
ВАЖНО: эта публикация официально опубликована и принадлежит Портсмутскому университету. Любое использование этой публикации должно иметь надлежащие ссылки. Не стесняйтесь использовать любое проведенное исследование, однако укажите, пожалуйста, должное признание этой работы.
Эта публикация не содержит всех отрывков, содержащихся в полном исследовательском проекте, из-за деликатности информации и исследований. См. Полную версию публикации.
Аннотация
Даркнет стал центром хакерских сообществ, предлагая киберпреступникам возможность свободно обсуждать и продавать неизвестные и новые эксплойты. В этой статье основное внимание уделяется изучению эффективности машинного обучения для получения информации о киберугрозах с форумов по взлому даркнета. Разработка функционирующей системы для извлечения информации из сообществ и применение методов машинного обучения для прогнозирования объектов, представляющих значительную угрозу. Эти субъекты угроз содержат сообщения пользователей, которые могут быть предназначены для продажи или обсуждения эксплойтов кибербезопасности, в частности, в исследовании основное внимание уделяется выявлению угроз нулевого дня. Эта модель предоставляет профессионалам в области кибербезопасности значительные возможности для создания предварительной разведывательной информации о киберугрозах для более проактивного метода защиты путем просмотра форумов Darknet, извлечения данных и построения модели машинного обучения. В статье рассматриваются различные методы классификации для прогнозирования уровней угрозы с использованием извлечения текстовых признаков, применения контролируемых моделей обучения Наивный Байес, Ближайший сосед, Случайный лес и Машина опорных векторов. Исследование показало, что применение методов машинного обучения для извлечения текстовых функций к данным Darknet, созданным пользователями, может прогнозировать неразвернутые или возникающие угрозы атак, такие как вредоносные программы и эксплойты, с точностью до 81,77%.
1. Введение
Угрозы взлома, вирусов и вредоносных программ были проблемой для индустрии кибербезопасности с первых лет существования компьютерных систем (Milošević, 2013). В частности, в 1987 году был обнаружен один из первых задокументированных случаев компьютерного вируса под названием «Мозг» или «пакистанский вирус» (Highland, 1997). Однако с момента создания и развития Интернета киберпространство сформировало центральный узел для роста и создания этих кибератак. По оценкам, в общей сложности Интернетом пользуются 3,4 миллиарда пользователей (46% населения мира). Таким образом, есть основания утверждать, что Интернет предоставил киберпреступникам платформу для обучения, разработки, сотрудничества и тестирования методов взлома (ACS, 2016). Такие случаи, как закрытие веб-сайтов, нарушение данных, мошенничество и распространение вирусов, очевидны для безопасности современных компьютеров и для их пользователей. Согласно отчету Verizon о расследовании утечек данных за 2015 год (2015), векторы кибератак по отраслям включают:
- Пункты продаж (розничная торговля, развлечения, гостиничный бизнес) - 28,5%
- Криминальное ПО (государственный сектор, образование, финансы) - 18,8%
- Кибершпионаж (профессиональный, информационный, производственный) - 18%
- Разное - 14,7%
- Злоупотребление привилегиями (горнодобывающая промышленность, здравоохранение, административное управление) - 10,6%
- Веб-приложения (финансы, информация) - 9,4% (Verizon, 2015)
Кроме того, они также отмечают, что наиболее целевыми отраслями в 2015 году являются следующие:
- Производство - 27,4%
- Общественные - 20,2%
- Профессиональные - 13,3%
- Информация - 6,2%
- Коммунальные услуги - 3,9%
- Транспорт - 1,8%
- Образование - 1,7%
- Недвижимость - 1,3%
- Финансовые услуги - 0,8%
- Здравоохранение 0,7% (Verizon, 2015)
Из этого очевидно, что предотвращение кибератак в самых разных отраслях и направлениях представляет собой огромную задачу с огромным количеством проблем для профессионалов в области кибербезопасности. Эрик Фишер (2016) классифицирует долгосрочные проблемы безопасности в сфере технологий:
- Дизайн. Безопасность не всегда является неотъемлемой частью проектирования и разработки программного и аппаратного обеспечения. Традиционно из-за экономических соображений разработчики уделяют больше внимания функциям, чем обеспечению безопасности. Более того, невозможно предугадать особенности безопасности.
- Изобретательный: экономика кибербезопасности сильно искажена. Кибербезопасность обычно считается дорогой, и многие не считают ее вложением. С другой стороны, сами кибератаки могут быть дешевыми и очень прибыльными для преступников.
- Консенсус: заинтересованные стороны и руководители организаций частного и государственного секторов по-разному относятся к кибербезопасности. Различное понимание его значения, реализации и риска означает, что эти люди могут действовать неправильно для предотвращения атак.
- Окружающая среда: киберпространство можно рассматривать как одну из самых быстрорастущих технологических областей как в масштабах, так и в масштабах собственности. Приложения, социальные сети, мобильные устройства, данные, облачные вычисления и Интернет вещей (IoT) и многие другие - все это создает сложную среду для кибербезопасности. Потенциальные возможности для кибератак растут по мере роста киберпространства (Fischer, 2016).
Понимание масштабов кибератак и широкого спектра векторов, в которых они происходят, означает, что упреждающий подход к кибербезопасности, возможно, является возможным решением этих проблем. В то время как такие проблемы, как недостатки в конструкции, могут позволить злоумышленникам взять верх; Специалисты по кибербезопасности смогли проактивно обнаруживать атаки, отслеживая сообщества хакеров и веб-сайты социальных сетей (Robertson, 2017). В последние годы рост хакерских сообществ как в поверхностной сети, так и в даркнете стал еще более очевидным. Хотя понятно, что специалисты по безопасности и организации, занимающиеся кибербезопасностью, получают большой объем информации об угрозах от этих сообществ; мы сталкиваемся с постоянно растущей проблемой мониторинга поведения на социальных платформах из-за их экспоненциального роста (Chaudhry, 2017). Примером может служить масштаб 0day Forum (популярный форум, посвященный эксплойтам и взломам), который насчитывает более 47 000 сообщений, 15 000 тем, 35 000 участников («0day Forum - Homepage», без даты).
Несмотря на то, что количество эксплойтов и уязвимостей растет день ото дня, методы защиты работают заметно медленнее. Недавний пример этого - ботнет Mirai. 20 сентября 2016 года сайт автора Брайана Кербса был закрыт в результате атаки распределенного отказа в обслуживании (DDoS). Атака содержала необычайно большой объем трафика - 620 гигабайт в секунду (Kolias, Kambourakis, Stavrou & Voas, 2017). Вскоре после этого было обнаружено, что варианты одного и того же ботнета атакуют множество других веб-сайтов, скорость одного из которых достигает 1,1 Терабайта в секунду (Goodin, 2017). Примечательно, что атака также затронула поставщика услуг Dyn, вызвав перебои в работе сотен веб-сайтов в США. Через месяц после того, как ботнет впервые обнаружился, исходный код хакерского сообщества был обнаружен на Hackforums. Это не только стало серьезным тревожным сигналом для кибербезопасности устройств Интернета вещей, но и показало распространенность информации об угрозах на хакерских форумах (Fremantle & Scott, 2017). Сообщества хакеров позволяют пользователям свободно и анонимно делиться, продавать, покупать и обсуждать методы атаки, что вызывает растущую озабоченность. В рамках инициативы Zero Day только за 2016 год было обнаружено 135 уязвимостей нулевого дня с высокой степенью угрозы в Adobe, 76 в Microsoft и 50 в продуктах Apple («Zero Day Initiative», 2017). Таким образом, очевидно, что в ближайшем будущем индустрия безопасности столкнется с большим количеством эксплойтов нулевого дня, и мониторинг их присутствия в хакерских сообществах, на рынках и в каналах IRC имеет жизненно важное значение.
Это исследование направлено на выявление эффективности сбора информации о киберугрозах (CTI) из даркнета. Исследование того, как можно применить поисковые роботы для извлечения данных и машинное обучение, чтобы построить эффективную модель для обеспечения CTI. Это будет сделано путем сбора первичных исследований относительно того, насколько точно и эффективно машина может автономно предсказать угрозу. Первичные данные, используемые в этом исследовании, будут запрашиваться и собираться разработчиками работающего веб-сканера для сбора и анализа данных с форумов по взлому даркнета. Предполагаемый результат направлен на то, чтобы иметь возможность автономно собирать и классифицировать данные с форумов по взлому даркнета для обеспечения CTI. Кроме того, обзор и обсуждение предшествующей литературы, посвященной CTI, интеллектуальному анализу данных и классификации текстов, связанных с даркнетом, будет стремиться обеспечить контекст всего исследования. Исследование призвано ответить на следующие вопросы:
- Какие исследования в настоящее время проводятся в области интеллектуального анализа данных для анализа киберугроз?
