
Прежде всего, благодарим Mattermark за то, что нас устроили, и Встречу по машинному обучению в SF Bay Area за приглашение Bonsai выступить на прошлой неделе. Они были дружной группой людей, и Сара Катандзаро из Canvas Ventures была силой, с которой нужно было считаться в своем разговоре о подводных камнях стартапов с машинным интеллектом. Кин Браун здесь, в Bonsai, говорил о возможности повторения и объяснения систем глубокого обучения, и я мог сказать, что все были очень вовлечены в оба выступления, основываясь на фантастических вопросах аудитории.
Объясняемость - это доверие. Важно знать, почему наш беспилотный автомобиль решился на перерыв, или, может быть, в будущем, почему боты автоматического аудита IRS решат, что настала ваша очередь. Хорошее или плохое решение, важно иметь представление о том, как они были приняты, чтобы мы могли привести человеческие ожидания в большее соответствие с тем, как на самом деле ведет себя алгоритм. В предыдущем блоге об объяснимости мы коснулись его важности для более широкого распространения на рынке ИИ, а сегодня мы собираемся изучить эту концепцию с точки зрения исследования.
DARPA определяет цель Объясняемого искусственного интеллекта (или XAI, как они его называют), чтобы «создать набор новых или модифицированных методов машинного обучения, которые создают объяснимые модели, которые в сочетании с эффективными методами объяснения позволяют конечным пользователям правильно понимать доверять и эффективно управлять новым поколением систем искусственного интеллекта (ИИ). Чтобы помочь нам понять эту концепцию, Кин раскрывает, что такое объяснимость, и рассматривает, как некоторые известные университеты по всей стране подходят к этой проблеме.
Для тех из вас, у кого нет времени смотреть видео (TL; DW, если хотите), я перейду к основным темам, о которых Кин говорит во время встречи, с соответствующими ссылками из презентации.
Изучение семантических ассоциаций
