
Логистическая регрессия используется практиками машинного обучения для прогнозирования категориальных переменных в отличие от непрерывных переменных, таких как цены на жилье. Он принадлежит к семейству GLM (общие линейные модели). Когда я впервые изучал и применял логистическую регрессию, меня часто сбивали с толку некоторые ее мелкие детали и причины, стоящие за ними. Я хочу использовать эту статью, чтобы выделить 5 вещей, которые, как я считаю, помогут вам понять теорию на ее фундаментальном уровне. Вам не нужно ничего запоминать о логистической регрессии после того, как вы поймете эти 5 вещей.
1. Вместо того, чтобы запоминать сигмовидную функцию, вам следует подумать о логарифмических шансах.
Многие онлайн-материалы начинают объяснение логистической регрессии с демонстрации сигмовидной функции.
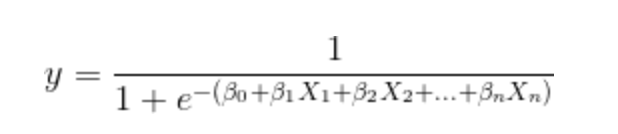
Объяснение того, почему сигмовидная диаграмма обычно звучит так: «при применении сигмовидной функции зависимая переменная y будет варьироваться от 0 до 1, следовательно, это похоже на вероятность результата». В этом объяснении нет ничего неправильного. Однако мне часто приходилось запоминать формулу, даже не зная, почему именно Sigmoid. Я думаю, что лучший способ думать о проблеме логистической регрессии - думать о шансах.
Шансы (отношение шансов) - это то, что понимает большинство людей. По сути, это соотношение между вероятностью получения определенного результата и вероятностью получения другого результата. Например, если вероятность выигрыша в игре составляет 60%, то проигрыш в той же игре будет противоположностью выигрыша, следовательно, 40%. Шансы на победу в игре составляют P (выигрыш) / P (проигрыш) = 60% / 40% = 1,5. Подставив много разных P (выигрыш), вы легко увидите, что шансы варьируются от 0 до положительной бесконечности. Когда мы применяем функцию натурального логарифма к вероятностям, распределение логарифм-коэффициентов изменяется от отрицательной бесконечности до положительной бесконечности. Положительное означает P (выигрыш) ›P (проигрыш), а отрицательное - противоположное. Распределение логарифма шансов во многом похоже на непрерывную переменную y в моделях линейной регрессии. Итак, для логистической регрессии мы можем сформировать нашу прогностическую функцию как:
Log (p / (1-p)) = beta0 + beta1X1 + beta2X2 +… + betanXn
При выполнении алгебраического преобразования приведенная выше формула будет выглядеть как сигмовидная функция, упомянутая ранее. y - это, по сути, вероятность получения определенного результата, то есть p (выигрыша), что мы, по сути, и хотим предсказать для категориального вывода.
2. Для предсказания вероятности можно использовать любой категориальный класс. Однако обычный способ - это прогноз по положительной категории, например, P (выигрыш).
Сигмовидная функция может быть неясной относительно того, какую категориальную переменную прогнозирует модель. Однако, если мы посмотрим на функцию логарифма шансов, предсказанная категория будет такой же, как категория, которую мы выбрали в качестве числителя в отношении шансов. Такие пакеты, как Scikit Learn, обычно возвращают вероятность для группы, которая установлена как 1 для двоичного прогнозирования. Например, если вы хотите предсказать вероятность выигрыша в игре, вы должны установить выигрыш в игре как метку 1 и проигрыш в игре как метку 0. Легкий способ запомнить это - установить любую группу, для которой вы хотите предсказать вероятность, как 1 перед запуском вашей модели.
3. Каждая выборка данных следует распределению Бернулли. Чем точнее ваш прогноз, тем ближе прогнозируемая вероятность к достоверной метке.
Вернемся к тому же примеру, выиграв или проиграв игру. Скажем, каждая выборка данных (каждая строка табличного набора данных) представляет участника, выигравшего или проигравшего в игре. Модель предсказывает вероятность того, что участник выиграет игру, поэтому P (выигрыш | X). Когда участник выиграл игру, модель должна предсказать высокую вероятность выигрыша, если модель близка к истине, и наоборот. Мы можем сравнить результаты нашего прогноза, построив следующую функцию:
P (выигрыш | X) * выиграл + P (проиграл | X) * проиграл
где P (выигрыш | X): прогнозируемая вероятность выигрыша в игре
выиграл: основная истина для победы в игре. Основная истина - 1, если участник выиграл, и 0 в противном случае.
P (проигрыш | X): прогнозируемая вероятность проигрыша в игре, такая же, как 1 - P (выигрыш | X)
проиграл: основная правда о проигрыше. Основная истина - 1, если участник проиграл, в противном случае - 0.
Каждый участник либо выиграл игру, либо проиграл, и чем ближе наш прогноз к метке наземной истины, тем больше результат функции. Эта функция элегантно и надежно описывает всевозможные результаты игры и делает прогноз для каждого участника сопоставимым.
4. Максимизация функции логарифмического правдоподобия аналогична минимизации кросс-энтропии функции стоимости
Этот пункт является своего рода продолжением пункта 3. В пункте 3 мы объяснили, как измерить вероятность для каждой выборки, этот пункт состоит в том, чтобы объяснить, как оценить общую вероятность модели прогнозирования. Мы берем совместную вероятность каждой выборки данных.
Суммирование намного проще, чем умножение, а также более стабильный результат. Мы берем натуральный логарифм для совместной вероятности, чтобы преобразовать умножение вероятностей каждой выборки в суммирование зарегистрированных вероятностей. Функция общего логарифма правдоподобия (для бинарной категориальной модели прогнозирования) выглядит следующим образом:

где yi представляет каждую основную метку истинности для категории, для которой мы прогнозируем. p (yi) - прогнозируемая вероятность той же категории.
Максимизация функции логарифмического правдоподобия, как указано выше, то же самое, что минимизация отрицательной функции логарифмического правдоподобия. Функция отрицательного логарифмического правдоподобия идентична кросс-энтропии для двоичных предсказаний, ее также называют логарифмической потерей.
5. Для логистической регрессии можно использовать регуляризацию Ridge (L2) и Lasso (L1).
Так же, как регуляризация для линейной регрессии, функция регуляризации L2 или L1 может быть добавлена к функции потерь журнала. Тот же итерационный процесс, такой как градиентный спуск, может применяться для минимизации функции стоимости с добавленной регуляризацией.
Я надеюсь, что эти 5 важных вещей помогли вам понять суть логистической регрессии. Я думаю, что после того, как я прояснил эти 5 вещей, я смог применить мысли о прогнозном моделировании к другим типам моделей машинного обучения.