
Соавтор AMPLab о том, куда движутся большие данные и почему Spark так велик
Майкл Франклин - профессор Калифорнийского университета в Беркли и содиректор (и соавтор) популярного там AMPLab (AMPLab - сокращение от Алгоритмы, машины и люди). Дико популярный фреймворк для больших данных Apache Spark возник из AMPLab, как и некоторые другие популярные технологии.
В Части 1 этого отредактированного интервью с Франклином он обсуждает, как возникла AMPLab, почему Spark завоевал популярность и какие проблемы он и его коллеги будут решать в следующий раз.
Вторая часть интервью, которая скоро будет опубликована, посвящена мыслям Франклина об индустрии баз данных, которой он сосредоточил большую часть своего внимания в начале своей карьеры.
МАСШТАБ. Не могли бы вы начать со своей личной истории для незнакомых?
МАЙКЛ ФРАНКЛИН: Я по образованию специалист по базам данных. В самом начале своей карьеры я в качестве программиста участвовал в создании одной из самых первых систем баз данных с массовым параллелизмом. Такого рода я увлекся исследованиями, получением удовольствия и проблемой попытки мыслить немного дальше - или, может быть, более чем немного дальше - того, что в настоящее время делает отрасль. Выяснение, какие новые методы и новые методологии вам нужно придумать для решения более серьезных проблем, чем люди решают в настоящее время.
После работы над параллельными системами баз данных я решил вернуться в аспирантуру и получить докторскую степень. В основном я работал над распределенными системами и пытался понять, как оптимизировать распределенную память, особенно для приложений баз данных, а также как обеспечить хорошую отказоустойчивость в распределенной среде.
Когда это было?
Это было в начале 90-х.
После получения докторской степени я устроился профессором. На самом деле, мои исследования в ранние годы работы в качестве преподавателя касались этих направлений, параллельных и распределенных систем баз данных. Когда я приехал в Беркли, вокруг Интернета вещей и сенсорных сетей было много ажиотажа, поэтому мы начали изучать, как обеспечить управление данными в сильно распределенных, высокодинамичных средах, таких как сенсорные сети.
Я также много работал над потоковой обработкой в реальном времени. Частично это привело к тому, что я вместе с одним из моих студентов основал компанию, которая занималась обработкой запросов к базе данных потоковой передачи. У нас была компания Truviso, которая на самом деле стала пионером концепции того, что мы называем потоковой системой реляционной базы данных, где в рамках единой системы вы можете работать с потоковыми данными, а вы можете работать с сохраненными данными.
Философия заключалась в том, что все данные начинают свою жизнь как потоковые данные. Он перемещается от того места, где был создан, туда, где он будет обрабатываться. Данные действительно перестают двигаться, только когда вы их сохраняете. Идея заключалась в том, чтобы создать систему, в которой можно было бы объединить обработку данных в движении и данных в состоянии покоя, и это действительно то, что Truviso и сделала.
В конечном итоге Truviso была приобретена Cisco и, насколько мне известно, в настоящее время является частью технологического стека того, что они называют подключенной аналитикой, что лежит в основе ряда их инициатив в области Интернета вещей. Там он также используется для сетевой аналитики.
«Я понял, что можно… заставить специалистов по системам работать на людей, занимающихся машинным обучением, чтобы попытаться решить проблему масштабируемого машинного обучения. Это было действительно началом AMPLab ».
Объединение алгоритмов, машин и людей в AMPLab
Как вы начали работать с AMPLab?
Чтобы начать работу с Truviso, я взял двухлетний отпуск из Беркли, что делают многие преподаватели. Пока я уезжал в тот двухлетний отпуск, в период 2007–2008 годов, если вы вообще разговаривали с какими-либо клиентами, вы не могли не заметить, что все только начинали собирать все больше и больше данных, все быстрее и быстрее. . И они пытались выяснить, как они собираются поступать со всей этой информацией, которую собирали, и как они собираются извлечь из этого пользу.
