Революция началась с Alexnet, откуда пришло передовое компьютерное зрение, люди начали экспериментировать с другой архитектурой. Карен Симонян и Эндрю Зиссерман, работающие на факультете инженерных наук Оксфордского университета, придумали очень глубокую сверточную сеть после некоторых экспериментов с набором данных ImageNet Challenge 2014. Оригинальная статья называется ОЧЕНЬ ГЛУБОКИЕ СВЕРТОЧНЫЕ СЕТИ ДЛЯ КРУПНОМАСШТАБНОЕ РАСПОЗНАВАНИЕ ИЗОБРАЖЕНИЙ
Введение

VGG16 — это тип CNN (сверточной нейронной сети), который на сегодняшний день считается одной из лучших моделей компьютерного зрения. Создатели этой модели оценили сети и увеличили глубину, используя архитектуру с очень маленькими (3 × 3) фильтрами свертки, которые продемонстрировали значительное улучшение по сравнению с конфигурациями предшествующего уровня техники. Они увеличили глубину до 16–19 весовых слоев, что составляет примерно «138 миллионов» тренировочных параметров. VGG16 — это алгоритм обнаружения и классификации объектов, способный классифицировать 1000 изображений 1000 различных категорий. Это один из популярных алгоритмов классификации изображений, который легко использовать с трансферным обучением.
Архитектура VGG-16
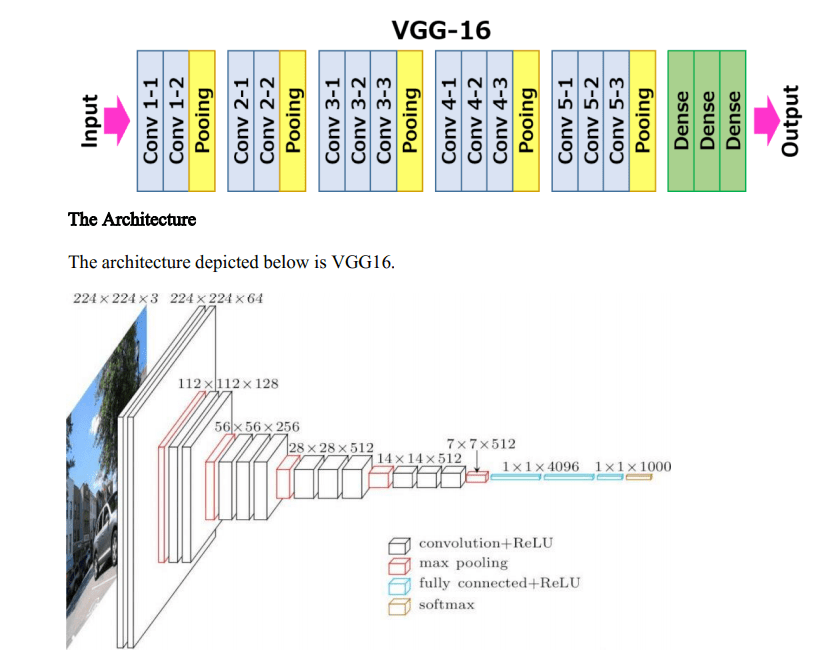
- 16 в VGG16 относится к 16 слоям, имеющим веса. В VGG16 есть тринадцать сверточных слоев, пять слоев Max Pooling и три плотных слоя, которые в сумме составляют 21 слой, но имеют только шестнадцать весовых слоев, то есть слой обучаемых параметров.
- VGG16 принимает размер входного изображения как 224, 244 с 3 каналами RGB.
- Самая уникальная особенность VGG16 заключается в том, что вместо большого количества гиперпараметров они сосредоточились на сверточных слоях очень маленького фильтра, то есть 3 * 3 с шагом 1, и всегда использовали один и тот же слой заполнения и максимальный слой пула фильтра 2 * 2 из шаг 2.
- Слой Conv-1 имеет 64 фильтра, Conv-2 имеет 128 фильтров, Conv-3 имеет 256 фильтров, Conv 4 и Conv 5 имеет 512 фильтров.