- Насколько эффективными могут быть модели извлечения текстовых функций и интеллектуального анализа данных для обеспечения аналитики киберугроз?
- Какой уровень точности прогнозов можно получить с помощью этой модели?
Таким образом, конкретные вклады в это исследование включают:
1) Краткое введение в даркнет, машинное обучение, интеллектуальный анализ данных и анализ киберугроз.
2) Обзор и обсуждение текущей литературы по этим областям.
3) Методология создания системы сбора первичные исследования и информация о киберугрозах из даркнета.
4) Оценка этой системы, обнаруженные первичные данные и их эффективность в прогнозировании угроз.
5) Обсуждение этого исследования, выводы и обзор Первичные исследования для будущего развития.
1.1. Даркнет
В этом исследовании будет определен термин «Clearnet» как веб-страницы, к которым можно получить доступ с помощью стандартных веб-браузеров, таких как Google Chrome и Safari. Каждая веб-страница, к которой могут получить доступ поисковые системы Clearnet, проиндексирована с 32-битным или 128-битным IP-адресом в службе системы доменных имен. Хотя количество веб-страниц Clearnet исчисляется миллионами и растет день ото дня, очевидно, что сюда не входят неиндексированные или «скрытые» сайты. Оманд (2015) цитирует, что веб-страницы Clearnet составляют лишь около 1/500 интернета. Остальное содержится в различных слоях Интернета. Ciancaglini, Balduzzi, Goncharov & McArdle (2013) определяют термин «Deepweb» как сайты, которые не индексируются поисковыми системами, в частности следующие:
- Динамические веб-страницы: страницы, динамически создаваемые по HTTP-запросу.
- Заблокированные сайты: сайты, которые явно запрещают поисковому роботу переходить и извлекать их контент с помощью, например, CAPTCHA, HTTP-заголовков без кеширования pragma или записей ROBOTS.TXT.
- Сайты без ссылок: страницы, не связанные ни с одной другой страницей, что препятствует их доступу поисковому роботу.
- Частные сайты: страницы, требующие регистрации и входа / аутентификации по паролю.
- Контент, отличный от HTML, контекстный или скриптовый: контент, закодированный в другом формате, доступный через Javascript или Flash, или контекстно-зависимый (т. е. конкретный диапазон IP-адресов или запись в истории просмотров).
- Сети с ограниченным доступом: контент на сайтах, недоступный из общедоступной интернет-инфраструктуры (Ciancaglini, Balduzzi, Goncharov & McArdle, 2013)
Примечательно, что то, что обсуждается как «более глубокий» уровень Deepweb, - это уровень «Darknets». Даркнеты и альтернативные инфраструктуры маршрутизации состоят из веб-сайтов, для которых требуются такие системы, как TOR, или веб-сайтов, размещенных в сетях Invisible Internet Project (I2P) (Ciancaglini, Balduzzi, Goncharov & McArdle 2013). В частности, луковый маршрутизатор (TOR) направляет трафик через цепочку узлов, которая шифрует информацию от начала до конца и вслепую передает ее следующему узлу, не обеспечивая регистрации пользователя. Как предположил Мэнсфилд-Девайн (2009), хакеры и киберзависимые преступники очень часто действуют на всех рассмотренных уровнях. Однако очевидно, что Deepweb и Darknet обеспечивают более высокий уровень анонимности и безопасности для тех, кто ведет незаконную деятельность. Таким образом, предварительная разведка CTI работает в первую очередь на этих сетях.
1.2. Машинное обучение, интеллектуальный анализ данных и извлечение текстовых функций
Машинное обучение, подраздел искусственного интеллекта, представляет собой постоянно расширяющуюся модель автоматизации, используемую сегодня во многих приложениях в отрасли (Кононенко и Кукар, 2013). Его можно найти в медицине, экономике, естественных / технических науках и многих других. По мере развития технологий за последние 20 лет сбор и анализ данных стали жизненно важными в современных исследованиях. Машинное обучение включает системы, которые учатся на этих данных. «Правила обучения, функции, отношения, системы уравнений, деревья решений и регрессии, байесовские сети, нейронные сети и т. д.» (Кононенко и Кукар, 2013). То, что определяется как «интеллектуальный анализ данных», - это сам процесс машинного обучения. Сюда входит метод извлечения информации для изучения закономерностей, теорий, прогнозов и моделей из больших наборов данных. Интеллектуальный анализ данных - это многогранная область, которая помимо машинного обучения включает статистику, искусственный интеллект, базы данных, распознавание образов и визуализацию данных (Li, 2014). Таким образом, важно заявить, что процесс интеллектуального анализа данных или обнаружения знаний в базах данных (KDD) охватывает множество методов, таких как машинное обучение. Кроме того, интеллектуальный анализ данных включает в себя множество различных шагов, которые необходимо повторять и уточнять, чтобы обеспечить высокий уровень точности и прогнозов при анализе данных, как показано на рисунке 1.

Это означает, что в настоящее время не существует стандартизированной структуры для проведения интеллектуального анализа данных. Тем не менее, Межотраслевой стандартный процесс интеллектуального анализа данных (CRISP-DM) определяет одну структуру для процесса интеллектуального анализа данных в нескольких отраслях. Как цитирует Jain (2012), основные задачи интеллектуального анализа данных включают в себя:
1. Классификация: классифицирует элемент данных по предопределенному классу
2. Оценка: определение значения для неизвестных непрерывных переменных
3. Прогноз: записи, классифицируемые в соответствии с предполагаемым будущим поведением 4. Связь: определение элементов, которые вместе < br /> 5. Кластеризация: разделение популяции на подгруппы или кластеры
6. Описание и визуализация: представление данных (Jain 2012)
Таким образом, процесс и определение интеллектуального анализа данных включает извлечение знаний из данных. Машинное обучение определяется в интеллектуальном анализе данных - это автоматизация используемых методов. Как обсуждали Кононенко и Кукар (2013):
«Машинное обучение нельзя рассматривать как истинное подмножество интеллектуального анализа данных, поскольку оно также включает в себя другие поля, не используемые для интеллектуального анализа данных»
Знания, полученные с помощью различных методов машинного обучения, варьируются в зависимости от предполагаемого результата. Машинное обучение подразделяется на три основные категории: обучение без учителя, обучение с учителем и обучение с подкреплением (см. Рисунок 2). Производные от них включают классификацию, регрессию, кластеризацию, изучение ассоциаций, логических отношений и уравнений (Кононенко и Кукар, 2013).

Модели обучения без учителя определяются путем применения алгоритмов интеллектуального анализа данных для выявления закономерностей и структур в атрибутах набора данных. В обучении с учителем используются указанные или предоставленные переменные для алгоритмов прогнозирования результатов.
1.3. Анализ киберугроз
Современная кибербезопасность - это сложная и многогранная проблема во многих измерениях киберпространства. Хотя традиционные подходы к обеспечению безопасности, включающие ограничение уязвимостей и удаление известных эксплойтов, всегда были эффективными, не отставать от злоумышленников - постоянная проблема. Эффективная стратегия упреждающего противодействия кибератакам включает в себя обнаружение будущих угроз, поведения, намерений и доступности злоумышленников. Проактивный характер предоставления CTI предназначен для прогнозирования и устранения уязвимостей и эксплойтов. Кроме того, это значительно улучшает способность реагировать на атаки, когда они происходят. Из-за этого CTI - очень сложная область и применяется по-разному. Организации по анализу угроз получают представление о будущих атаках с помощью множества методов, к числу которых можно отнести мониторинг данных конечных точек для регистрации субъектов угроз в системе. Однако за последние пять лет использование искусственного интеллекта и машинного обучения для сбора предварительных разведывательных данных быстро расширилось. ABI Research полагает, что «машинное обучение в сфере кибербезопасности увеличит расходы на большие данные, разведку и аналитику до 96 миллиардов долларов к 2021 году» (ABI-Research, 2017). Из-за большого количества источников данных, обнаруженных в кибер-инфраструктуре, машинное обучение может использоваться в CTI по-разному. Сюда могут входить такие, как обнаружение аномалий, ботнетов и фишинга, а также активная аутентификация (Епишкина и Запечников, 2016). Сбор информации об угрозах можно рассматривать как первую линию защиты в инфраструктуре кибербезопасности. Вторая линия защиты включает реактивные системы безопасности, такие как системы обнаружения вторжений (IDS) и методы предотвращения (Епишкина и Запечников, 2016).