Когда я вернулся в Беркли после того отпуска, было совершенно ясно, что именно в этой области я хотел бы работать. Это то, что люди называют аналитикой больших данных; Я не уверен, что этот термин использовался именно тогда. Но так случилось, что [соучредитель Databricks] Ион Стойка, один из моих коллег здесь, тоже занимался бизнесом, и его компания фактически использовала много данных. Они собирали много данных, потому что занимались распространением видео и использовали огромные объемы данных для принятия разумных решений о том, как маршрутизировать и как передавать видео. Итак, Ион, я и некоторые другие преподаватели начали разговаривать, и стало ясно, что как тема исследования, аналитика больших данных будет иметь большое значение.
Нам повезло, что в то время здесь, в Беркли, реализовывался проект под названием RADLab - сокращение от надежные и распределенные вычисления - это был проект облачных вычислений, действительно изучающий, как вы используете машинное обучение. для автоматического предоставления, обслуживания и запуска больших компьютерных систем. Таким образом, в некотором смысле люди, занимающиеся машинным обучением, были объединены для работы с людьми, занимающимися вычислительными системами, чтобы помочь решить эту проблему, а в некотором смысле люди, занимающиеся машинным обучением, были своего рода работой для людей, занимающихся компьютерными системами.
Я понял, что вы можете взять эти отношения и перевернуть их - сохранить команду вместе, удержать людей, занимающихся машинным обучением, и специалистов по системам, работающими вместе, но теперь в этом случае есть системы, которые люди вроде бы работают, чтобы люди машинного обучения могли попробовать для решения масштабируемого машинного обучения. Это было действительно началом AMPLab.

Людям действительно нравится уделять внимание анализу данных в рамках машинного обучения, но тот факт, что мы оптимизировали системы для этого в нужном масштабе, также важен.
Всегда был огромный разрыв. Машинное обучение в основном рассматривало довольно небольшие данные и способы создания более эффективных алгоритмов обучения, которые обладали бы доказываемыми свойствами, касающимися сходимости, правильности и тому подобного. Большая часть работы по масштабируемому управлению данными была сосредоточена на довольно простой аналитике - подсчете и агрегировании данных. Поэтому возникла необходимость объединить эти две вещи для масштабной расширенной аналитики.
Каким образом AMPLab удалось стимулировать такие популярные исследования?
Наше несправедливое преимущество в AMPLab заключалось в том, что практически в любой другой академической или даже промышленной лаборатории будет группа машинного обучения - или даже больше одной - и они будут работать над своими проблемами машинного обучения. Будут системные группы, и они будут работать над системными проблемами. Они, по большому счету, друг с другом не разговаривают.
Благодаря этому проекту RADLab у нас появилась группа ведущих в мире специалистов по машинному обучению и группа ведущих мировых специалистов по системам, которые проработали вместе достаточно долго, чтобы как бы говорить на языке друг друга. Это было огромным преимуществом, которое мы могли использовать, пытаясь проводить масштабируемую аналитику. Это была большая часть быстрого старта AMPLab.
Еще одна интересная особенность AMPLab - это ее междисциплинарный характер, по крайней мере, в области компьютерных наук. У нас есть специалисты по машинному обучению, специалисты по системам, а я специалист по базам данных. У нас есть специалисты по безопасности, люди, работающие в сети, люди, взаимодействующие с людьми. Так что он действительно охватывает широкий спектр компьютерных наук. Это настоящее сотрудничество, когда люди сидят вместе, они работают вместе, лаборатория находится в одном физическом пространстве, поэтому она оптимизирована для взаимодействия в этих разных областях.
Еще одна вещь, которую мы сделали, изначально по необходимости, заключалась в том, что в самом начале мы довольно тесно взаимодействовали с промышленностью. Когда мы запускали лабораторию, мы намеревались полностью профинансировать ее за счет средств отрасли. Мы не ожидали получить для этого государственного финансирования. IBM действительно была очень заинтересована и изначально выделила небольшой посевной грант.
«Мы стараемся выходить за рамки повседневных проблем, с которыми сталкиваются люди в отрасли, но отчасти причина того, что мы смогли оказать такое прямое влияние, - это постоянное взаимодействие с людьми в отрасли».
Google действительно был первым местом, куда мы обратились. Мы рассказали им о нашем видении интеграции алгоритмов, а именно машинного обучения и статистической обработки; машины с точки зрения облачных вычислений и кластерных вычислений; и людей с точки зрения краудсорсинга и человеческих вычислений, и собрать эту команду для этого. Google очень обрадовался этому и взял на себя многолетнее обязательство по поддержке лаборатории, после чего мы начали работать.
