
Этот пост в блоге предназначен для изучения процесса очистки данных и демонстрации методов исследовательского анализа набора данных о преступлениях в Чикаго.
Исходный набор данных содержит около 7 миллионов строк с 2001 по 2017 год; однако для нашего анализа мы выбрали набор данных с 2012 по 2017 год, содержащий около 1,4 миллиона строк и 23 объекта.
Очистка данных:
Прежде чем мы начнем анализ набора данных, мы сначала предварительно обработаем или очистим наш набор данных, чтобы подготовить его к следующему процессу анализа данных.
- Удаление столбцов. На первом этапе мы удалили несколько ненужных столбцов, которые не помогают нам в нашем анализе. К таким столбцам относятся "Безымянный: 0", "ID", "Номер дела" и т. д.
- Добавление столбцов. Еще одно преобразование включает в себя извлечение дня, месяца, года и времени из даты произошедшего инцидента. Это может помочь нам определить годовые и еженедельные тенденции в уровне преступности. В результате мы добавили следующие столбцы:
- Год
- Месяц
- День
- Час
- Минута
- Второй
После добавления этих столбцов мы удалили столбцы Дата и Дата обновления, чтобы избежать повторения в столбцах.
3. Отбрасывание значений NaN.Этот шаг включал проверку полноты записей и обработку отсутствующих значений. Мы удалили некоторые пропущенные значения, если они были в нашем наборе данных.
4. Факторизация столбцов. Мы факторизовали некоторые столбцы, такие как «Описание местоположения», «Блок», «IUCR», «Описание», «Код ФБР» и «Местоположение». Идея заключалась в том, чтобы получить числовое представление столбцов, чтобы помочь нам в дальнейшем анализе.
Исследование данных:
- Наиболее часто встречающийся тип преступления:
Чтобы начать исследование данных, мы сначала проанализировали количество преступлений по основным типам. Мы отмечаем, что Кража и Нанесение батареек — два самых известных преступления в 2012–2017 годах.
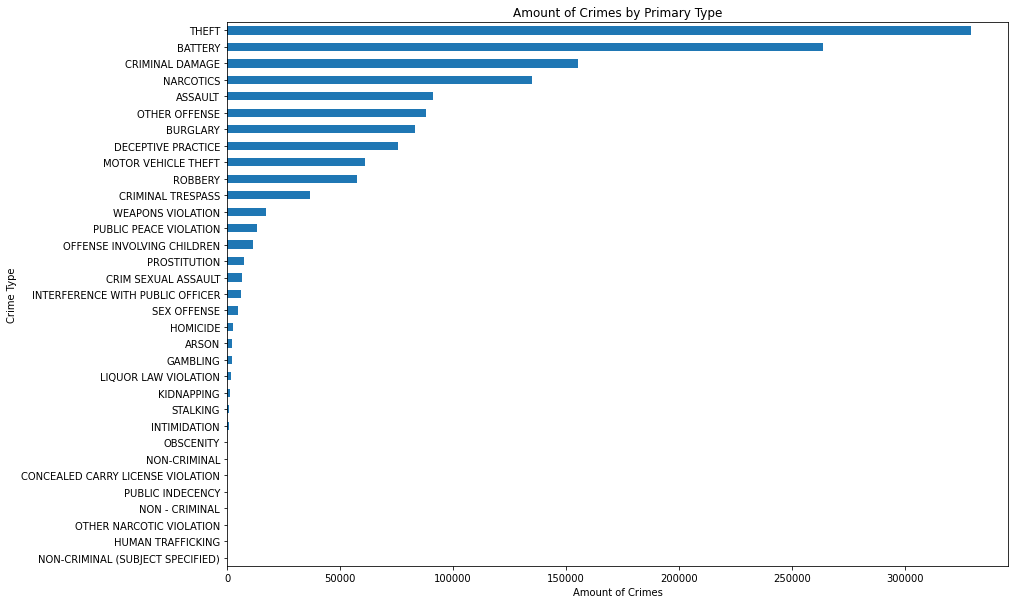
Чтобы сделать его более ясным и понятным, мы снова нанесли на график только классы со значительным уровнем преступности за период 2012–2017.

Теперь давайте посмотрим на это с точки зрения отношений на круговой диаграмме.