Проактивность с помощью CTI означает, что отрасль безопасности сталкивается с серьезными проблемами, связанными с атаками нулевого дня. Атака нулевого дня - это неизвестный эксплойт, обнаруживающий уязвимость в программном или аппаратном обеспечении. В результате эти атаки нулевого дня практически не оставляют возможности для обнаружения в процессе безопасности. Это, конечно, означает, что профессионалы в области кибербезопасности постоянно ищут новые методы обнаружения атак. Один конкретный источник этих эксплойтов находится в сообществах хакеров и на рынках на разных уровнях Интернета. Коммерциализация эксплойтов увеличивается день ото дня. Нелегальные онлайн-торговые площадки, форумы и чаты не редкость. По оценкам, в 2011 году на Silk Road, рынке нелегальных товаров, было совершено сделок на сумму более 1,2 миллиона долларов (Armona & Stackman, 2014). Кроме того, будет разумным заявить, что из-за информации об эксплуатации, имеющей очень малые предельные издержки производства, они являются очень ценным товаром для продавцов. Однако очевидна временная чувствительность этих эксплойтов. Компании и государственные организации постоянно обновляют программное обеспечение, чтобы оставаться в курсе последних достижений технологий и вносить исправления. Может случиться так, что эксплойт станет бесценным из-за обновления программного обеспечения организацией, поэтому время их продажи очень важно. Кроме того, из-за того, что эксплойты нулевого дня уникальны, возникает много вопросов относительно легитимности эксплойта. В результате информация, собранная в связи с эксплойтами нулевого дня, имеет огромную ценность для индустрии кибербезопасности, и CTI уделяет особое внимание как можно большему количеству этой информации.
2. Обзор литературы
Как обсуждалось ранее, основная цель аналитики киберугроз (CTI) - помочь организациям обнаружить и понять потенциальные риски от различных субъектов угроз. Кратко упомянув эксплойты нулевого дня; субъекты угроз могут иметь разные формы и формы. CTI должен содержать подробную информацию об атаке или угрозе, чтобы помочь организации исправить свою безопасность и защититься от нее. Его функции в вооруженных силах, правительстве, бизнесе и безопасности обеспечивают стратегическое преимущество против злоумышленников. CTI как компонент кибербезопасности обычно включает атаки из трех областей:
- Киберпреступность
- Кибер-хактивизм
- Кибершпионаж (Planqué, 2017)
Однако по мере того, как количество угроз в постоянно расширяющейся области растет, понимание того, что на самом деле влечет за собой CTI, становится все более расплывчатым. Отсутствие четкой академической литературы и компаний, использующих CTI для определения своих продуктов, приводит к нечеткому определению этого термина (Planqué, 2017). В разделе 2.1 будет представлен обзор, сравнение и обсуждение различных академических текстов, чтобы получить четкое представление о том, что подразумевается под CTI в этой статье и первичном исследовании.
Сбор данных об угрозах из таких источников, как даркнет, - это развивающийся подход к упреждающему обнаружению угроз. Сбор информации об угрозах с помощью методов интеллектуального анализа данных и машинного обучения очевиден. По мере развития и развития этой области появляются новые и разнообразные методы мониторинга незаконной деятельности в даркнете. К разведывательным данным можно применять различные методы, такие как правила ассоциации, анализ временных рядов, кластеризацию, статистический и корреляционный анализ, чтобы предоставить ценную информацию об угрозах. В дополнение к этому подходы к классификации текста с использованием как контролируемых, так и неконтролируемых моделей позволяют с большой точностью прогнозировать результаты (McCallum & Nigam, 2005). В разделе 2.2, основанном на академических исследованиях, будет рассмотрено применение методов интеллектуального анализа данных и машинного обучения. Кроме того, сосредоточить обзор литературы на исследованиях, относящихся к интеллектуальному интеллектуальному анализу данных и моделям машинного обучения.
Извлечение текстовых функций включает использование приложений интеллектуального анализа данных и машинного обучения, как обсуждалось ранее, с большими наборами текста. Извлечение текстовых функций применяется во многих отраслях; его приложение для анализа настроений является важной частью маркетинга и продаж в цифровом мире (Pang & Lee, 2008). По сути, это требует извлечения функций из текста, созданных пользователями, чтобы предсказать мнение, настроения или субъективность. Его использование в аналитике угроз является относительно новым, поэтому в этом разделе будет проведен обзор, сравнение и обсуждение исследований в различных отраслях. Таким образом, обеспечивается понимание функциональных возможностей извлечения текстовых признаков, которые могут быть применены к модели в последующих разделах этой статьи.
2.1. Анализ киберугроз
Как обсуждалось ранее, использование CTI охватывает множество различных секторов и включает несколько векторов атаки. Из-за широкого спектра угроз и действующих лиц в киберпространстве определение CTI может быть несколько неясным. Важно иметь четкое представление о том, что влечет за собой разведка угроз в киберпространстве и какую информацию можно рассматривать как разведывательную. Хатчинс, Клопперт и Амин (2012) обсуждают то, что они называют «анализом цепочки уничтожения» для кибератаки, чтобы понять, какая информация или «разведданные» задействованы. Реконструкция вторжения подробно описана на Рисунке 3.

Разведку можно собрать на любом этапе этой цепочки убийств. Более того, Хатчинс, Клопперт и Амин детализируют, что если аналитик обнаруживает информацию на любом этапе внутри цепочки убийств, он может предположить, что предыдущие фазы уже были выполнены. Таким образом, необходимо провести полный анализ текущих и предыдущих этапов, чтобы предотвратить будущие атаки. Если предыдущие этапы не могут быть воспроизведены, есть основания утверждать, что действие на текущей фазе будет затруднено. Организации могут определять информацию об угрозах на разных этапах цепочки уничтожения. Как обсуждали Hutchins, Cloppert & Amin, система обнаружения вторжений может обнаруживать угрозу на этапе 5, как показано на рисунке 4.

Ярким примером является обнаружение вируса в системе. Если антивирусный сканер обнаруживает вирус, очевидно, что он уже находится на этапе 6 и заранее прошел все этапы. Хотя это все еще можно рассматривать как разведку угроз, Hutchins, Cloppert & Amin определяют это как обнаружение поздней фазы в цепочке уничтожения. Более того, чтобы разведка была максимально эффективной, защитники должны переместить свой анализ и обнаружение на более высокий уровень в цепочке убийств. Рисунок 5 показывает, что не только обнаружение угрозы происходит на более ранней стадии, но и меньше фаз, которые нужно воспроизвести для смягчения атаки, как показано на рисунке 4.

С учетом вышесказанного можно сделать общую предпосылку, что информация об угрозе, собранная на ранних этапах цепочки уничтожения, представляет собой гораздо более проактивную, эффективную и действенную информацию об угрозах.
В отчете Центра защиты национальной инфраструктуры (CPNI) MWR InfoSecurity (2015) определяет информацию об угрозах как информацию, на которую можно воздействовать, чтобы изменить результаты. В одном из примеров отмечается использование «Знающих» и «Неизвестных» в интеллекте. Таким образом, при более высоком уровне интеллекта «Неизвестные неизвестные» атаки переходят в «Известные известные» (рис. 6).