Сейчас у нас 30 промышленных спонсоров, и мы встречаемся с компаниями-спонсорами в течение года. Но у нас есть две основные встречи в год, на которых мы показываем им все, что мы делаем, и получаем очень подробные отзывы от некоторых из их лучших технических специалистов, где они разговаривают с нашими студентами, разговаривают с нашими преподавателями и высказывают свое мнение о направлениях, которые мы '' повторять. Они рассказывают нам о вещах, которые они видят в своих мирах, и которые хотели бы, чтобы мы изучили, так что мы лучше понимаем, в чем заключаются некоторые из проблем в отрасли.
По большому счету, они довольны тем, что мы возглавляем интеллектуальные направления лаборатории. Они не заинтересованы в том, чтобы давать нам очень подробные инструкции, а скорее хотят видеть, к чему мы стремимся, потому что как университет у нас во многих отношениях меньше ограничений, чем у них.
Это будущая модель вашей исследовательской лаборатории? Если я посмотрю на Mesos, Spark и все, что выходит из AMPLab, они коммерчески ценны, возможно, из-за связи между академическим сообществом и промышленностью.
Я так думаю. Наша работа во многом зависит от того, что происходит в отрасли и каковы нерешенные проблемы в отрасли. Мы стараемся не ограничиваться повседневными проблемами, с которыми сталкиваются люди в отрасли, но отчасти причина того, что мы смогли оказать такое непосредственное влияние, - это постоянное взаимодействие с людьми в отрасли.
Еще мы смогли сделать, это то, что пока все это происходило, федеральное правительство начало интересоваться большими данными. В конечном итоге, в результате долгого процесса, AMPLab был выбран Национальным научным фондом в качестве так называемого проекта Expeditions in Computing. Это, наряду с некоторым другим финансированием, которое мы получаем от DARPA и Министерства энергетики, означает, что наш профиль сейчас составляет примерно половину государственного финансирования и половину отраслевого финансирования. Это идеальное сочетание по многим причинам.
«Решение перейти на Scala было невероятно рискованным, и я думаю, что в то время, если бы мы осознали, на какие ставки мы играем, это был бы интересный вопрос, действительно ли мы это сделали бы».
Apache Spark как революционер в области больших данных
Является ли Spark самой важной разработкой AMPLab на данный момент?
С точки зрения того, что производила лаборатория, в целом это довольно значительный труд. В нем, вероятно, задействовано около 80 человек, в том числе от 40 до 45 аспирантов и докторов наук, так что это довольно большая исследовательская работа.
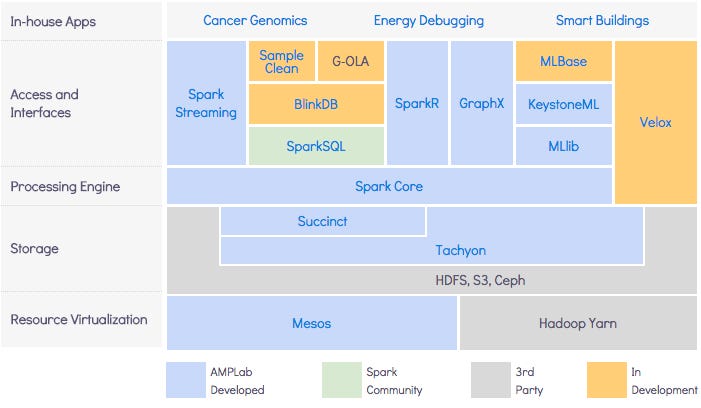
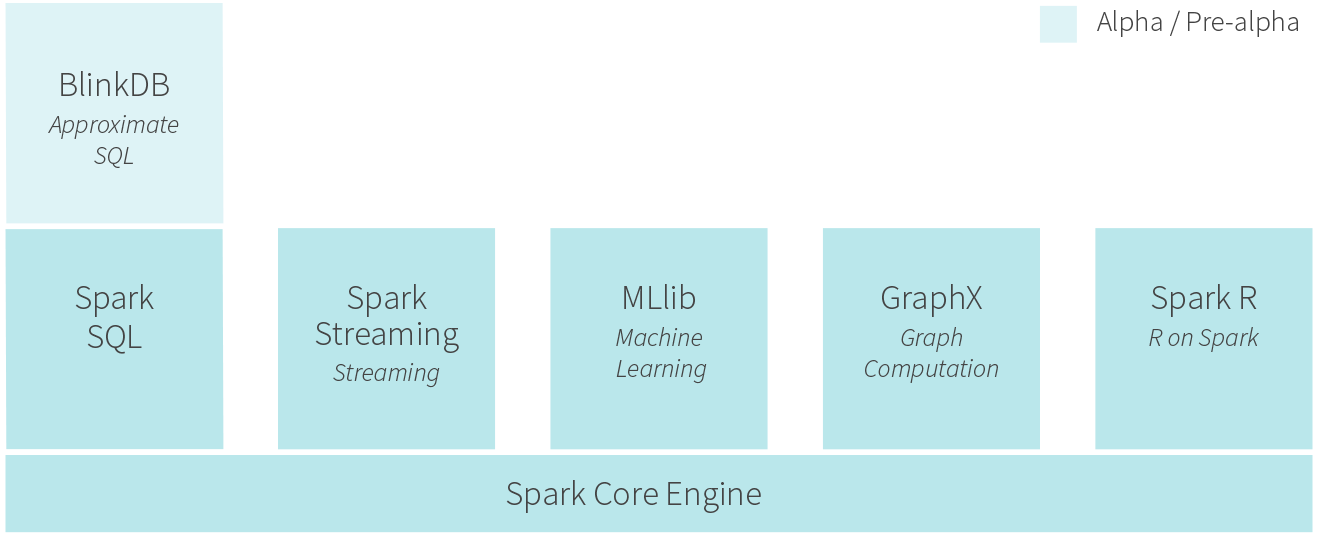