- Три полносвязных (FC) слоя следуют стеку сверточных слоев: первые два имеют по 4096 каналов каждый, третий выполняет 1000-канальную классификацию ILSVRC и, таким образом, содержит 1000 каналов (по одному на каждый класс). Последний слой — это слой soft-max.
- После каждого слоя они добавили функцию активации ReLU, которая заботится об исчезающем градиенте, поскольку не активирует все нейроны одновременно.
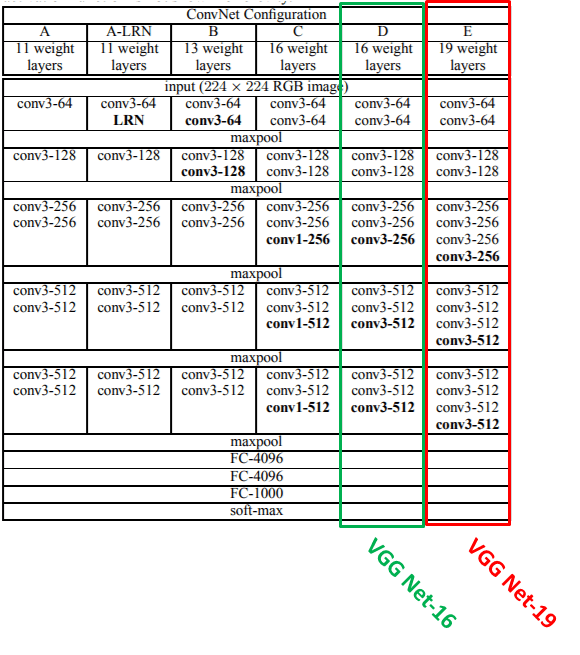
Таблицы из оригинальной исследовательской работы
Глубина конфигураций увеличивается слева (A) направо (E) по мере добавления дополнительных слоев (добавленные слои выделены жирным шрифтом). Параметры сверточного слоя обозначаются как «размер конвективного поля i — количество каналов i». Функция активации ReLU не показана для краткости.

Ниже показана функция VGG-16, которую я использовал для своего проекта обнаружение эмоций на лице в наборе данных FER 2013, где у меня есть входное изображение размером 48 * 48 * 1, и я должен классифицировать его по 7 классам. (эмоция).
def FER_vgg16_model(input_shape=(48, 48, 1)):
visible = Input(shape=input_shape, name='input')
num_classes = 7
# 1stblock with 2 conv
conv1_1 = Conv2D(64, kernel_size=3, activation='relu', padding='same', name='conv1_1')(visible)
conv1_1 = BatchNormalization()(conv1_1)
conv1_2 = Conv2D(64, kernel_size=3, activation='relu', padding='same', name='conv1_2')(conv1_1)
conv1_2 = BatchNormalization()(conv1_2)
pool1_1 = MaxPooling2D(pool_size=(2, 2), name='pool1_1')(conv1_2)
drop1_1 = Dropout(0.3, name='drop1_1')(pool1_1)
# the 2-nd block with 2 conv
conv2_1 = Conv2D(128, kernel_size=3, activation='relu', padding='same', name='conv2_1')(drop1_1)
conv2_1 = BatchNormalization()(conv2_1)
conv2_2 = Conv2D(128, kernel_size=3, activation='relu', padding='same', name='conv2_2')(conv2_1)
conv2_2 = BatchNormalization()(conv2_2)
pool2_1 = MaxPooling2D(pool_size=(2, 2), name='pool2_1')(conv2_2)
drop2_1 = Dropout(0.3, name='drop2_1')(pool2_1)
# the 3-rd block with 3 conv
conv3_1 = Conv2D(256, kernel_size=3, activation='relu', padding='same', name='conv3_1')(drop2_1)
conv3_1 = BatchNormalization()(conv3_1)
conv3_2 = Conv2D(256, kernel_size=3, activation='relu', padding='same', name='conv3_2')(conv3_1)
conv3_2 = BatchNormalization()(conv3_2)
conv3_3 = Conv2D(256, kernel_size=3, activation='relu', padding='same', name='conv3_3')(conv3_2)
conv3_3 = BatchNormalization()(conv3_3)
pool3_1 = MaxPooling2D(pool_size=(2, 2), name='pool3_1')(conv3_3)
drop3_1 = Dropout(0.3, name='drop3_1')(pool3_1)
# the 4-rd block with 3 conv
conv4_1 = Conv2D(512, kernel_size=3, activation='relu', padding='same', name='conv4_1')(drop3_1)