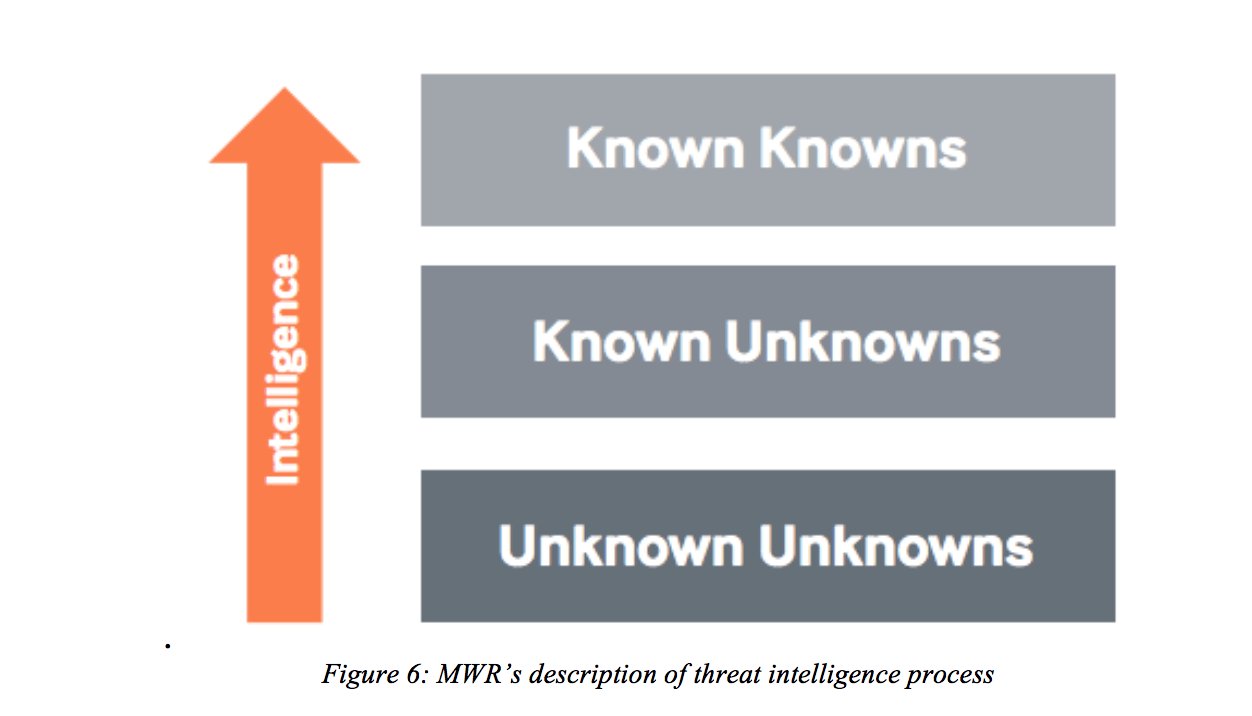
MWR утверждают, что определение CTI неясно из-за того, что это молодая область. В дополнение к этому, поставщики и рекомендательные документы описывают CTI по-разному из-за их продуктов и деятельности. В отношении традиционного интеллекта (обсуждалось ранее) они определяют информацию об угрозах как информацию, которая может помочь принять решение, чтобы предотвратить атаку или сократить время, необходимое для обнаружения атаки. Кроме того, MWR InfoSecurity (2015) отмечает, что подтипами CTI являются стратегический анализ угроз и оперативный анализ угроз:
Стратегическая разведка угроз (STI) включает в себя информацию высокого уровня для членов совета директоров или руководителей высшего звена в организации. Этот уровень интеллекта может быть не техническим, но он определит влияние угроз на организацию, в том числе на финансовую.
Оперативная разведка угроз (OTI) включает в себя информацию, более специфичную для атаки. Как правило, это включает в себя технические подробности для того, чтобы, например, справиться с атаками со стороны служб безопасности. Согласно MWR, оперативная разведка угроз варьируется в зависимости от сектора. Например, компания может пожелать получить информацию о потенциальном злоумышленнике, однако различные ограничения, такие как закон, могут помешать им собрать эту информацию. С другой стороны, правительственные организации могут иметь доступ к этому уровню информации и, следовательно, их OTI находится на более высоком уровне.
Из-за этого при обсуждении OTI и в более общем плане CTI в государственном секторе общее определение CTI военными рассматривается по-разному из-за характера их разведки. Министерство обороны (2016 г.) определяет CTI как деятельность в киберпространстве по сбору разведданных о системе цели и противника для поддержки военных операций. Таким образом, примечательно, что CTI в вооруженных силах может не обязательно иметь отношение к потенциальной атаке и в большей степени иметь отношение к атакам, осуществленным самими военными. Примечательно, что Министерство обороны США (2017) определяет разведывательные данные как информацию, непосредственно поддерживающую текущие или будущие операции.
Переходя к тому, что на самом деле влечет за собой разведка угроз, Барнум (2014) отмечает, что традиционная разведка стремится понять возможности, действия и намерения угроз. Таким образом, при обсуждении CTI, идентифицированные элементы могут включать:
- Предыдущие действия
- Произошедшие действия
- Возможные действия
- Обнаружение или идентификация
- Смягчение
- Соответствующие субъекты угроз
- Намерение
- Возможности
- Тактика, приемы и процедуры (ТТП)
- Уязвимый
- Неправильная конфигурация
- Слабые стороны
Более глубокое понимание этих элементов позволяет принять более целостное и эффективное решение о нападении. То, что подробно рассматривается в исследованиях Бранума и Хатчинса, Клопперта и Амина, по сути, детализирует контекстуальное понимание того, откуда может быть получен CTI и в какой момент определяется информация об атаке. Согласно Hutchins, Cloppert & Amin (2012), интеллект на ранней стадии - это то, что обычно понимается как CTI в корпоративных сферах.
Примечательно, что при обсуждении CTI контекст его цели или намерения должен быть четко определен, чтобы иметь четкое понимание его определения. Из-за этого очевидно, что CTI в разных секторах имеет множество разных доменов.
2.2. Интеллектуальный анализ данных и машинное обучение в даркнете
Ряд исследователей применили методы интеллектуального анализа данных и машинного обучения к данным в даркнете, чтобы обеспечить определенный уровень анализа угроз. Thonnard & Dacier (2008) представляют многомерную модель интеллектуального анализа данных для предоставления информации о возникающих угрозах атак на основе данных honeypot1. Их модель включает в себя различные атрибуты данных, такие как географические, временные, IP-подсети и т. Д. Эта структура обнаруживает закономерности в данных путем корреляции временных рядов и кластеризации между атаками с использованием сравнений трассировки. Таким образом, предлагается корреляция между аналогичными или сгруппированными продолжающимися атаками для прогнозирования потенциальных угроз. Эта многомерная модель обнаружения и интеллектуального анализа данных (KDD) направлена на предоставление практических знаний в Интернете. Цель их методологии - выделить индикаторы для оценки распространенности злонамеренных действий и дать представление о возникающих угрозах. Результатом этой методологии стала система, которая извлекала значимые элементы данных путем анализа больших наборов данных приманок. Затем эта информация «синтезируется» для извлечения релевантности и прогнозов. Эксперимент завершается подробным анализом информации об угрозах атак. Thonnard & Dacier (2008) расширяет это исследование в своем продолжающемся журнале «Структура для обнаружения паттернов атак в данных honeynet». В следующем исследовании они применяют ту же структуру к методам кластеризации на основе кликов для доменных моделей KDD и анализа данных для определения активности червей2 в Интернете. Результат их модели кластеризации позволяет идентифицировать несколько червей и ботнетов в трафике, собираемом данными приманок. Обе структуры, представленные Thonnard & Dacier, делают важные наблюдения за распространенностью анализа угроз на основе больших наборов данных из даркнета. Их модели KDD обеспечивают высокую точность; однако стоит отметить, что их исследование основано на ранее извлеченных наборах данных приманок. Таким образом, хотя эти модели могут предоставлять модели упреждающего анализа угроз, они могут не иметь возможности обнаруживать новые и возникающие невидимые угрозы из-за возраста данных.
Подобные методы кластеризации также обсуждаются Fachkha et al (2012). В этой статье представлена модель KDD правила ассоциации для изучения корреляции между киберугрозами с использованием данных Darknet. Эта модель анализирует распределение пакетов, транспорт, протоколы сетевого и прикладного уровня, а также разрешенные доменные имена. Метод Фачхи и др. Выполняет определение характеристик и профилирование трафика. В частности, этот метод определяет и отслеживает распространение протокола Darknet, чтобы указать на потенциальные атаки распределенного отказа в обслуживании (DDoS), эксплойты переполнения буфера и незапрашиваемый доступ к виртуальной частной сети (VPN). Представленная работа приводит к эффективным средствам интерпретации моделей угроз и построения прогнозов угроз с помощью модели KDD. При рассмотрении этой работы следует отметить, что снова использованные данные представляют собой ранее собранные данные и могут не обязательно обеспечивать точные результаты для анализа угроз в реальном времени. Несмотря на то, что его эффективность в аналитике угроз очевидна с использованием используемого набора данных, он может не предоставлять аналитические данные об угрозах для прогнозирования характеристик более близких и возникающих угроз в текущем трафике даркнета.
