
Согласно этому исследованию, обучение одной модели глубокого обучения может генерировать до 626 155 фунтов выбросов CO2 — это примерно равно общему углеродному следу пяти автомобилей за весь срок службы! И не говоря уже о том, что обычно модели глубокого обучения запускаются несколько раз при попытке предсказать значение, то есть во время INFERENCE!
Но есть ли способ уменьшить углеродный след процесса вывода? В этой записи блога мы увидели, что можно пропустить некоторые уровни во время логического вывода и при этом достичь точности на уровне SoTA. Но вы также заметили, что мы сделали меньше вычислений?
Согласно Wołczyk, Maciej и соавт. в этой бумаге мы можем еще больше сократить количество вычислений — при этом повысив точность!
Аргумент:
В этой статье приводится важный аргумент в пользу того, что при попытке раннего выхода из сверточной нейронной сети иногда мы отбрасываем выходные данные, если они ниже порогового значения, но эти отброшенные выходные данные могут содержать полезную информацию.
Таким образом, мы можем повторно использовать эти отброшенные выходные данные, чтобы передать полезную информацию внутреннему классификатору в следующей ветке раннего выхода.
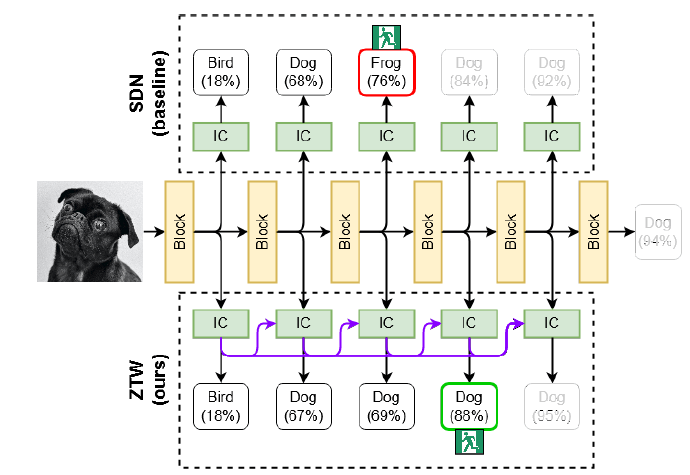
Делается это с помощью каскадных соединений! Концепция каскадирования состоит в том, чтобы продолжать накапливать информацию из предыдущих интегральных схем по мере того, как мы углубляемся!
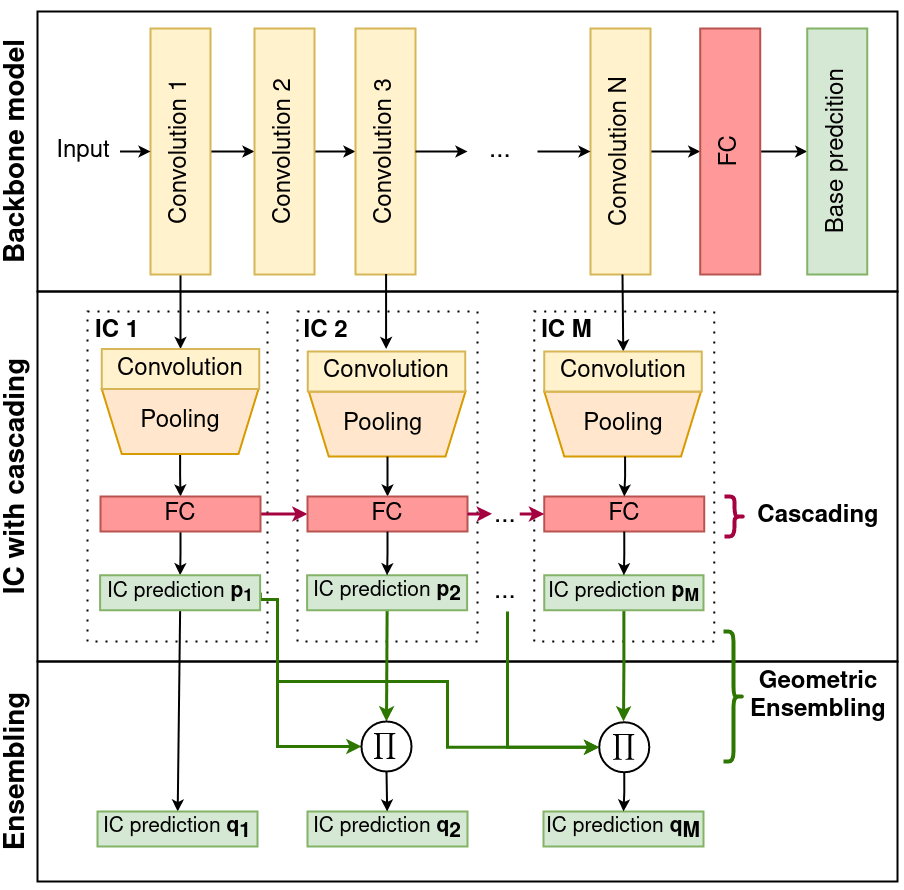
Мы знаем, что на каждом ответвленном соединении у нас есть внутренний классификатор, который заботится о прямой связи. После применения функции softmax к этим IC мы можем получить вероятности каждого класса. Это дается формулой:
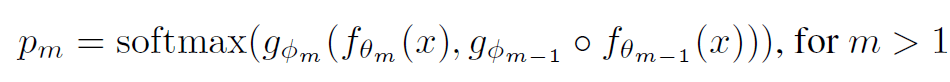
где g_ϕm — выход mᵗʰ IC, а f_θm — выход скрытого слоя m в модели магистрали. То есть мы получаем информацию как от фактической модели магистрали, так и от предыдущего IC, таким образом фиксируя информацию, которую также изучил предыдущий IC.
Мы уже закончили?

Есть еще один способ переработать наши прогнозы — сами прогнозы!
На заключительном этапе этой модели они используют ансамблирование для объединения предыдущих прогнозов. Это представлено формулой:
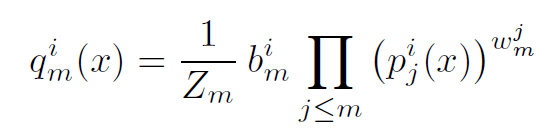
Где pⱼ — это выходные данные микросхем, bₘ и wₘ — обучаемые параметры, а Zₘ гарантирует, что сумма qₘ для всех классов равна 1. «i» представляет класс iᵗʰ, а j представляет слои до текущего уровня m. .
Как только qₘ превышает определенный порог для любого класса i, мы можем вывести прогноз и, таким образом, выйти раньше! В противном случае мы передаем его следующей ИС и продолжаем вычисления.
Заключение:
Этот подход делает следующие обходные пути:
- Во-первых, мы передаем логиты текущего внутреннего классификатора следующему внутреннему классификатору.
- Затем мы можем агрегировать/собрать предыдущий прогноз IC, используя приведенную выше формулу.
Конец!
Использованная литература:
- Струбелл, Э., Ганеш, А., и МакКаллум, А. (2019). Энергетические и политические соображения для глубокого обучения в НЛП. препринт arXiv arXiv:1906.02243.
- Волчик М., Вуйчик Б., Балази К., Подолак И. Т., Табор Ю., Смиея М. и Тшински Т. (2021). Нулевая трата времени: повторное использование прогнозов в нейронных сетях раннего выхода. Достижения в системах обработки нейронной информации, 34, 2516–2528.