conv4_1 = BatchNormalization()(conv4_1)
conv4_2 = Conv2D(512, kernel_size=3, activation='relu', padding='same', name='conv4_2')(conv4_1)
conv4_2 = BatchNormalization()(conv4_2)
conv4_3 = Conv2D(512, kernel_size=3, activation='relu', padding='same', name='conv4_3')(conv4_2)
conv4_3 = BatchNormalization()(conv4_3)
pool4_1 = MaxPooling2D(pool_size=(2, 2), name='pool4_1')(conv4_3)
drop4_1 = Dropout(0.2, name='drop4_1')(pool4_1)
# the 5-rd block with 3 conv
conv5_1 = Conv2D(512, kernel_size=3, activation='relu', padding='same', name='conv5_1')(drop4_1)
conv5_1 = BatchNormalization()(conv5_1)
conv5_2 = Conv2D(512, kernel_size=3, activation='relu', padding='same', name='conv5_2')(conv5_1)
conv5_2 = BatchNormalization()(conv5_2)
conv5_3 = Conv2D(512, kernel_size=3, activation='relu', padding='same', name='conv5_3')(conv5_2)
conv5_3 = BatchNormalization()(conv5_3)
pool5_1 = MaxPooling2D(pool_size=(2, 2), name='pool5_1')(conv5_3)
drop5_1 = Dropout(0.2, name='drop5_1')(pool5_1)
# Flatten and output
flatten = Flatten(name='flatten')(drop5_1)
FC1 = Dense(4096, activation="relu", name='FullyConnected1')(flatten)
drop6_1 = Dropout(0.1, name = 'drop6_1')(FC1)
FC2 = Dense(4096, activation="relu", name='FullyConnected2')(drop6_1)
drop7_1 = Dropout(0.1, name='drop7_1')(FC2)
FC3 = Dense(1000, activation="relu", name='FullyConnected3')(drop7_1)
drop8_1 = Dropout(0.1, name='drop8_1')(FC3)
ouput = Dense(num_classes, activation='softmax', name='output')(drop8_1)
# create model
model = Model(inputs=visible, outputs=ouput)
return model
Для каждого слоя свертки:
- Фильтр = 3*3
- Шаг = 1
- Прокладка = такая же
Для каждого слоя максимального пула:
- Фильтр = 2*2
- Шаг = 2
Проблема с Алекснет
У него меньше слоев, из-за чего он не может извлечь больше признаков. Кроме того, они выбирают фиксированное количество фильтров и шаг для свертки и объединения с фиксированными ядрами после каждого слоя/эксперимента.
Преимущество VGG-16 перед Alexnet
- В каждом из сверточных слоев размер фильтра равен 3*3, шаг равен 1, а заполнение такое же, а в каждом максимальном объединяющем фильтре размер равен 2*2, а шаг равен 2.
- Поскольку VGG-16 — это очень глубокая нейронная сеть, она будет извлекать больше функций из изображения, и хотя мы углубляемся, проблема исчезающего градиента решается функцией активации ReLU.
- VGG-16 — это систематическая нейронная сеть, которая имеет одинаковый шаг и фильтр как для свертки, так и для объединения в пул независимо друг от друга.
- Разница между vgg-16 и vgg-19 заключается в том, что vgg-19 имеет еще 3 слоя свертки, что делает его производительность немногим лучше, чем vgg16.