Экономьте время и усилия, не повторяя эти ошибки 😲

Когда я начал свое путешествие по науке о данных с моего курса Machine Learning 101, моего первого проекта Kaggle, моей первой стажировки, моей первой работы, я был в основном новичком, стремящимся учиться, но также немного самоуверенным, думая, что я все это знаю.
Сегодня мне кажется нереальным оглянуться назад и понять, сколько ошибок я в итоге совершил. Что касается небольшого анекдота, я помню, как получил оценку R2 0,98 с линейной регрессией, думая «Черт, машинное обучение — это просто» без какого-либо понятия о перекрестной проверке, обобщении модели или выборе функций.
«Умный человек совершает ошибку, учится на ней и никогда больше не совершает эту ошибку» — Рой Х. Уильямс (1958-)
В конце концов, ошибки — неотъемлемая часть пути Data Scientist! Поскольку мы решаем сложные задачи с данными, мы неизбежно совершаем так много ошибок. Но что еще больше беспокоит, так это то, что вы даже не обнаруживаете ошибку или не избавляетесь от тех вредных привычек, которые могут резко помешать вашему росту и обучению как Data Scientist.
Вот почему я определил некоторые из ключевых ошибок, которые я видел в прошлом у коллег по данным, кандидатов и/или я сам, чтобы вы могли их избежать. Мы также будем использовать пример случая по пути, чтобы проиллюстрировать.
№1 Начать не с той ноги
Я реализовал проект, который не оправдал ожиданий клиента, потому что с моей стороны не был должным образом установлен масштаб.
Я думал, что моя модель глубокого обучения для прогнозирования временных рядов работает очень хорошо, пока не понял, что использование предыдущего значения в качестве предиктора дало мне лучшие результаты…
Подсознательно, начиная проект, мы склонны браться за дело и спешить, чтобы получить быстрые результаты, но снова и снова эти результаты не соответствуют ожиданиям, потому что с самого начала был сделан неправильный поворот.
Чтобы избежать фальстарта, я настоятельно рекомендую вам следовать этим трем основным шагам, которые настроят вас на стабильный успех:
Сформулируйте проблему
Потратьте время, чтобы точно определить, какую проблему вы пытаетесь решить. Не забудьте сформулировать ее простым языком на простом английском языке и дважды проверить эту цель с заинтересованными сторонами проекта.
Не стесняйтесь задавать вопросы и оспаривать предположения, сделанные подсознательно клиентом, коллегой или вами самими. Не торопясь с самого начала, вы убедитесь, что движетесь в правильном направлении и не видите выбоин.
Давайте использовать реальный пример, на который я буду ссылаться в статье, чтобы проиллюстрировать. Одним из моих недавних проектов для клиента было создание конвейера прогнозирования временных рядов для 12 недельных периодов (t+1,t+2…). После нескольких встреч мы поняли, что на самом деле нет необходимости в еженедельных прогнозах, поскольку впоследствии для логистических целей будут использоваться только ежемесячные прогнозы. Поэтому мы совместно решили, что ежемесячные прогнозы будут оптимальными. Может показаться, что это легко обнаружить, но это не так. Это стало кульминацией многих дискуссий, направленных на то, чтобы понять ценность проекта для бизнеса.
Получить правильную метрику
Заранее установленная цель должна диктовать, какой показатель эффективности вы выберете.
В 90 % случаев показатель, который вы будете использовать для количественной оценки своей эффективности, будет R2 для прогнозов регрессии и точности для классификации. Как я уже сказал, этих метрик чаще бывает достаточно, чем нет, но когда они не соответствуют решаемой проблеме, весь проект оказывается под угрозой.
Позвольте мне привести вам простые сценарии, чтобы показать вам важность выбора правильной метрики:
- Наличие неоднородных/потенциальных выбросов в ваших данных? Хорошая оценка R2 не будет подвигом, потому что ваша модель может сосредоточиться на прогнозировании этих крайностей. Вместо этого используйте убыток MAE или Huber.
- Имея дисбаланс в вашем наборе данных? Точность 90% для модели не является достижением, если 90% ваших точек данных имеют одинаковую метку. Вместо этого используйте Precision, Recall или F1-score (или повторно сбалансируйте набор данных).
Если эти сценарии кажутся вам слишком очевидными, давайте вернемся к этому примеру. В этом конкретном случае прогнозирования продаж MSE не был адекватным, поскольку временные ряды не были сопоставимы с точки зрения масштаба цели и с точки зрения поведения. Таким образом, мы решили «разбить» наш набор данных на меньший набор данных с общими характеристиками и проверить показатель MSE для каждого меньшего набора данных. Также во время фреймовой встречи мы поняли, что уверенность в наших прогнозах крайне важна из месяца в месяц. Следовательно, мы рассмотрели месячную дисперсию нашей MSE, чтобы убедиться, что наша ошибка остается постоянной с течением времени. Межмесячное отклонение приведет к тому, что модель не будет принята пользователями.