И многое из того, что мы делаем, в конечном итоге помещается в создаваемую нами систему с открытым исходным кодом под названием Berkeley Data Analytics Stack, BDAS - это произносится как задира. Чтобы проверить идеи, мы хотим их реализовать, а чтобы действительно реализовать их, мы помещаем их в контекст этой более крупной системы, чтобы они действительно решали проблемы.
Если вы посмотрите на стек BDAS, там есть куча всего. Мезос - его часть. Mesos действительно выросли из этого более раннего проекта под названием RADLab. Интересно, что Spark начался в RADLab, но это было в то время, когда шли все разговоры о создании AMPLab, поэтому мы действительно считаем Spark первым проектом AMPLab.
Фактически, трудно конкурировать с влиянием, которое Spark оказал за короткое время с момента его создания. Это действительно в значительной степени заняло экосистему больших данных с точки зрения механизмов параллельной обработки.
Очевидно, что Spark на сегодняшний день является тем, что оказало наибольшее внешнее влияние, но появилось много вещей, которые оказали влияние. Система распределенного хранилища Tachyon получает огромное количество поклонников, и вокруг нее развернулась компания. Затем стек машинного обучения, который мы создали - MLLib и конвейеры, которые мы выполняли, - многие из них вызывают большой интерес и растут.
То, что происходит сейчас в лаборатории, связано с тем, что мы выработали эту способность создавать полезные системы, которые действительно решают проблемы, в общем и целом, когда студенты работают над программным обеспечением и выпускают его, люди берут его и пробуют.
Например, у нас было несколько аспирантов в качестве классного проекта, посвященного тому, как бы вы выполняли программы, написанные на языке статистического программирования R, который традиционно выполняется на одной машине. Как бы вы запустили это в кластере Spark? Они работали над этой проблемой, они решили ее часть (не всю), они назвали это SparkR, они разместили на GitHub, и люди начали его использовать. Теперь SparkR был подхвачен рядом компаний, у него есть открытый исходный код, и это реальная часть экосистемы Spark.
По мере продолжения проекта все больше и больше вещей, которые мы делаем, начинают оказывать влияние, и часть привлекательности экосистемы Spark оказывается просто широтой возможностей, которые вы можете сделать. Существует множество систем, нацеленных на обработку в реальном времени, на обработку в стиле MapReduce или на обработку реляционных запросов. Spark делает все эти вещи довольно хорошо, и, как мне кажется, способность делать все это в единой системе - вот что действительно движет внедрением Spark.
