатам, находить такие предметы, как батареи и лампочки, строить цепь, проводить эксперимент и интерпретировать результаты. Успешное выполнение таких сложных интерактивных задач — непростая задача: от агентов требуется, чтобы они не только понимали динамические сценарии реального мира, но и обладали когнитивными и логическими способностями более высокого порядка. К ним может относиться долгосрочное планирование, декомпозиция задач, эффективное запоминание, рассуждение на основе здравого смысла и обработка исключений.
Предыдущие методы
Исследователи в основном использовали три разных подхода к созданию агентов: обучение с подкреплением (RL), клонирование поведения (BC) от агентов-оракулов и подсказка LLM. например ГПТ-4. Последний показывает гораздо лучшую производительность, но страдает от более высоких затрат и подверженности ошибкам. Недавние работы, такие как SayCan, ReAct и Reflexion, добились успехов в этой области, но важный вопрос все еще нерешен: Можем ли мы еще больше увеличить возможности LLM в планировании и рассуждении при минимальных затратах?

Войдите в SwiftSage, среду агента ИИ, вдохновленную теорией двойного процесса человеческого познания, изложенной в известной книге Думай, быстро и медленно. Эта теория предлагает две различные системы человеческого мышления: Система 1, характеризующаяся быстрым и интуитивным мышлением; и Система 2, которая делает упор на аналитическое и обдуманное мышление. Интегрируя оба мыслительных модуля, мы стремимся оптимизировать потенциал агента для планирования сложных интерактивных задач, минимизируя при этом стоимость его рассуждений.
SwiftSage: мышление, быстрое и медленное

В нашей последней исследовательской работе от AI2 и USC мы представляем новаторскую платформу SwiftSage, предназначенную для разработки агентов ИИ, которые имитируют способности человека решать сложные задачи с использованием быстрых и медленных мыслительных процессов. Он состоит из двух основных модулей: модуля Swift, имитирующего Систему 1, и модуля Sage, эмулирующего Систему 2. Эффективно интегрируя эти два модуля, мы можем использовать возможности как имитационного обучения, так и подсказка LLM в той же структуре агента.

Модуль Swift представляет собой LM на основе кодировщика-декодера, предназначенный для быстрой обработки содержимого кратковременной памяти, такого как предыдущие действия, текущие наблюдения и состояние окружающей среды. Он имитирует быстрое, интуитивное мышление, характерное для Системы 1. Используя метод клонирования поведения и используя огромные объемы автономных данных, генерируемых агентами оракула, модуль Swift способен эффективно понимать целевую среду и требования поставленной задачи. .
С другой стороны, модуль Sage представляет собой продуманный мыслительный процесс Системы 2, использующий мощь больших языковых моделей (LLM), таких как GPT-4. В этом модуле используется двухэтапный процесс: планирование и обоснование. На этапе планирования LLM определяют необходимые элементы, разрабатывают и отслеживают подцели и обрабатывают любые возможные исключения. Затем на этапе заземления эти запланированные подцели преобразуются в последовательность выполняемых действий с использованием шаблонов действий. Примечательно, что этот подход отличается от предыдущих методов, которые генерируют действия последовательно на каждом временном шаге.