В более позднем исследовании Робертсон (2017) представляет операционную систему для предоставления в реальном времени аналитики угроз на основе данных даркнета. Их модель извлекает данные из торговых площадок для анализа моделей KDD с помощью алгоритмов машинного обучения, таких как Naïve Bayes и Support Vector Machine. Эта методология обеспечивает анализ угроз для продуктов и
сервисы, ориентированные на злонамеренный взлом сайтов даркнета, очень похожие на систему, изученную и представленную в этой статье. Система, которую они представляют, обеспечивает предсказательный подход машинного обучения с точностью 78-82%. Примечательно, что эта статья представляет собой одну из наиболее важных работ по отношению к этому исследованию. Что примечательно в этом исследовании, так это то, что они сосредоточены в первую очередь на продуктах, связанных с обсуждениями на форуме. Таким образом, хотя это может представлять собой очень эффективный инструмент CTI, он не может анализировать и прогнозировать угрозы из более общих журналов чата от пользователей Darknet. Тем не менее, эта модель действительно обеспечивает анализ угроз на основе упреждающей методологии в реальном времени. Работа, представленная Робертсоном (2017), является очень ценным и недавним исследованием, имеющим отношение к рассматриваемой теме. Следует отметить, что работа, имеющая отношение к этому исследованию, очень скудна и, таким образом, представляет собой уникальный подход к Darknet CTI.
1. Приманки - это ловушки информационных систем, используемые для привлечения и отслеживания злонамеренных атак в Интернете с целью получения информации о них (Jin, de Vel, Zhang & Liu, 2008).
2. Вирусы-черви или интернет-черви - это автономные вредоносные программы, которые копируют себя для распространения по сети (Назарио, 2004).
2.3. Классификация текста и анализ тональности
Классификация текстов и анализ тональности направлен на выявление механизмов контекста и субъективной информации на основе текстовых данных с целью определения или прогнозирования закономерностей и настроений. Авторы Икономакис, Котсиантис и Тампакас (2005) обсуждают, что классификация текста обычно состоит из следующих этапов:
i) Чтение документов
ii) Обозначение текста
iii) Выделение основы
iv) Остановка удаления слова
v) Векторное представление текста
vi) Выбор функции < br /> vii) Применяется к алгоритмам обучения с учителем
viii) Мера точности
В этой статье Икономакис и др. Обсуждают, что классификация текстовых документов не сильно отличается от более общих задач машинного обучения. Однако следует отметить, что одна из самых больших проблем с классификацией текста - это огромное количество функций в текстовом документе и представленных экземплярах.
Чтобы решить такую проблему, Ли и др. (2005) представляют методологию классификации с использованием положительных и немаркированных текстовых данных. Они предлагают альтернативный метод использования набора обучающих данных, содержащего как положительные, так и отрицательные метки. Вместо этого в модели используются два класса: один помечен как положительный, а другой - нет. Результаты показывают, что только один набор помеченных данных используется для прогнозирования немаркированных данных. Для обучающего набора необязательно, чтобы он содержал как отрицательные, так и положительные классы, по сути, обучающий набор, содержащий один класс и немаркированный класс, имеет относительную одинаковую степень точности.
Другой ответ на этот вызов представлен Лю, Ли, Ли и Ю (2004). Они обсуждают классификацию текста, используя помеченные слова, как относящиеся к документам. Следует отметить, что для того, чтобы классификатор был относительно точным при чтении текстовых документов, релевантность слов в классе должна иметь высокую полярность. Их модель предлагает менее трудоемкий метод классификации текстов и в некоторых случаях может обеспечить более точные и эффективные результаты.
Обсуждая использование классификации текста, важно подчеркнуть сложность построения наборов обучающих данных. С хорошо обученным набором данных немаркированные или тестовые наборы данных могут быть классифицированы с более высокой точностью. Включая ранее обсужденные, методы классификации текстов были улучшены за счет использования лексиконов. Аль-Роуайли, Абулаиш, Аль-Хасан Халдар и Аль-Рубайан (2015) представляют разработку лексикона двуязычного анализа тональности (BiSAL), состоящего из лексики тональности как для английского, так и для арабского языков. Ключевой концепцией, предлагаемой этой моделью, является разработка систем анализа мнений и анализа настроений на основе данных форумов Darknet, а именно тех, которые связаны с радикальным контентом. Эта модель содержала список из 279 английских и 1019 арабских сентиментально представленных слов вместе с их морфологическими вариантами в дополнение к их эмоциональной полярности (связанной с радикальным содержанием). В этом исследовании примечательно, что системы BiSAL Al-Rowaily, Abulaish, Al-Hasan Haldar и Al-Rubaian находят множество приложений для кибербезопасности, чтобы идентифицировать и определять полярность настроений в тексте. Кроме того, текст, созданный пользователем, может содержать множество морфологических вариантов слов, и, таким образом, наличие метода их идентификации и применения их к уровню полярности для прогнозирования шаблона жизненно важно для анализа угроз.
В этом исследовании очевидно наличие четкого понимания того, какие проблемы могут возникнуть в тексте, представленном людьми. Это связано с тем, что коннотации в предложении могут показаться читателю отличным от машинного. Одна из наиболее широко обсуждаемых областей классификации текстов и анализа тональности - это онлайн-СМИ. Рост организаций, желающих узнать мнения и иметь показатели по своей продукции, растет по мере очевидного увеличения объема онлайн-данных. В одной такой статье, написанной Мишель Аннет и Грезгожем Кондраком (2008), машинное обучение и лексические подходы сравниваются с большими наборами обзоров фильмов. Аннетт и Кондрак определяют ключевую особенность и проблему в анализе тональности и извлечении текстовых признаков. Это предотвращение и отрицание выражений в тексте. Примером запрещенного выражения является выражение, которое содержит количество слов с полярностью, противоречащей тому, что фактически выражает пользователь. Цитата, например:
«Джонни Депп был в порядке. Предыдущие два пиратских хода были нереальными и скучными. Сюжет был ужасен. Однако спецэффекты сделали третий фильм о пиратах превосходным » (Мишель Аннетт и Грезгож Кондрак, 2008 г.)
Отрицательные слова в этом утверждении могут привести к тому, что машина неправильно распознает отрицательное утверждение. Тогда как на самом деле заявление положительное. Кроме того, они отмечают, что отрицательное утверждение состоит из отрицательного слова с существительным, прилагательным, наречием или глаголом. Авторы также отмечают, что, хотя людям может быть легко определить полярность полного утверждения, машина может определить полярность только отдельных слов, таких как 'приятный' и "развлекательный". Следовательно, прогнозирование для программы при работе с ошибочными и отвергнутыми словами - сложная задача. Понимание таких проблем до создания текстового классификатора может поддержать точность и помочь ограничить возможные проблемы при построении точного классификатора.
2.4. Обзор
В предыдущих трех разделах были рассмотрены различные части академических исследований в трех различных подразделах, используемых в этом исследовании, чтобы представить метод для CTI. Из литературы сделаны следующие выводы, чтобы обеспечить информативный обзор продвижения вперед.
- Из исследования, представленного Hutchins, Cloppert & Amin (2012), стало известно, что определение атаки во время фазы разведки, размещения оружия и доставки обеспечивает более активный и эффективный метод CTI.
- MWR InfoSecurity (2015) описывает подтипы CTI, содержащие STI и OTI. Обнаружение того, что STI представляет CTI как более общий уровень аналитики угроз, тогда как OTI фокусируется более конкретно на технических деталях.
- Барнум (2014) поддерживает определение того, какие элементы идентифицируются в CTI.
- Thonnard & Dacier (2008) представляют две структуры для применения интеллектуального анализа данных и машинного обучения в даркнете, чтобы обнаружить корреляции временных рядов и кластеризацию между участниками атаки. В этом исследовании используются данные приманок за большой период времени.
- Фачха и др. (2012) построили модель KDD правила ассоциации, чтобы обнаружить корреляции между киберугрозами с использованием данных даркнета. Особое внимание уделяется выявлению индикаторов в трафике. Эта модель идентифицирует такие атаки, как DDoS, переполнение буфера и незапрашиваемый доступ к VPN.
- Робертсон (2017) представляет концепцию оперативной аналитики угроз в реальном времени на основе данных даркнета. Их модель извлекает данные из сообществ даркнета с применением стандартизированных алгоритмов машинного обучения. Представленная модель правильно предсказывает угрозы с точностью 78% -82%.
- Икономакис, Котсиантис и Тампакас (2005) подробно описывают общий процесс классификации текста и отмечают, что классификация текста представляет собой большую проблему из-за большого количества функций в текстовом документе.
- Ли и др. (2005) и Лю, Ли, Ли и Ю (2004) предлагают более эффективный метод построения модели классификации текста, в первую очередь рассматривая маркировку слов, а не документов, и используя два класса, один помечен положительно, а другой немаркирован. .