Начните с базового уровня
Мы все были там, думая, что у нас есть отличная модель, которая оказалась не так.

Это настолько просто, что многим может показаться анекдотичным, но часто его легко упустить из виду. Каждый раз, когда вы начинаете проект, вы должны начать с исходного плана. Два способа сделать это:
- Если существует уже существующая модель (закодированная или субъективная), вам следует пересчитать ее показатели. Это также будет доказательством превосходства вашей модели, чтобы убедить различные заинтересованные стороны.
- Если нет, вам следует найти действительно простую/глупую модель, то есть мобильные средства для прогнозирования временных рядов, всегда предсказывающие класс большинства для классификации…
Это должно стать легкой задачей, чтобы у вас всегда была точка сравнения для всех будущих моделей, чтобы быстро выйти из тупика, когда производительность не на должном уровне.
Для нашего конкретного примера мы просто использовали значения 12-месячного лага в качестве первого базового уровня. Действительно просто, правда? В этом суть 😅
# 2 Нет проницательного EDA
Через неделю я понял, что в моих данных было много аномалий, поэтому я не мог добиться сходимости моей модели.
Чаще всего младшие специалисты по данным считают исследовательский анализ данных (EDA) трудоемким и неэффективным. Это настолько далеко от истины на мой взгляд, насколько можно:
- Получить знания о предикторах: понять, какой у вас тип признаков, взаимосвязаны ли они или с целевыми, какой тип распределения для моих признаков
- Повышение качества: обнаружение ошибок в данных. Это могут быть выбросы, дубликаты или отсутствующие значения.
- Разберитесь со своими предвзятыми представлениями: визуализация взаимосвязей между вашими функциями может подтвердить или опровергнуть ваши предположения или предубеждения в отношении проблемы.
Этот последний пункт для меня очень важен. EDA — это прекрасная возможность проанализировать проблему и выявить невидимые проблемы для различных заинтересованных сторон.
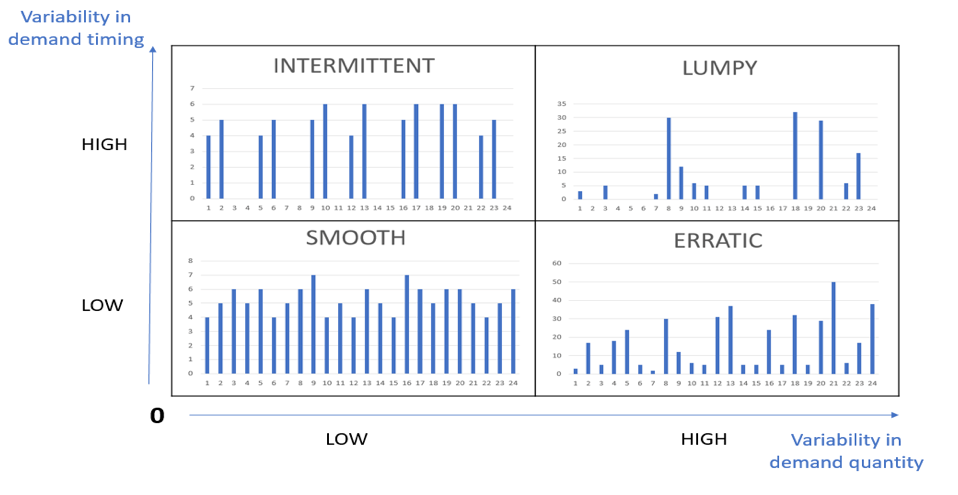
Чтобы подкрепить этот последний пункт, в моем предыдущем примере (прогнозирование временных рядов) именно во время углубленного EDA мы поняли, что у нас было совершенно другое поведение в нашем наборе данных. Некоторые временные ряды имели плавное поведение, в то время как некоторые демонстрировали признаки прерывистого спроса (с месяцами, имеющими 0 в качестве значений). Таким образом, обнаружение этого привело нас к опросу заинтересованных сторон о причинах этих различных шаблонов и, что наиболее важно, помогло нам решить проблему.
Исследуя эту тему, я обнаружил отличную библиотеку pandas-profiling, которая генерирует отчеты о профилях с описательной статистикой, графиками корреляции, пропущенными значениями... Это отличная отправная точка для EDA, так что никаких оправданий сейчас!