Эвристический алгоритм играет решающую роль в определении того, когда активировать или деактивировать модуль Sage. Например, когда агент Swift получает обратную связь, указывающую на неудачное действие, это служит сигналом для переключения на более обдуманное и подробное планирование, предоставляемое модулем Sage. Кроме того, наш алгоритм эффективно преобразует выходные данные Sage в действительные действия в целевой среде, используя механизм буфера действий.
Оценка
В комплексной оценке с использованием 30 задач из теста ScienceWorld SwiftSage превосходит другие методы, достигая современного среднего балла 84,7 (из 100). Для сравнения, альтернативные подходы, такие как SayCan, набрали 33,8 балла, ReAct — 36,4, а Reflexion — всего 45,3 (даже после нескольких испытаний). Кроме того, SwiftSage оказывается значительно более экономичным и эффективным.
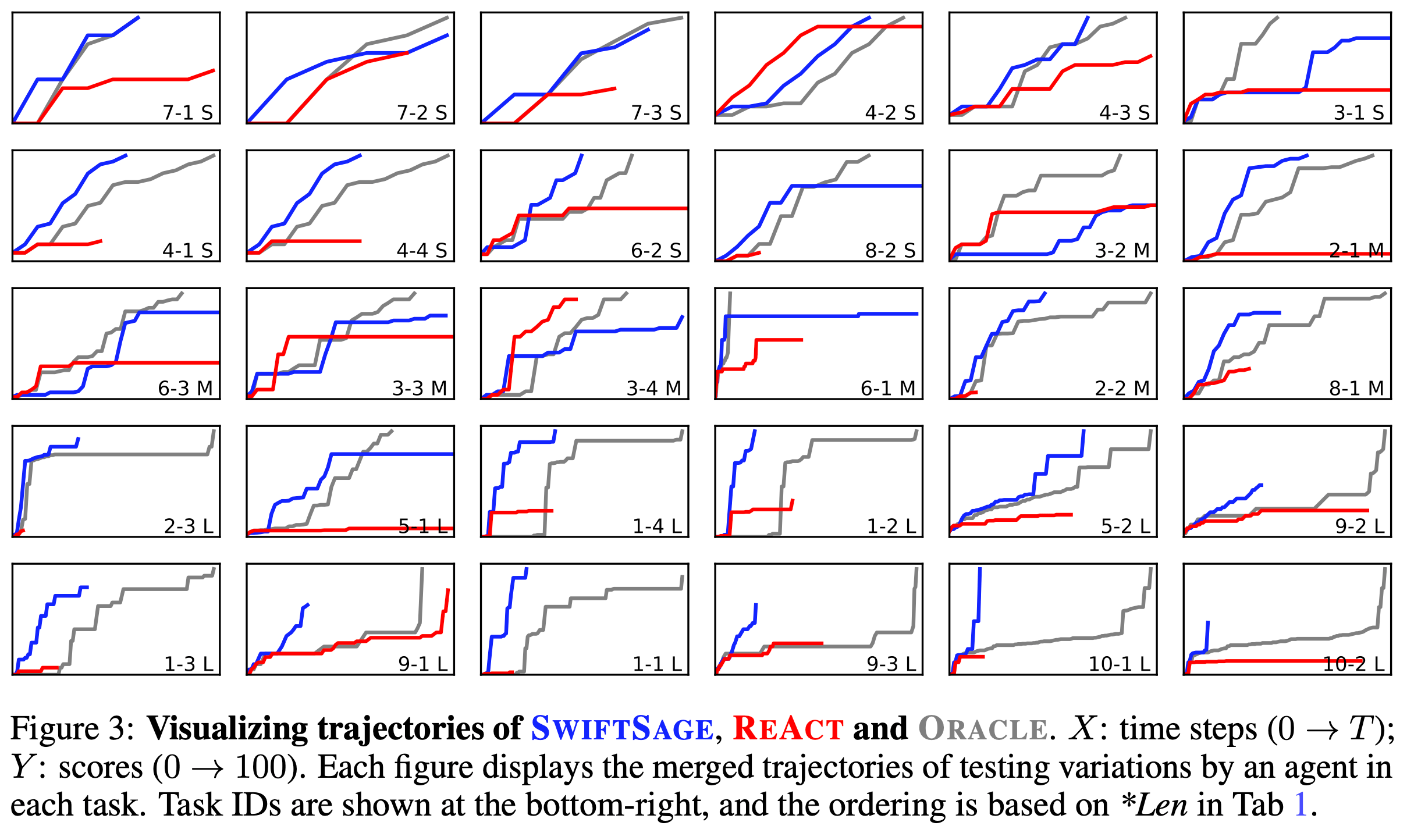
Благодаря двухсистемному дизайну для быстрого и медленного мышления SwiftSage значительно сокращает количество токенов, необходимых для каждого действия в выводе LLM, что делает его более экономичным и эффективным, чем полагаться исключительно на метод, основанный на подсказках. В среднем Saycan и ReAct требуют почти 2000 токенов для создания действия, Reflexion требует около 3000 токенов, а SwiftSage нужно всего около 750 токенов. Кроме того, SwiftSage демонстрирует превосходную эффективность в интерактивных задачах, достигая тех же результатов при меньшем количестве действий, как показано на графике ниже.
Заключение
Чтобы продвигать ИИ, мы должны разработать агентов, способных к сложным интерактивным рассуждениям в реальном мире. Мы представляем SwiftSage, инновационную структуру, вдохновленную теорией двойного процесса человеческого познания, которая обеспечивает современную производительность, повышенную эффективность и снижение затрат. Мы считаем, что такие агенты с двойным процессом, которые используют сильные стороны как малых, так и больших LM, имеют решающее значение для решения сложных интерактивных логических задач и создания общих агентов ИИ. Улучшения, достигнутые с помощью SwiftSage, приближают нас к раскрытию всего потенциала LLM в планировании действий, позволяя нам решать сложные реальные проблемы более экономичным способом.
Ссылки
- Статья: https://arxiv.org/abs/2305.17390
- Сайт: https://yuchenlin.xyz/swiftsage/
- Код: https://github.com/allenai/ScienceWorld/
Рекомендации
- React: Синергизация рассуждений и действий в языковых моделях. ArXiv, абс/2210.03629, 2022 г.
- Рефлексия: автономный агент с динамической памятью и саморефлексией. ArXiv, абс/2303.11366, 2023 г.
- Делай, как я могу, а не как я говорю: язык заземления в роботизированных возможностях. На Конференции по обучению роботов, 2022 г.
- Scienceworld: Ваш агент умнее пятиклассника? В Конференция по эмпирическим методам обработки естественного языка, 2022 г.
Подпишитесь на @allen_ai в Твиттере и подпишитесь на Информационную рассылку AI2, чтобы быть в курсе последних новостей и исследований AI2.