Опять же, мы наблюдаем, что Кража — самый распространенный тип преступления, тогда как Ограбление — реже всего.
2. Основные преступления по годам:
Мы видели основные преступления за пять лет (2012–2016), но теперь давайте проанализируем основные преступления по годам с 2012 по 2016 год. Мы построили несколько графиков, которые помогли нам в извлечении желаемых результатов:


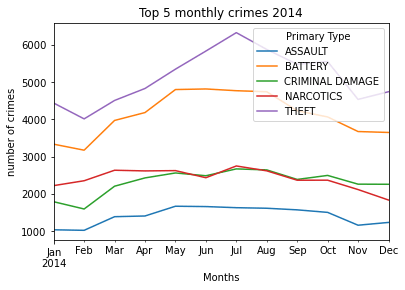


Мы заметили, что Кража всегда была главным, а Нанесение побоев вторым типом преступлений в Чикаго с 2012 по 2016 каждый месяц. Точно так же из еженедельных и ежедневных графиков уровня преступности мы видим более или менее одинаковую тенденцию за пять лет.
3. Уровень преступности за последние годы:
Очень важно проанализировать уровень преступности за период с 2012 по2017 года.Мы построили тепловую карту, чтобы проанализировать изменение уровня преступности в Чикаго за эти годы и месяцы.
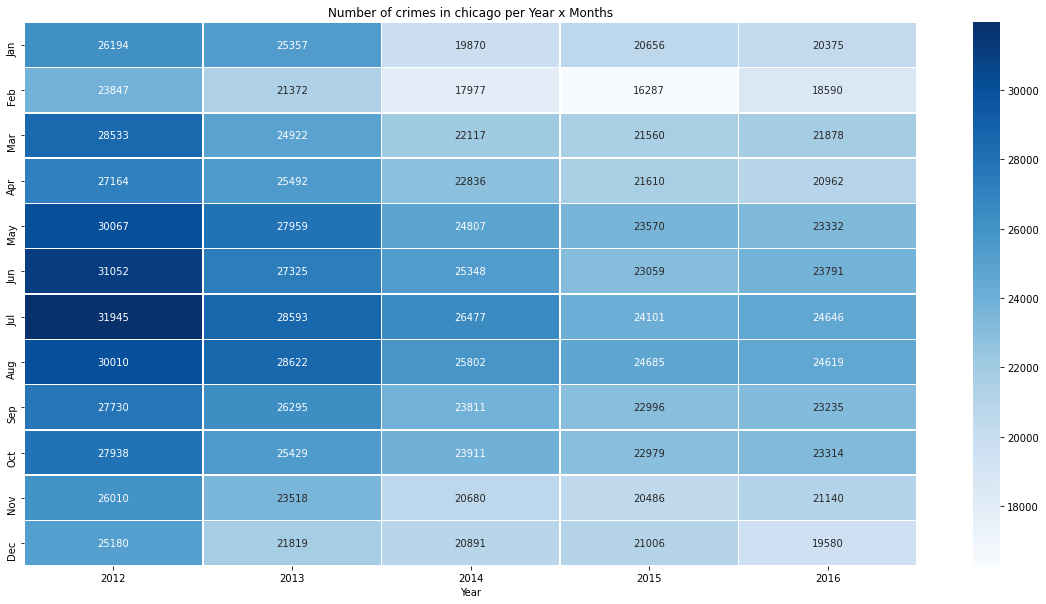
Мы видим, что синий оттенок в 2012 году темнее, чем в 2016 году, что ясно указывает на снижение количества преступлений по сравнению с 2012 годом. –2017.
Давайте проанализируем это, используя другую гистограмму, чтобы увидеть уровень преступлений за эти годы:
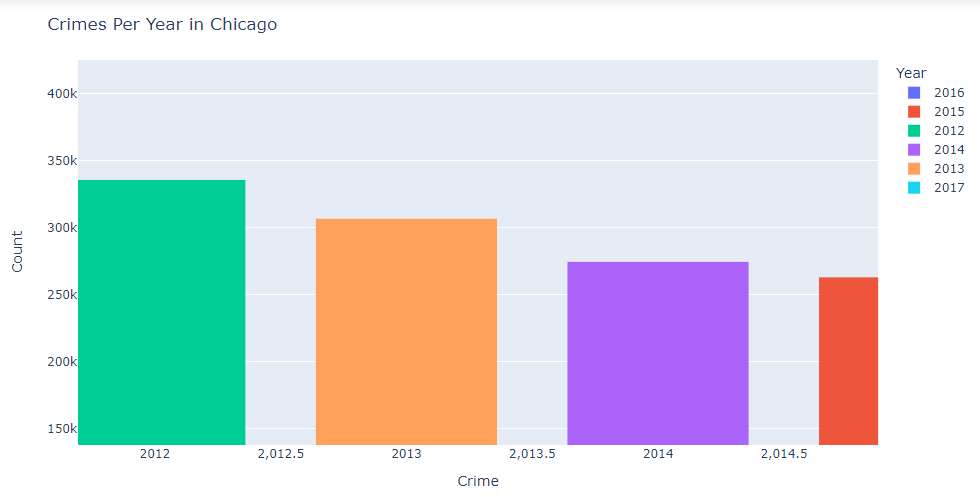
Чтобы увидеть это под другим углом зрения с точки зрения соотношения, мы также создали круговую диаграмму, отображающую соотношение преступлений за пять лет в Чикаго. Мы видим, что коэффициент преступлений в 2012 году был выше, чем в любой другой год, а в 2017 году было наименьшее количество преступлений в Чикаго.