- Аль-Роуайли, Абулаиш, Аль-Хасан Халдар и Аль-Рубайан (2015) обнаружили, что BiSAL может предоставлять методы классификации текста с более точными результатами с применением морфологических вариантов в списке слов, идентифицированных индикатором полярности.
- Наконец, проблемы с классификацией текста часто возникают из-за искаженных и отрицательных выражений, обсуждаемых Аннетт и Кондрак (2008).
3. Методология
То, что обсуждалось до сих пор в этой статье, представляет собой знание того, что CTI необходимо собирать на ранних этапах атаки, чтобы она была эффективной и действенной (Hutchins, Cloppert & Amin, 2012). Понятно, что даркнет стал центральным узлом для обсуждений и продаж этих атак и, таким образом, наполнен флаконами информации для CTI. Предполагаемый результат - создание работающей системы, обеспечивающей CTI от форумов по взлому даркнета и способность предсказывать угрозы на основе новых данных. Это будет сделано на основе изученных исследований, сбора первичных данных и анализа результатов. На рисунке 7 представлен обзор системы CTI, представленной в этой статье, для сбора первичных исследований, определяющих эффективность такой системы CTI. В следующих разделах подробно описан каждый этап основного метода исследования, представленного выше.

3.1. Доступ к данным
Одним из первых этапов, необходимых для этой модели, является определение целевых веб-сайтов, содержащих информацию, относящуюся к киберугрозам. Это ручной процесс, предназначенный для поиска форумов и дискуссий в даркнете, которые содержат высокий потенциал для контента, связанного с атаками нулевого дня. Чтобы сделать правильное и решительное суждение о веб-сайтах, имеющих отношение к этому исследованию, требуется проверка функциональности сайта, чтобы понять его законность для информации об использовании. Очевидно, что многие веб-сайты Clearnet, а также сайты Darknet содержат базы данных эксплойтов, свободно доступные для общественности (Varsalone, McFadden & Morrissey, 2012). После изучения веб-сайтов Clearnet и Darknet было обнаружено, что информация об эксплойтах с легкодоступных веб-сайтов представляет меньшую угрозу для кибербезопасности и часто указывает на позицию позднего фазового обнаружения в процессе цепочки уничтожения (Hutchins, Cloppert & Amin, 2012). По сути, большой объем обнаруженной информации об эксплойтах может быть легко обнаружен владельцами программного обеспечения, системы или веб-сайта и т. Д. Таким образом, для получения доступа и извлечения ценных индикаторов угроз необходимо получить доступ к труднодоступным веб-сайтам с более конкретными ключевыми деталями. обязательный. Согласно Su & Pan (2016), эти ценные веб-сайты с эксплойтами и уязвимостями часто содержат некоторые из следующих атрибутов:
- Публикация информации об эксплойтах - сайты будут либо публиковать информацию об уязвимостях, либо недоступную или недоступную для просмотра в определенной степени.
- Обеспечение цели - Цели, оцененные в соответствии с информацией об уязвимости.
- Финансовый вклад - сайт может потребовать, чтобы пользователи заплатили за доступ или приобрели уязвимости (обычно в валюте Bitcoin3).
- Процесс проверки - как правило, эти сайты содержат либо автоматизированный процесс проверки, либо систему залога, либо только по приглашениям.
Чтобы получить доступ к этим веб-сайтам, соединение будет выполнено с использованием TOR, как описано в Разделе 1 этого документа. Следующие сообщества даркнета содержат такие атрибуты и, таким образом, будут использоваться для извлечения данных с целью построения и оценки системы CTI, изучаемой в этой статье. Ниже приводится подробное обоснование выбора веб-сайтов, использованных в этом исследовании, и метода доступа:
Остальную часть этого раздела см. в публикации.
3.2. Сбор данных
Внедрение поискового робота на каждый из трех указанных выше веб-сайтов требуется для извлечения соответствующих данных, необходимых для этого исследования. Сканеры - это программы, созданные для автоматической навигации по сети с целью получения данных (Jain & Bansal, 2014). Как правило, поисковый робот взаимодействует с веб-источником и извлекает данные, хранящиеся в нем, то есть HTML-код веб-страницы (Ferrara, De Meo, Fiumara & Baumgartner, 2014). Применение поисковых роботов позволяет собирать большие объемы данных из Интернета в автономном режиме. Однако, как отмечают Zheng, Wu, Cheng, Jiang & Liu (2013), сканирование веб-сайтов Deep / Darknet сопряжено с рядом проблем. К ним относятся доступ к определенным веб-сайтам и отсутствие какого-либо индекса для этих сайтов. В подтверждающем заявлении Jain & Bansal (2014) цитируют:
«При таком сканировании, ориентированном на широту охвата, проблемы заключаются в обнаружении источников данных, изучении и понимании интерфейса и возвращаемых результатов, чтобы можно было автоматизировать отправку запросов и извлечение данных».
Очевидно, что для успешного извлечения данных из даркнета необходимо создать уникальный сканер для каждого целевого веб-сайта, чтобы точно извлекать необходимые данные. Целенаправленный метод для этого выполняется с использованием Python и фреймворка сканирования Scrapy. Scrapy - это сборка веб-фреймворка с открытым исходным кодом для сбора данных из веб-источников. Причина использования Scrapy в качестве основы для поискового робота связана со следующими преимуществами, описанными Кузис-Лукас (2016):
- Архитектура на основе событий - позволяет пользователям выполнять каскадные операции для эффективной очистки, формирования и хранения данных. Кроме того, это позволяет «отключить задержку от пропускной способности за счет бесперебойной работы при открытых тысячах подключений» (Kouzis-Loukas, 2016).
- Scrapy позволяет пользователям выполнять запросы параллельно. Это позволяет пользователям очищать большой объем данных с сайта за короткий период времени.
- Фреймворк позволяет напрямую использовать дополнительные фреймворки Python, такие как Beautiful Soup, lxml и Selenium, чтобы понимать неработающий HTML или запутанную кодировку.
- Scrapy предоставляет селекторы для XPath высокого уровня. Это позволяет пользователям более точно извлекать определенные данные с веб-сайтов.
- Scrapy имеет хорошо поддерживаемый и организованный код. Разделение модулей Python, таких как spider и pipelines, позволяет пользователям без труда автоматически обновлять и улучшать сканеры.
Первая проблема, возникающая при создании сканеров в этом исследовании, заключается в том, что для очистки данных с адреса даркнета сканеры должны сначала иметь возможность маршрутизировать в сеть TOR. При использовании системы Linux или Mac OS X, как описано в этом документе, можно подключиться к TOR с помощью TOR SOCKS. Это позволяет трафику напрямую подключаться к Tor через порт локального хоста «9050» (The Tor Project, 2017). С помощью этой реализации можно направить поискового робота на адреса «.onion», например, перечисленные в предыдущем разделе.
Еще одна проблема заключается в коде каждого из веб-сайтов. Особое внимание уделяется веб-сайтам, которые содержат JavaScript или страницы входа. Очевидно, что все три веб-сайта, использованные для данных в рамках этого исследования, содержат такие методы проверки. К счастью, это можно решить, внедрив в краулер фреймворк Selenium Python. Selenium предоставляет пользователям простой API для написания функциональных и приемочных тестов для WebDrivers. Таким образом, можно воспроизвести взаимодействие пользователя с веб-страницей, используя автоматический код в поисковом роботе. Существенная автоматизация требуемых пользователем методов проверки («1. Установка - документация Selenium Python Bindings 2», н.д.).
Если посмотреть конкретно на то, что будет извлечено с веб-сайтов, есть определенные элементы, необходимые для анализа угроз. Конкретный формат каждого веб-сайта в этом случае содержит следующее: Заголовок темы, Сообщение темы, Автор, Время / Дата, Рейтинг. С помощью этих элементов можно собрать большой объем информации из каждого сообщения, уделяя особое внимание заголовку темы и сообщению темы. При применении извлечения текстовых функций с использованием подходов машинного обучения основное внимание будет уделяться извлечению индикаторов из заголовков тем / сообщений.
3.3. Анализ, очистка и маркировка данных
После общего просмотра форумов и форумов становится очевидным, что существует большой объем текста, который может служить помехой для классификатора. Одним из конкретных примеров этого является заголовок тем, содержащий символы (I.E * ›PRODUCT‹ *). Подобные случаи могут значительно повлиять на классификацию, и поэтому требуется анализировать эти данные без шума. Для этого метод удаления не буквенно-цифровых символов из данных реализован в классах Название темы и Тема сообщения.