Первая рассматриваемая статья посвящена изучению семантических ассоциаций на видео из технического документа Обнаружение и учет мультимедийных событий, подготовленного SRI International Sarnoff и другими. Это исследование также было использовано в презентации о XAI (на фото ниже) Дэвида Ганнинга из Технологического института Джорджии. Их исследование состояло в том, чтобы выбрать то, что они называют концепциями в видео, с помощью звука, изображения или даже текста, содержащегося в изображениях или подписях. Конечным результатом были обширные метаданные, которые помогли вам выполнить поиск по всему видео, основываясь на том, что компьютер считал бы, например, женихом, невестой, они смотрят сюда, толпа смотрит туда и т. д. из свадебного видео.
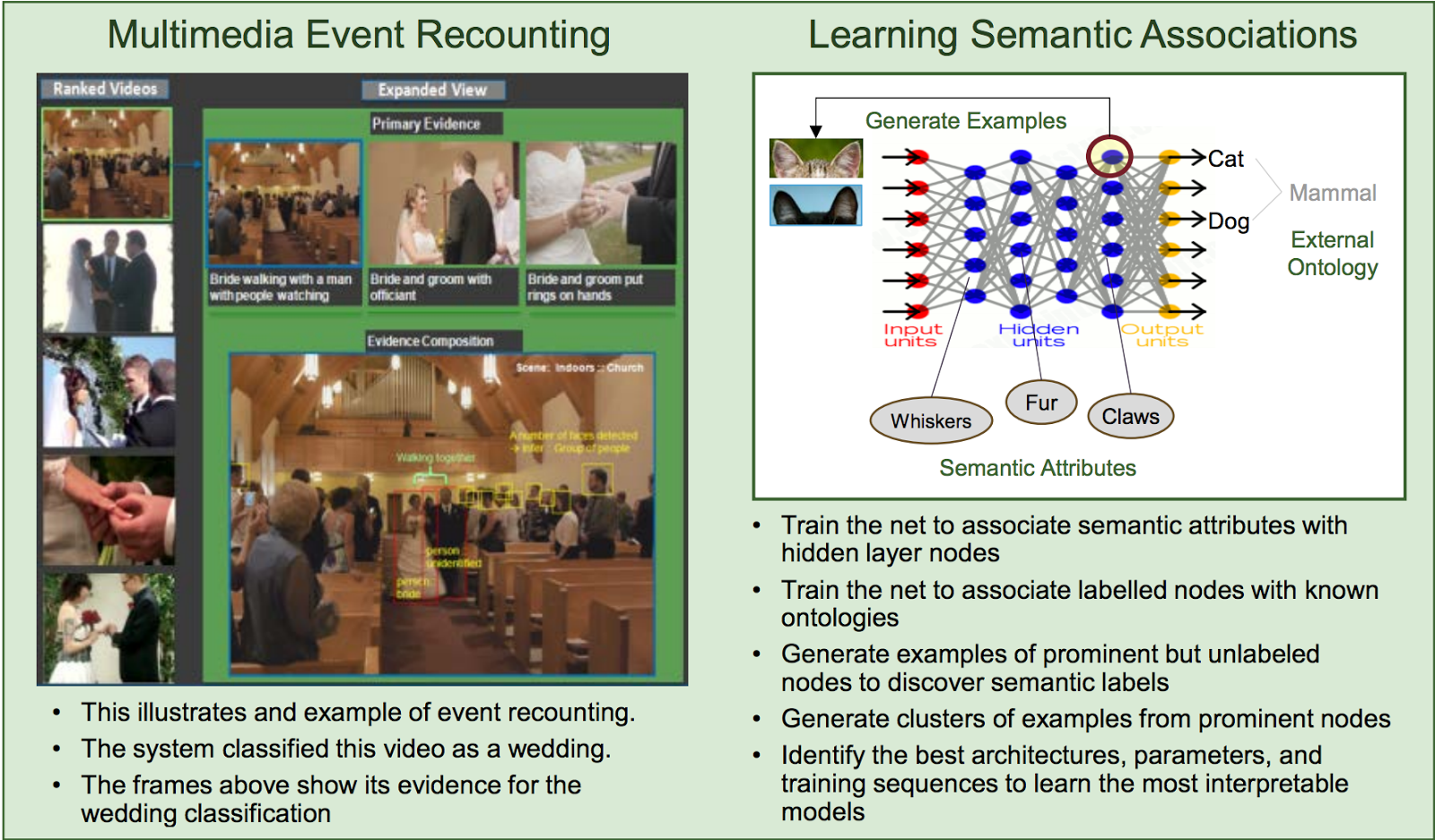
Создание наглядных объяснений
Второй метод, Создание наглядных объяснений, - это статья Калифорнийского университета в Беркли, в которой говорится о противопоставлении самоанализа и обоснования. У вас может не быть самоанализа того, что происходит в алгоритме, на основе его весов, но можно было бы обосновать, почему классификатор сделал то, что он сделал, задним числом. Это сделано с целью составления точных и, что более важно, разборчивых предложений о предмете изображения на основе визуального и текстового описания.
Локальные интерпретируемые независимые от модели объяснения (LIME)
Третий и один из наших фаворитов - LIME из Вашингтонского университета из статьи с метким названием Почему я должен вам доверять?. Они сделали кое-что довольно крутое, где вместо того, чтобы пытаться применить текстовую метку, они выделяли в изображении или в тексте, что сделало его образцом. Совершенно естественная собака, играющая на акустической гитаре, была использована для работы и показана ниже. Это было сделано путем изучения суперпикселей (непрерывный участок одинаковых пикселей), затемнения их и подачи полученного изображения обратно через классификатор, чтобы увидеть, изменилась ли классификация. На изображении ниже в качестве объяснения представлены суперпиксели с наивысшими положительными весами, а все остальное затенено.
