Кластеризация, или кластерный анализ, или сегментация данных определяется как группировка похожих объектов в классы, называемые кластерами. В основном это называется неконтролируемым подходом к обучению для классификации шаблонов в группы (кластеры) на основе сходства.
Кластеризация — это алгоритм обучения без присмотра, т. е. алгоритм для данных, в котором мы не знаем о результате эксперимента, а даем только экспериментальные наблюдения. Это одна из наиболее важных областей исследований во многих областях, особенно в области интеллектуального анализа данных.
Некоторые варианты использования кластеризации в реальном времени включают:
››› Системы рекомендаций (группировка пользователей с похожими шаблонами просмотра на Netflix, чтобы рекомендовать аналогичный контент, рекомендации по электронной торговле и персонализацию пользователям на платформах социальных сетей, таких как Instagram и Linkedin)
››› Обнаружение аномалий (обнаружение мошенничества, обнаружение дефектных механических частей)
››› Генетика (кластеризация паттернов ДНК для анализа эволюционной биологии)
Для кластеризации данные могут быть структурированными или неструктурированными. В неструктурированных данных информация не соответствует определенному формату или организована заранее определенным образом. Например, обычно они содержат большое количество текста, но могут также содержать видео, числа, аудио, изображения и т. д. С другой стороны, структурированные данные обычно зависят от реляционных баз данных.
В кластерном анализе набор тесно связанных объектов группируется в кластеры. Таким образом, центральное место в кластерном анализе занимает понятие степени сходства или различия между отдельными кластеризуемыми объектами. Алгоритм кластеризации группирует кластеры на основе заданного определения степени сходства или несходства. Наблюдая за этим, мы можем вкратце сказать, что это напоминает ситуацию с функцией стоимости в обучении с учителем. Таким образом, во всех методах кластеризации основой является выбор расстояния или несходства, измеренного между двумя объектами. Чтобы определить и представить сходство и несходство, мы используем матрицу близости (близости или сходства), также называемую матрицей расстояний.
матрица близости:
Матрица близости представляет собой матрицу NxN, где N — количество объектов. Каждый элемент матрицы представляет сходство или различие между этой парой объектов. Эта матрица передается алгоритму кластеризации. Большинство существующих алгоритмов ищут симметричную матрицу. поэтому, если матрица несимметрична, явно сделайте матрицу симметричной, добавив несимметричную матрицу к ее транспонированию.
В большинстве случаев мы используем термины Расстояние (несходство) и Сходство (корреляция). Что касается количественных характеристик данных, предпочтение отдается расстоянию, чтобы распознать взаимосвязь между данными. И сходство предпочтительнее при работе с качественными данными.
Обычно используемые функции расстояния:
- Евклидово расстояние
- Манхэттенское расстояние
- Квадрат евклидова расстояния
- Косинусное расстояние
- Расстояние Махаланобиса
Часто используемые функции подобия:
- Сходство с Жаккаром
- Сходство Хэмминга
- Косинусное сходство
Алгоритмы кластеризации:
Алгоритмы кластеризации делятся на различные категории на основе разных показателей.
Обзор алгоритмов кластеризации:
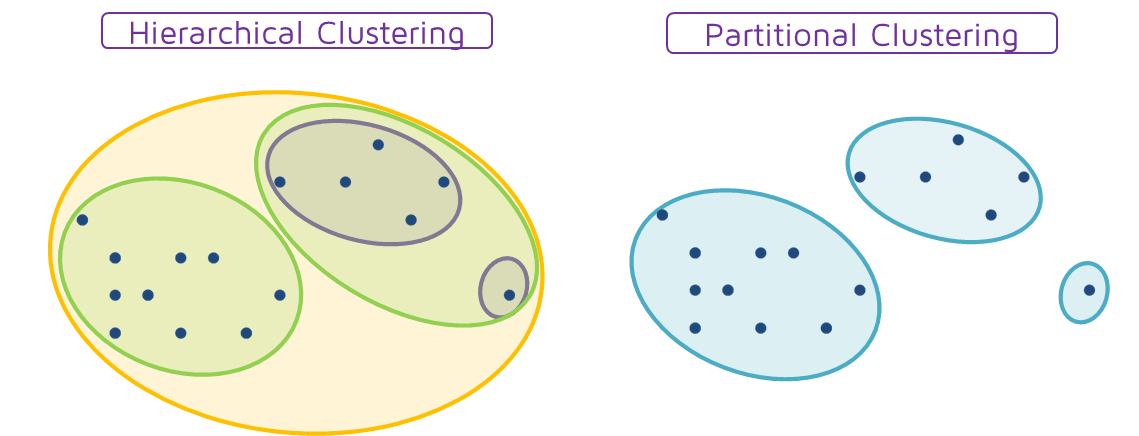
1. Кластеризация на основе иерархии (иерархическая кластеризация):
Основная идея иерархической кластеризации заключается в построении иерархических отношений между данными для кластеризации. Алгоритмы иерархической кластеризации бывают двух типов: разделительные и агломеративные.