# 3 Неумение управлять своим временем
Я чувствую себя перегруженным таким количеством задач, которые обещал выполнить, но не могу найти время для их выполнения

Наука о данных иногда может быть утомительной: так много функций, которые нужно добавить в последнюю минуту, или запросов/отчетов помимо тех, которые уже запланированы…
Вот способы, которые я считаю наиболее эффективными для управления своим временем:
- Приоритизация: каждый новый проект, новая функция, новый запрос должны оцениваться с точки зрения приоритета и, следовательно, ранжироваться по сравнению с другими. Как это сделать ? Без надлежащих показателей оценки расстановка приоритетов является сложной задачей. Одной из простых схем является матрица приоритетов действий, которую вы можете увидеть ниже. Быстрые победы нужно поставить в начало списка дел вместе с Крупными проектами. Я рекомендую вам прочитать подробное объяснение матрицы здесь.

- Сосредоточьтесь на одной задаче за раз: было показано, что многозадачность снижает вашу производительность. Мыпросто не можем делать две вещи одновременно. На самом деле мы переключаем наше внимание между двумя задачами. Поэтому прекратите многозадачность :) Один из способов сделать это — разделить свой день на блоки (например, утро для встреч / день для основного проекта).
- Сначала будьте организованы . Приступая к новому проекту, вам необходимо озвучить такие важные вопросы, как: Каково влияние на бизнес? Что такое созданная стоимость? Но что не менее важно, так это вопрос управления задачами и обязанностями. Один из простых и эффективных способов сделать это — через Trello.
# 4 Не закладывать прочный фундамент
Используя дерево решений, мой R2 на моем поезде и тестовом наборе был 0,4. Затем я начал использовать Random Forest и не понимал, почему это не улучшило мои результаты.
Я использовал кластеризацию k-средних на результатах UMap и не могу понять, почему результаты такие странные.
Мои потери в моей нейронной сети застаиваются после 2 эпох, не сойдясь.
Примеров масса. Для меня это огромная ошибка, которую совершают многие специалисты по данным. Очень важно не попасть в ловушку использования алгоритмов, о которых мы ничего не знаем. Мы все делали это и делаем это время от времени: находим новую статью/библиотеку в Интернете. , перейдя на страницу документации и скопировав/вставив пример кода записной книжки, чтобы протестировать его на нашем наборе данных, при этом сначала в 80% случаев возникают сбои.

Машинное обучение стало чрезвычайно популярным, привлекая так много профессионалов как с техническим, так и с нетехническим образованием. Я не могу не подчеркнуть это в достаточной степени для новичков в этой области: установка прочных математических основ перед практическим использованием моделей машинного обучения является обязательным. В противном случае вам будет просто неинтересно быть Data Scientist, вы будете случайным образом пробовать разные модели, разные параметры для ваших моделей, разные потери и, самое главное, застрять на проблемах, не имея представления, как их решить.
Чтобы помочь вам, вот список концепций, с которыми вы должны быть знакомы как Data Scientist:
- Статистика: корреляция и причинно-следственная связь, статистическая независимость, p-значения, t-критерий, начальная загрузка, избыточная выборка.
- Вероятности: логарифмическая потеря, энтропия, прирост информации, различные типы распределений (гауссовское, биномиальное, бета, пуассоновское…), максимальное правдоподобие, теорема Байеса.
- Другое: перекрестная проверка, компромисс смещения и дисперсии, утечка данных, стационарность временного ряда, дискретизация, градиентный спуск и стохастический градиентный спуск.
Прочтите эти концепции, обязательно полностью их поймите. В этом случае вы сможете:
- полное понимание популярных моделей машинного обучения и, по крайней мере, «интуиция» в более сложных документах. Например, вы полностью поймете, как работает дерево решений, узнав о получении информации и энтропии, но также поймете, почему LightGBM так быстр теперь, когда вы знаете о дискретизации и выборке.
- экономить время и усилия, обнаруживая ошибки заранее и находя исправления
- проанализируйте слабые места вашей текущей модели и, что еще более важно, узнайте, в каком направлении нужно двигаться, чтобы улучшить модель. Это навык, который, на мой взгляд, отделяет хороших специалистов от великих специалистов по данным.
# 5 Нет разработки функций
Я потерял так много времени, пытаясь улучшить свою модель, вместо того, чтобы улучшить разработку своих функций. Функции, которые у меня были, в их первоначальном представлении не были полезными.