Поскольку эти данные создаются пользователями, необходимо знать, что орфографические ошибки и состав слов могут быть изменены. Таким образом, поиск лучшего метода решения этой проблемы будет частью этого исследования. Оцениваемые методы содержат использование корней слов и n -грамм. В 1994 г. n -граммы были отмечены как жизнеспособные средства борьбы с шумом ASCII при вводе текста (Trenkle & Cavnar, 1994). Кроме того, Тренкле и Кавнар (1994) дополнительно цитируют:
«Основное преимущество сопоставления на основе N-граммов проистекает из самой его природы: поскольку каждая строка разбивается на мелкие части, любые присутствующие ошибки имеют тенденцию влиять только на ограниченное количество этих частей, оставляя остальную часть нетронутой. . »
Чтобы пояснить, n -грамма состоит из части текста, состоящего из символов n, что создает строку большего размера. Чтобы дать пример того, как n -грамма может поддерживать этот процесс машинного обучения, слово Trenkle & Cavnar (1994) демонстрирует n -граммы на слове «ТЕКСТ» ( «_», Обозначающий пробелы):
биграммы: _T, TE, EX, XT, T_
триграммы: _TE, TEX, EXT, XT_, T_ _
квадграммы: _TEX, TEXT, EXT_, XT_ _ , T_ _ _
Однако важно отметить, что стеммер слов в n -грамме - лишь одно решение. Таким образом, в рамках этого исследования проводится анализ различных алгоритмов определения границ, чтобы увидеть их влияние на точность нашей классификации. Будут кратко рассмотрены алгоритмы, стеммеры Lovins, стеммеры Snowball и PTStemmers.
Чтобы классифицировать данные, необходимо сначала создать набор обучающих данных, на котором машина будет учиться. Для создания набора обучающих данных важно сначала классифицировать набор данных для машины, которую будет использовать, обычно этот процесс называется маркировкой классов (Flach, 2015). Это исследование будет состоять из маркировки данных о том, рассматривается ли это как угроза (например, «Релевантность = {да, нет}»). Несмотря на то, что исследователи ранее обсуждали методы автоматизации процесса маркировки, каждый отдельный пост необходимо внимательно рассматривать, прежде чем пометить его (Sebastiani, 2002). В дополнение к этому, ниже выделен пример того, как была произведена идентификация угрозы. Эти примеры взяты с рассматриваемых веб-сайтов:
Тема сообщения: «Invoice Manager 3.1 - Уязвимость подделки межсайтовых запросов (добавление администратора)» Актуальность: Нет
Этот продукт относится к уязвимости, обнаруженной в веб-приложении для управления счетами и подключаемом модуле на основе PHP для веб-браузеров. Это распространяется как бесплатный эксплойт. В этом случае это считается угрозой низкого уровня по следующим причинам. Во-первых, как обсуждалось ранее, организации постоянно обновляют программное обеспечение, и это особенно заметно в онлайн-плагинах и приложениях. Таким образом, это означает, что эта уязвимость очень чувствительна ко времени. С учетом того, что уязвимость находится в свободном доступе для общественности, это означает, что весьма вероятно, что организация обнаружит этот эксплойт. Кроме того, сама уязвимость позволяет хакеру добавить администратора в приложение с помощью межсайтового запроса. Хотя это может быть проблемой для владельцев аккаунтов, это не представляет непосредственной высокой угрозы для пользователей или кибербезопасности.
Тема сообщения: «Windows 10 RCE (Sendbox Escape / Bypass ASLR / Bypass DEP) 0day Exploit» Актуальность: Да
Этот продукт можно рассматривать как критическую уязвимость нулевого дня. Этот эксплойт подробно описывает уязвимость в операционной системе Windows 10, которая позволяет удаленно выполнять код через любой браузер, например Google Chrome, Mozilla Firefox и Opera. Если посмотреть на дополнительные детали, тип эксплойта позволяет выйти из Sandbox Escape4. Кроме того, сам эксплойт имеет высокую стоимость и продается за 1,319 BTC или 6000 долларов США. Из-за масштаба и возможного воздействия, которое этот эксплойт может иметь в области кибербезопасности, отмечается угроза высокого уровня.
Как видно из предыдущих двух примеров, каждый помеченный элемент должен учитывать различные соображения, чтобы оправдать результат. Помня об этих деталях, создание набора обучающих данных значительного размера, чтобы иметь высокую точность и правильность, требовало особого внимания.
3.4. Подходы к машинному обучению
После того, как набор обучающих данных будет тщательно промаркирован, инструменты машинного обучения приложений должны использоваться для сортировки данных по угрозам и неугрозам. Как обсуждалось ранее в этой статье, машинное обучение влечет за собой процесс обучения правилам из экземпляров, в данном случае обучающего набора данных. Это принципиально позволяет создавать классификатор для новых экземпляров. В этом исследовании алгоритмы контролируемого обучения будут применяться к набору данных для построения модели.
Обучение с учителем - это процесс, выводящий функцию из размеченных данных обучения (Widanapathirana, 2015). Алгоритмы контролируемого обучения позволяют анализировать экземпляры в обучающих данных, применяя функцию, которая, таким образом, может использоваться для отображения новых примеров (Maglogiannis, 2007). Аналогичным образом, обучение без учителя определяется, когда экземпляры не помечены. Доступен широкий спектр алгоритмов контролируемого обучения, каждый из которых имеет разную функциональность. Каждый доступный алгоритм имеет как сильные, так и слабые стороны в зависимости от задачи. Это часто называют теоремой «Нет бесплатного обеда», что означает, что не существует единого алгоритма контролируемого обучения, который лучше всего работал бы со всеми задачами, каждый алгоритм имеет разную точность для разных задач (Wolpert & Macready, 1997). Несмотря на то, что существует обширное количество алгоритмов для анализа, в рамках отдельного исследования было бы большой задачей оценить все методы решения проблемы, представленной в этом исследовании. Поскольку задача состоит в том, чтобы исследовать функциональную систему для Darknet CTI, анализ ее эффективности будет производиться с использованием наиболее распространенных алгоритмов классификации текстов; Категории деревьев решений, байесовских, экземпляров и опорных векторов, как отмечено Робертсоном (2017), Кемингом и Цзяньго (2016). В следующих разделах будет представлен краткий обзор того, как эти алгоритмы работают по отношению к классификации текста, чтобы оценить понимание их применения при построении эффективной системы CTI.
3.4.1. Деревья решений
Дерево решений - это структура, которая классифицирует экземпляры путем сортировки узлов на основе их значений. Maglogiannis (2007) цитирует:
«Каждый узел в дереве решений представляет функцию в экземпляре, который должен быть классифицирован, и каждая ветвь представляет значение, которое этот узел может принять. Экземпляры классифицируются, начиная с корневого узла, и сортируются на основе их значений характеристик »
Изображение дерева решений в виде простой блок-схемы представлено на рисунке 8. Это дерево решений является примером того, как классификация текста может использоваться для определения жанра имени. Каждый узел будет определен как узел решения, чтобы проверять значения с листовым узлом для присвоения меток, в данном случае («Обучение классификации текста», без указания даты). Чтобы изначально присвоить метку входному значению, нужно сначала начать с корневого узла решения. В этом случае алгоритм определяет, является ли последняя буква в слове гласной, на основе того, что ему уже известно в обучающих данных. Этот корневой узел решения проверяет значение функции и выбирает ветвь. Затем этому отвечает другой узел принятия решения, который снова проверит значение на основе обучающего набора и примет решение. Этот процесс продолжается до тех пор, пока не будет встречен листовой узел, который затем предоставит метку из начального входного значения.

Этот пример, очевидно, представляет лишь небольшую часть того, что полное дерево решений повлечет за собой в большом наборе данных, но дает общее объяснение процесса. Алгоритм RandomForest предоставляет возможность эффективного метода задачи классификации в этом исследовании (Робертсон, 2017). RandomForest берет исходный экземпляр и разделяет данные на подмножества деревьев, как показано выше. По сути, это обеспечивает более комплексный подход к использованию более упрощенных алгоритмов дерева решений.
3.4.2. Статистические алгоритмы обучения
Статистические алгоритмы состоят из базовой вероятностной модели для определения вероятности принадлежности экземпляра к определенному классу. Две категории используемых алгоритмов статистического обучения включают байесовские сети и методы на основе экземпляров.