Алгоритмы иерархической кластеризации включают,
AGNES(агломеративное вложение), ДИАНА(разделительный анализ), ХАМЕЛЕОН BIRCH (сбалансированное итеративное сокращение и кластеризация с использованием иерархий), CURE (кластеризация с использованием представителей ) и ROCK(Надежная кластеризация с использованием ссылок).
2. Кластеризация на основе раздела (частичная кластеризация):
Основная идея алгоритма Partition состоит в том, чтобы рассматривать центр точек данных как центр соответствующего кластера.
Алгоритмы частичной кластеризации включают в себя:
К-средние, К-медоиды, PAM (разделение вокруг Medoid), CLARA (кластеризация больших приложений), CLARANS (кластеризация больших приложений на основе RANdomized Поиск).
3. Кластеризация на основе сетки:
Основная идея алгоритмов кластеризации на основе сетки заключается в том, что исходное пространство данных преобразуется в структуру сетки с определенным размером для кластеризации.
Алгоритмы кластеризации на основе Grid включают:
STING (алгоритм на основе сетки статистической информации), OPTIGRID(Оптимальная сетка) , CLIQUE(кластеризация в QUEst).

4. Кластеризация на основе плотности:
Основная идея алгоритмов кластеризации на основе плотности заключается в том, что данные, находящиеся в области с высокой плотностью пространства данных, считаются принадлежащими одному и тому же кластеру.
Алгоритмы кластеризации на основе плотности включают:
DBSCAN (Пространственная кластеризация приложений с шумом на основе плотности) , OPTICS (Точки заказа для определения структуры кластера) , DENCLUE(CLUstEring на основе DENsity) и Средний сдвиг
5. Кластеризация на основе нечеткой теории (мягкая кластеризация):
Мягкая кластеризация — это форма подхода к кластеризации, при котором точки данных принадлежат более чем одному кластеру с определенной степенью принадлежности, обычно от 0 до 1.
Алгоритмы мягкой кластеризации включают,
FCM (Нечеткие C-средние), FCS (Fuzzy C-Strange)и FLAME (нечеткая кластеризация с помощью локальной аппроксимации членства)
6. Кластеризация на основе модели:
Кластеризация на основе модели выбирает конкретную модель для каждого кластера и находит наилучшее соответствие для этой модели. В основном существует два типа алгоритмов кластеризации на основе моделей: один основан на методе статистического обучения, а другой — на методе обучения нейронной сети.
Алгоритмы, основанные на методе статистического обучения,
COBWEB (инкрементная система для иерархической кластеризации) и GMM (смешанная модель Гаусса).
Алгоритмы, основанные на методе обучения нейронной сети,
SOM (самоорганизующаяся карта), LVQ (обучение векторному квантованию) и ART (Теория адаптивного резонанса)
7. Кластеризация ансамбля
Этот алгоритм кластеризации генерирует набор начальных результатов кластеризации с помощью определенного метода, а окончательный результат кластеризации получается путем интеграции начальных результатов кластеризации.
Это очень краткий обзор алгоритмов кластеризации. Я надеюсь, что вы найдете это полезным. В следующем посте я поделюсь алгоритмами и реализацией кода наиболее часто используемых алгоритмов кластеризации из приведенного выше списка. Спасибо…..