Эта ошибка тесно связана с предыдущей. Сложные проблемы требуют индивидуальных решений. В основном есть два способа найти решение, если вы застряли в машинном обучении: либо преобразование ваших данных, либо преобразование вашей модели. Выше мы говорили о правильном способе тестирования моделей, но иногда, независимо от того, сколько параметров вы ищете в сетке, сколько моделей вы тестируете, вы просто не можете найти приемлемое решение без надлежащей разработки функций. С имеющимися у вас данными необходимо будет манипулировать, чтобы извлечь наиболее полезную информацию (например, нелинейные отношения, обнаружение закономерностей…).
Возвращаясь к этому примеру из практики, независимо от того, сколько моделей мы пробовали и сколько различных комбинаций гиперпараметров мы тестировали, мы не смогли улучшить модель. Выходим на «плато». Поэтому мы обратились к разработке признаков и решили изменить способ представления наших временных рядов. Не вдаваясь в подробности, скажем, что изменение способа представления нашего временного ряда путем извлечения большего количества полезной информации изменило правила игры для нас, и мы улучшили нашу производительность на 10 %.
В Интернете есть много ресурсов, которые могут научить вас, как заниматься проектированием признаков. FeatureTools может быть интересной библиотекой для ускорения этого процесса, но ее нужно использовать осторожно. Почему так, спросите вы! Как вы уже знаете, полная автоматизация процесса проектирования функций сопряжена с риском. Разработка функций должна быть специфичной для вашего проекта. Я бы предпочел, чтобы вы действительно подумали о том, как вы должны преобразовать свои данные таким образом, чтобы это помогло найти решение. Много идей возникнет, когда вы попытаетесь ответить на эти вопросы: Как мне работать с категориальными переменными? Существуют ли группы данных, которые могут быть интересны для моей задачи? Нужно ли мне расширять или уменьшать функциональные возможности? Должен ли я применить преобразование к своим функциям и моей цели (логарифмическое преобразование)?
# 6 Не любопытство
Я до сих пор использую те же модели, что и в прошлом году.
Наука о данных — это постоянно меняющаяся дисциплина, в которой лучшие сегодняшние модели через 3/4 года станут почти архаичными. Вы должны быть постоянно любопытны и увлечены наукой о данных, чтобы изо дня в день узнавать что-то новое. Потеря этого стремления к обучению может оказаться ловушкой, потому что, как и в других областях, цель состоит в том, чтобы продолжать учиться, чтобы быть лучшим в своей области.
Для этого есть 4 совета:
- Продолжайте задавать глупые вопросы . Самые простые вопросы могут привести к самым нестандартным ответам на различные проблемы : Что, если ? Что, если бы мы это сделали? или это ?
«Тот, кто больше не может останавливаться, чтобы удивляться и пребывать в благоговении, все равно что мертв; его глаза закрыты», Эйнштейн
- Ведите журнал Data Science: записывайте свои передовые методы, советы, проблемы, с которыми вы столкнулись, и способы их решения. Делая это, вы можете использовать свой собственный опыт, столкнувшись с подобной проблемой через 2-3 года, и избежать некоторых ошибок, которые вы сформулировали в своем дневнике. Кроме того, держите его отдельно от личного дневника, если он у вас есть: давайте не будем смешивать размышления об архитектуре модели илюбовные письма, пожалуйста😝
- Продолжайте Kaggle: Kaggle — отличное место, где можно узнать, какие на данный момент лучшие методы Data Scientist в разных областях. Так что либо участвуйте в соревнованиях, либо читайте различные обсуждения и модели, используемые для решения проблем.
- Продолжайте читать новейшие статьи. Будьте активным читателем и читайте о любой конкретной области машинного обучения. Это должно стать зависимостью. Если у вас нет этого автоматизма, я настоятельно рекомендую вам выделить 30–60 минут времени, посвященных чтению блогов, постов и исследовательских работ о машинном обучении. Это может быть поездка в поезде на работу или после обеда, пока вы перевариваете :) Вот мои ресурсы:
Для различных МО: Journal of Machine Learning Research; 2021bestpapers
Для глубокого обучения: DeepLearningResearch; Дорожная карта глубокого обучения;
Для методик: Информационный бюллетень TowardsDataScience; Пакетный бюллетень
Я надеюсь, что каким-то образом пролил свет на несколько ошибок, которые вы совершали бессознательно или были близки к совершению. Идея этого поста заключалась в том, чтобы поделиться ошибками, которые так часто приводят к неудачам и препятствуют нашему росту как специалистов по данным.
В завершение я хочу, чтобы вы запомнили (по крайней мере) эти 3 золотых правила:
- Ваша первая модель должна быть глупой базовой линией
- Никогда не применяйте модель или концепцию, не имея возможности объяснить ее коллеге.
- Всегда держите при себе журнал Data Science :)
Не стесняйтесь сообщить мне, какую ошибку я пропустил в разделе комментариев, и свяжитесь с нами через Linkedin!