4. Соотношение арестов к преступлению:
Мы построили еще один график, показывающий уровень арестов по основным видам преступлений в Чикаго. Удивительно видеть, что воровство, которое является более распространенным преступлением, имеет наименьшее количество арестов среди других преступлений.

5. Соотношение арестов и неарестов:
Далее мы проанализировали частоту арестов и неарестов за пять лет, с 2012 по 2017 год, и из приведенной ниже гистограммы ясно видно, что примерно в 70 % преступлений виновными были не арестован.

6. Количество арестов:
Теперь давайте нанесем на график количество арестов за период с 2012–2017 и проверим, какую информацию мы получаем из графиков.

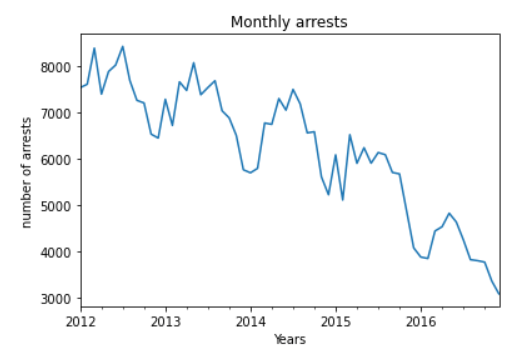

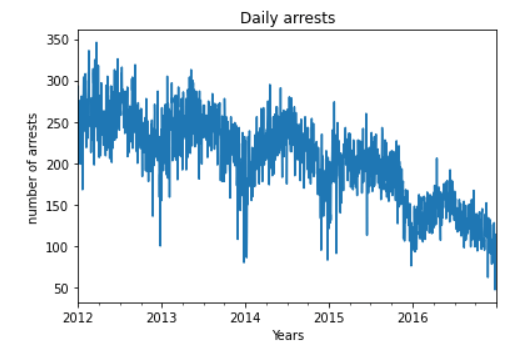
Мы видим, что количество арестов за последние годы значительно сократилось. Независимо от того, анализируем ли мы этот показатель на годовой, месячной, еженедельной или ежедневной основе, мы видим, что в целом количество арестов заметно снижается между 2012 и 2017. Удивительно, что количество арестов резко сократилось, но количество преступлений не сократилось такими же темпами.
7. Преступления, связанные с домашним насилием:
Насилие в семье в основном связано с близкими членами семьи, живущими вместе. Проанализировав уровень преступности в Чикаго за несколько лет, давайте построим график уровня домашнего насилия за период 2012–2017, чтобы увидеть, как он менялся за эти годы.
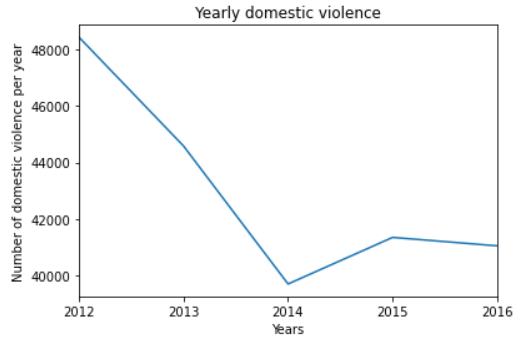



Из приведенных выше графиков видно, что уровень домашнего насилия незначительно снизился с 2012по2016, а затем резко упал в сильный>2017.
8. Количество преступлений по местонахождению:
Другим важным фактором в нашем процессе анализа данных является рассмотрение количества преступлений по местам в Чикаго. Крайне важно знать, где произошли эти преступления? Давайте проанализируем график ниже:

Из гистограммы выше видно, что на улицах чаще совершаются преступления, чем в других местах. Интересно и прискорбно видеть, что жилая недвижимость и квартиры в Чикаго тоже не застрахованы от преступлений.
9. Место преступления:
Места совершения преступлений показаны на карте ниже:
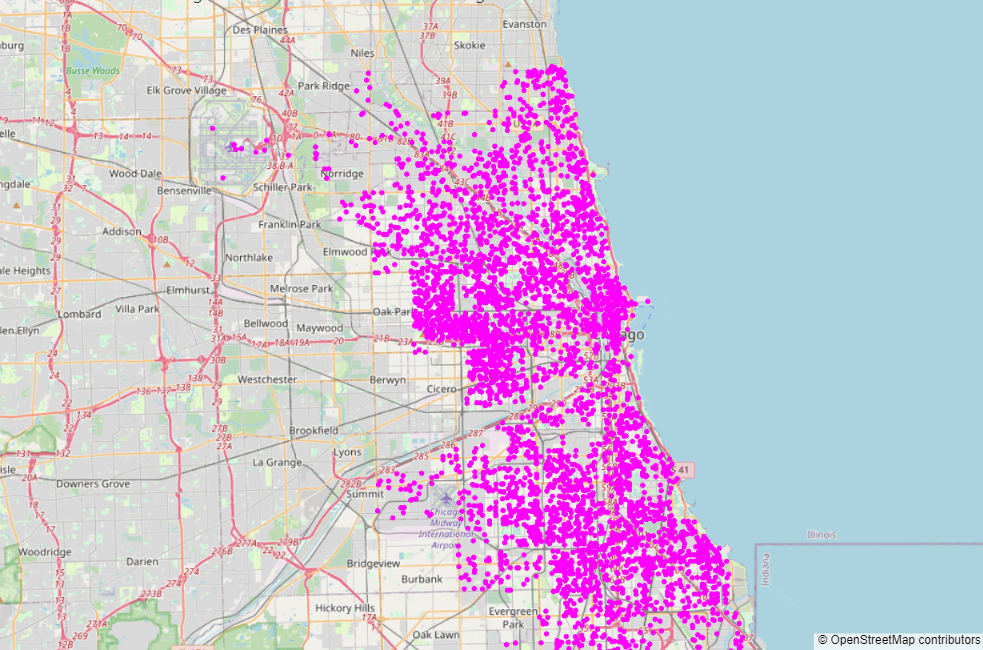
На приведенной выше карте видно, что преступления совершались почти везде в городе Чикаго, и нет конкретного места, где чаще всего совершались преступления.
Модель прогнозирования преступлений с использованием классификации KNN:
После очистки и анализа набора данных теперь мы разработаем модель с использованием классификации KNN.Но мы начнем, давайте сначала проанализируем, какие функции в большей степени влияют на целевую переменную. Мы сохраним только их и опустим другие неважные функции. Мы используем метод корреляции Пирсона для анализа важности функций. Давайте проследим это на следующем графике тепловой карты:

Здесь мы видим, что черты, выделенные темно-красным цветом, более значимы, чем те, что выделены светлым оттенком. Например, в столбце «Основной тип» по оси x значения IUCR и Description имеют значение 0,42, тогда как FBI Код имеет значение 0,9. Это означает, что FBI Code — очень важная функция, которая поможет нам в наших прогнозах.
Теперь давайте продолжим и разделим наш набор данных с помощью класса sklearn train_test_split в соотношении 80 % обучающих данных и 20 % данных тестирования. После разделения мы хотим обучить нашу модель с помощью классификатора KNN с фиксированным значением 5 ближайших соседей.
#Importing Libraries from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report from sklearn.metrics import accuracy_score from sklearn.metrics import f1_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn import metrics #Split dataset to Training Set & Test Set tst = 0.20 trn = 0.80 x, y = train_test_split(df, test_size = tst, train_size = trn, random_state= 3) xf_train = x[Features] #Features to train yf_test = y[Features] #Features to test xt_train = x[Target] #Target Class to train yt_test = y[Target] #Target Class to test # K-Nearest Neighbors neigh = 5 knn_model = KNeighborsClassifier(n_neighbors=neigh)
Теперь мы собираемся сопоставить нашу модель KNN, а затем предсказать типы преступлений по тестовым данным. Вот код для этого:
# Model Training knn_model.fit(X=xf_train, y=xt_train) # Prediction pred = y[Features] result = knn_model.predict(pred)
Давайте теперь оценим нашу модель и посмотрим на оценки различных показателей измерения, таких как точность, отзыв, точность, оценка f1 и т. д.
# Model Evaluation
acc = accuracy_score(yt_test, result)
print("Accuracy: ", acc)
rec = recall_score(yt_test, result, average="weighted")
print("Recall : ", rec)
pre = precision_score(yt_test, result, average="weighted")
print("Precision : ", pre)
f1 = f1_score(yt_test, result, average='micro')
print("F1 Score: ", f1)
После запуска приведенной выше ячейки мы получили удивительную точность 99 %. Более того, другие показатели также дают оценку 99%.

Вот и все, поздравляем, мы успешно разработали нашу модель прогнозирования преступлений с использованием метода классификации KNN.
Заключение:
В заключение мы сначала проанализировали тенденции преступной деятельности в Чикаго с 2012 по 2017. Мы увидели, что кражи и нанесение побоев были самыми известными типами преступлений. Более того, улицы оказались самым небезопасным местом с точки зрения количества преступлений. Также мы наблюдали небольшое снижение количества преступлений с 2012 по 2017 год, но количество арестов, к сожалению, уменьшилось значительно за эти годы. Во-вторых, мы разработали модель прогнозирования типа преступника, используя метод классификации KNN. Окончательная точность нашей модели составила 99%.