«Hadoop MapReduce действительно пробудил аппетиты людей и заставил их понять, что параллельная обработка предназначена не только для людей в суперкомпьютерных центрах, но и может использоваться простыми смертными».
Помимо скорости и полезности, насколько вы объясняете успех Spark тем, что он удобен для разработчиков?
Оказывается, он невероятно удобен для программистов и разработчиков. Решение перейти на Scala было невероятно рискованным, и я думаю, что в то время, если бы мы осознали, на какие ставки мы играем, это был бы интересный вопрос, действительно ли мы это сделали бы. Как исследовательский проект, похоже, что люди, создающие систему, действительно были в восторге от Scala. Они увидели преимущества его использования и захотели этого. И я думаю, что преподаватели в целом сказали: «Эй, если ты это пишешь, и это то, что ты хочешь делать, это звучит нормально».
Удивительно то, что Spark не только не сдерживал внедрение Spark, но и благодаря своей простоте использования, лаконичности программ, гибкости и доступности на самом деле помогает ему вывести Scala на широкую публику, что является действительно интересным результатом.
Было принято множество решений, которые были приняты явно или просто в процессе работы, и я не уверен, что если бы мы поняли, что строим инфраструктуру программного обеспечения для работы с большими данными следующего поколения для всего мира, мы бы так и не приняли. Scala, безусловно, был одним из них. Идея помещения всех этих различных модальностей в одну и ту же систему - тот факт, что вы можете обрабатывать одни и те же данные как таблицу, как график, как фрейм данных, - это совсем другое.
Как вопрос исследования, это интересно. Сможете ли вы создать систему, которая объединяет все эти различные представления данных и при этом обеспечивает хорошую производительность? Это фантастический исследовательский вопрос.
Непонятно, начинали ли вы проект, цель которого - добиться широкого распространения, как вы поступили бы. Фактически, это одна из основных причин, по которой Spark завоевывает популярность, потому что вы можете использовать его всеми этими разными способами, и он действительно хорошо работает всеми этими разными способами.
Это было идеальным решением после того, как Hadoop пробудил у всех аппетиты.
Мы в большом долгу перед Hadoop. Во-первых, мы по-прежнему широко используем файловую систему Hadoop. Но кроме того, Hadoop MapReduce действительно пробудил аппетиты людей и заставил их понять, что параллельная обработка предназначена не только для людей в суперкомпьютерных центрах, но и может использоваться простыми смертными. Это было отличное начало, но этого просто не хватало во многих отношениях, и Спарк был вынужден оседлать эти фалды.
Многое из того, что выходит из AMPLab, включая Spark и Tachyon, основано на обработке в памяти. С коммерческой точки зрения, наступит ли момент, когда цена на оперативную память должна резко упасть для принятия на вооружение?
Я думаю, что это неправильное понимание Spark во многих отношениях. Spark оптимизирован для разумного использования памяти, и, конечно же, когда все умещается в памяти, это тогда, когда это лучше всего. Но с самых первых дней работы над проектом мы знали, что будут случаи, когда данные, о которых вы заботитесь, не поместятся в памяти, и идея заключалась в том, что вы хотите, чтобы система постепенно деградировала.
В худшем случае, если все умещается в памяти, все работает отлично, но в ту минуту, когда вы увеличиваете объем данных чуть больше памяти, производительность падает. Мы проектировали с самого начала, чтобы этого не произошло.
Я думаю, что сейчас действительно происходит то, что мы идем другим путем. Мы чувствуем, что добились большого прогресса в горизонтально масштабируемых архитектурах, поэтому, если вы получаете больше данных, вы покупаете больше серверов и получаете больше памяти, и все просто продолжает масштабироваться таким образом. Теперь, когда проблема в значительной степени решена, мы возвращаемся назад и изучаем производительность даже одного узла.
Происходит проект под названием Project Tungsten. Это усилие сообщества Spark, которое больше сосредоточено на том, что происходит на одном сервере. Сообщество Spark - не столько в лаборатории, сколько сообщество Spark - действительно смотрит: «Хорошо. Теперь, как нам вернуться и начать атаковать некоторые из проблем производительности одного узла, которые во многих случаях на самом деле проще, чем проблемы горизонтального масштабирования ».