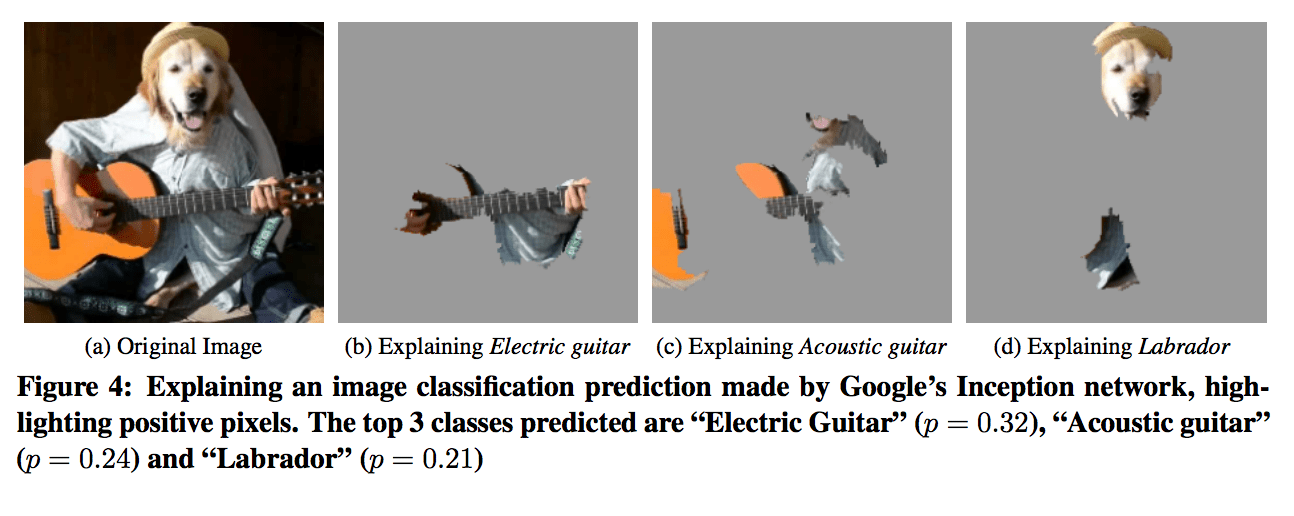
При работе с текстом в наборе данных 20 групп новостей вместо суперпикселей исследователи удалили похожие группы слов, чтобы проверить, изменилась ли классификация. Задача заключалась в том, чтобы классифицировать, пришло ли сообщение от христианской группы новостей или атеистической группы новостей, двух классов, которые трудно различить, потому что в них много слов. Кин просматривает пример кода в видео, и вы можете следить за ним на github.
Рационализация нейронных прогнозов
Четвертая рассматриваемая статья - это исследование лаборатории информатики и искусственного интеллекта Массачусетского технологического института под названием Рационализация нейронных предсказаний. В этом исследовании две нейронные сети, кодировщик и генератор, обучаются вместе. Подобно исследованию, проведенному с LIME, цель состояла в том, чтобы предсказать, какая часть абзаца, в данном случае обзоры пива, соответствует присвоенной оценке. Работа кодировщика заключалась в том, чтобы классифицировать текст и построить сопоставление на основе рейтинга пива, которое затем пропускалось через генератор для предсказания наиболее вероятного непрерывного фрагмента текста, представляющего этот рейтинг.
Объяснимое обучение с подкреплением
Наконец, давайте посмотрим, что делает бонсай, чтобы сделать обучение с подкреплением объяснимым. Когда вы строите модель, вместо того, чтобы сосредоточиться на том, как вы собираетесь построить эту модель, что, если вместо этого вы сосредоточитесь на том, как вы собираетесь ее тренировать? На языке программирования Bonsai, Inkling, вы описываете учебную программу для обучения системы обучения выполнению задачи, разбивая ее на концепции и уроки, а серверная часть обрабатывает модели и запускает их в рамках вашей учебной программы.
Разложив поведение на под-поведения и организовав их в иерархию концепций, вы теперь можете видеть, какое поведение выбирается. Когда у вас есть эта иерархия, которая разбивает задачи, которые система будет выполнять, вы можете спросить, какие из этих концепций способствовали тому или иному поведению, которое генерирует система. Например, вы можете спросить, повернул ли автомобиль направо, потому что он выполнял свою концепцию уклонения от пешеходов, или потому, что его концепция обнаружения дорожных знаков сообщила, что знак левого поворота запрещен. Объяснимость означает выражение того, как концепция способствовала результату и насколько она способствовала.
Наш подход сосредоточен на четырех вещах, составляющих нашу стратегию объяснимого обучения с подкреплением:
- Простота использования - абстрагирование от машинного обучения с помощью языка Inkling
- Понятность - с простой отладкой, чтобы вы могли проверить и улучшить свой ИИ
- Возможность повторной компоновки - возможность повторно использовать части вашего кода и использовать системные библиотеки
- Будущая проверка - по мере развития алгоритмов вам не придется переписывать код, просто переучивайтесь!
Если вы узнаете только одну вещь из этого блога, так это то, что объяснимость в ИИ важна! И это не только важно, но и возможно. Человек может объяснить, что он делает, приближаясь к проблеме, и ваш ИИ должен. Итак, рассмотрите различные методы, и если вы разочарованы отсутствием объяснимости в вашем текущем подходе или начинаете поиски, где требуется объяснимость, я был бы рад услышать от вас.
Кэтрин, адвокат разработчиков здесь, в Бонсай, подписывает контракт. На следующей неделе я немного расскажу о том, чем я занимаюсь здесь, в бонсай, и чего вы можете ожидать от меня в будущем. А пока вы можете найти меня @KatMcCat или больше на наших форумах.