«Это всегда маятник, когда вы переходите от высокораспределенного к более централизованному и обратно. Я предполагаю, что произойдет еще одно колебание маятника, когда нам действительно нужно начать думать о том, как распределять обработку по глобальной сети . »
Будущее обработки данных находится на границе сети
Что, я думаю, будет следующим важным событием, которое произойдет в больших данных, будь то из AMPLab или где-то еще?
По сути, мы пытаемся сделать несколько вещей. Первое, что мы пытаемся сделать, - это упростить использование машинного обучения. Мы хотим сделать это для машинного обучения точно так же, как вам не обязательно понимать алгоритмы движка базы данных для написания приложения с базой данных. Мы хотим, чтобы простые смертные могли выполнять расширенную аналитику и делать прогнозы без необходимости быть экспертами в машинном обучении или знать, как писать алгоритмы для машинного обучения.
В этом отношении мы следуем руководству по обработке запросов к базе данных. Итак, в системе базы данных у вас есть библиотека операторов, которые работают с данными; у вас есть язык для создания планов запросов, который затем берет эти операторы и объединяет их, чтобы фактически дать ответ; а затем у вас есть дополнительный язык, на котором программист может писать, где они указывают ответ, который они хотят получить, но не обязательно, как получить этот ответ. Есть процесс компиляции, который проходит через все эти уровни. Мы пытаемся сделать это для машинного обучения.
На уровне оператора у нас есть MLLib. На уровне конвейера у нас есть Keystone ML, еще одна конвейерная система, уже присутствующая в Spark. Кроме того, у нас будет декларативный интерфейс, чтобы люди могли сказать: «Эй, вот что я хочу предсказать», а затем это будет скомпилировано, оптимизировано и выполнено системой. Я думаю, это сильно изменит правила игры, если мы сможем это сделать.
Еще одна вещь, которую мы пытаемся сделать, - это выполнить обещание, данное AMPLab, когда мы только начали, то есть часть людей. Мы работаем над тем, как интегрировать ручную обработку данных с другими функциями, необходимыми для анализа больших данных.
«Есть просто среды и приложения, в которых вы не можете терпеть задержки. Вы не можете мириться с риском потери данных или даже временного сбоя связи, и вам нужно реагировать на окружающую среду в режиме реального времени ».
Я думаю, что большая часть работы, которую мы там делаем, может иметь реальное влияние, потому что реальность такова, что есть еще много вещей, в которых вы действительно хотите, чтобы люди смотрели данные, чтобы убедиться, что все в порядке. Как вы внедрите такую обработку в систему?
Что касается дальнейшего развития событий, как я уже говорил ранее, когда я впервые приехал в Беркли, люди были действительно в восторге от этих широко распределенных систем, в которых у вас были всевозможные интеллектуальные возможности в сети - у вас были датчики, у вас была обработка. на краю сети.
Это всегда маятник, когда вы переходите от высокораспределенного к более централизованному и обратно. Я предполагаю, что произойдет еще одно колебание маятника, когда нам действительно нужно начать думать о том, как распределять обработку по глобальной сети. с очень изменчивыми и ненадежными компонентами в реальном мире, которые взаимодействуют с физическим миром и с людьми в режиме реального времени. Я думаю, что для этого людям нужно решить множество проблем. Вот о чем я буду думать.
Итак, по сути, мы отказываемся от нынешней облачной модели «глупых» устройств, отправляющих данные обратно в центральную базу данных для обработки?
Да, понимание, где должна происходить обработка. Ясно, что если вы сможете сделать это снова в центре, это будет проще всего во многих отношениях, но есть только среды и приложения, в которых вы не можете терпеть задержку. Вы не можете мириться с риском потери данных или даже временного сбоя связи, и вам необходимо реагировать на окружающую среду в режиме реального времени. Я считаю, что такой распределенный интеллект - сложная и важная проблема.
Насколько это проблема с данными, а какая с кремнием?
Я думаю, это проблема с данными. Я думаю, что платформы уже достаточно мощные. Определенно существуют проблемы, связанные с энергоснабжением, коммуникациями и тому подобным, но, в общем, я думаю, что дело доходит до того момента, когда возникает проблема с данными.