3.4.2.1. Байесовские сети
Байесовские сети относятся к группе графических моделей, основанных на вероятностных переменных. Каждый узел в графической структуре представляет случайную величину. Каждая переменная представлена вероятностной зависимостью, как показано на рисунке 9. Эти зависимости позволяют машине оценить вероятностный результат на основе того, что машине уже известно (данные обучения) (Ben-Ga, 2007).

Стоит отметить, что во многих случаях задача использования байесовских сетей часто делится на две основные категории. Это изучение структуры сети и определение параметров (Magolgiannis, 2007). Однако очевидно, что построение очень большой сети представляет собой самостоятельную задачу и неэффективно для данного исследования. Таким образом, алгоритм Наивного Байеса представляет собой очень простую байесовскую сеть для работы в рамках представленной задачи классификации.
3.4.2.2 На основе экземпляров
Алгоритмы обучения на основе экземпляров задерживают процесс индукции или обобщения до выполнения классификации, определяя его как алгоритм с отложенным обучением (Maglogiannis, 2007). Crane (n.d) описывает один из самых простых алгоритмов обучения на основе экземпляров как алгоритм ближайшего соседа. На рисунке 10 показан пример того, как работает k -Nearest Neighbor (k - NN). Данные обучения, созданные в этом эксперименте, состоят из положительного (да) и отрицательного (нет) отношения к угрозе. В этом случае xq - это экземпляр, который нужно классифицировать. Алгоритм 1-ближайшего соседа классифицируется как положительный, алгоритм 5-ближайшего соседа классифицирует его как отрицательный. С 1-ближайшим соседом созданное решение показано справа на рисунке 10. Классификатор IBk является одним из таких алгоритмов k -NN, который будет использоваться в этом исследовании. Области, показанные на изображении, представляют каждую область пространства экземпляра, близкую к этой точке. Маглогианнис (2007) объясняет это далее, заявляя:
«K-Nearest Neighbor (k-NN) основан на том принципе, что экземпляры в наборе данных обычно существуют в непосредственной близости от других экземпляров, которые имеют аналогичные свойства. Если экземпляры помечены классификационной меткой, то значение метки неклассифицированного экземпляра можно определить, наблюдая за классом его ближайших соседей. K-NN находит k ближайших экземпляров к экземпляру запроса и определяет его класс, идентифицируя единственную наиболее часто встречающуюся метку класса ».

3.4.3 Машины опорных векторов
Машины опорных векторов (SVM) очень хорошо подходят для таких настроек обучения, как классификация текста, с хорошо обоснованной теорией вычислений и анализом (Joachims, 2005). Они предполагают, что между двумя классами данных существует «гиперплоскость», разделяющая их (Maglogiannis, 2007). Применяя алгоритм SVM к набору обучающих данных, формируется оптимальная гиперплоскость, которая классифицирует экземпляры. Намерение состоит в том, чтобы максимизировать разницу между двумя классами в обучающих данных.

SVM отличается от некоторых других обсуждаемых алгоритмов тем, что они классифицируют данные на основе оптимального запаса гиперплоскости, а не характеристик данных. Это означает, что это может быть эффективным методом классификации при использовании многих функций, таких как текст (Joachims, 2005). В эксперименте, анализирующем эффективность SVM по сравнению с существующими методами классификации текста, Иоахимс (2005) приходит к следующему выводу:
«Результаты экспериментов показывают, что виртуальные машины защиты стабильно достигают хороших результатов в задачах категоризации текста, значительно
превосходя существующие методы» (Joachims, 2005)
Этот результат предлагает возможное решение для классификации данных Darknet для CTI, однако, учитывая предыдущее утверждение, необходимо учитывать теорему «Нет бесплатного обеда» и, следовательно, это
метод может не подходить для решения проблемы. В следующей оценке будет сделан обзор точности классификации SVM с использованием алгоритма последовательной минимальной оптимизации (SMO). Первоначальная проблема, с которой сталкивается при обучении машины опорных векторов, заключается в том, что для этого требуется большой объем квадратичного программирования. SMO разбивает большие задачи квадратичного программирования на более мелкие, таким образом оптимизируя процесс (Platt, 1998). Используя SMO, возможен более эффективный и действенный анализ SVM.
7. Оценка
В этом разделе будет сделана оценка каждого процесса в обзоре системы, показанном на рисунке 7. Во-первых, выделение реализации, эффективности и проблем, связанных с извлечением данных. Это будет включать в себя создание поискового робота, синтаксический анализ и маркировку данных в соответствии с методами классификации текста. Кроме того, будет произведена оценка точности методов классификации текста, используемых в этом исследовании. Завершая этот раздел, обсуждение результатов этого исследования, его результатов и его эффективности подтвердит вывод. Затем будет проведен анализ возможных отклонений, который может позволить разработать более точную или эффективную модель анализа угроз.
7.1 Извлечение и предварительная обработка данных
Как уже говорилось, для создания краулера для решения этой задачи используется среда Python Scrapy. В Приложении A подробно показано изображение исходного кода Spider в нашем поисковом роботе. Если посмотреть на код, переменные XPath используются для выбора элементов, специфичных для каждого сайта, и повторяются для синтаксического анализа. Пример этого:
post_title = response.xpath (‘// * [@ class =” subject_new ”] / text ()’)
Как и ожидалось, одной из проблем, с которыми пришлось столкнуться, была реализация JavaScript на веб-сайтах. Это было преодолено с помощью Selenium для запуска WebDrive, в данном случае ChromeDriver. После запуска он имитирует взаимодействие пользователя с каждой кнопкой и задерживает процесс, чтобы веб-сайт реагировал, как если бы это был человек. После этого поисковый робот мог свободно загрузить и извлечь переменную XPath, необходимую для построения набора данных.
Затем данные были преобразованы в документ со значениями, разделенными запятыми (CSV), чтобы создать обучающий набор данных, но с возможностью маркировки. Маркировка в этом случае была сделана вручную, в разделе 3.3 описана методология анализа каждого сообщения в теме, а также было ли оно расценено как угроза или нет. Пример извлеченных данных см. В Приложении B.
Weka использовалась для применения алгоритмов машинного обучения к набору данных, собранному веб-сканером. Weka - это программное обеспечение интеллектуального анализа данных на основе Java, содержащее набор алгоритмов машинного обучения («Weka 3 - интеллектуальный анализ данных с использованием программного обеспечения для машинного обучения с открытым исходным кодом на Java», без даты). Для правильного чтения набора данных Weka требовалось преобразование данных в формате CSV в формат файла связи атрибутов (ARFF). ARFF позволяет форматировать данные в текстовый файл, содержащий экземпляры и их атрибуты, перед интеллектуальным анализом данных («Weka 3 - Data Mining with Open Source Machine Learning Software in Java», n.d.). Обычно при преобразовании CSV в ARFF атрибуты определяются как числовые. Однако в случае классификации текста требуется, чтобы атрибуты определялись как строки. Таким образом, необходимо было выполнить предварительную обработку каждого атрибута как строки вручную. Построенный и помеченный обучающий набор состоит из данных со всех трех веб-сайтов, упомянутых в методологии.
7.2 Анализ данных
Всего с форумов было извлечено 2100 элементов данных, 600 из которых были помечены вручную для обучающих данных (Приложение B). Обратите внимание, что после применения токенизаторов вычислительные требования значительно превысили то, что было доступно для этого исследования, поэтому анализ можно было провести только в базе данных из 600 элементов. Кроме того, эти данные были зашифрованы перед обработкой, чтобы исключить любое влияние на процесс машинного обучения. Применяя фильтр StringToWordVector к данным, преобразует строковые атрибуты в дополнительный набор атрибутов, представляющих вхождения слов на основе используемого Tokenizer. Чтобы учесть проблему орфографии и шума, обсуждаемую в разделе 3.3, наиболее подходящим для решения этой проблемы является токенизатор n -грамм. Для токенизатора было установлено не более 3 n -грамм. LovinsStemmer, SnowBall Stemmer и PTStemmers показали значительно меньшую процентную точность на правильно классифицированных экземплярах и, следовательно, не были ценными и не заслуживающими включения в это исследование. После применения токенизатора n -грамм общее количество атрибутов составило 6944.
Начиная анализ, маркируются 25% данных и выполняется 10-кратная перекрестная проверка с использованием контролируемых алгоритмов обучения NaïveBayes, SMO, RandomForest и IBk. В частности, наиболее эффективными алгоритмами контролируемого обучения в этом анализе являются NaïveBayes, с 79,33% правильно классифицированных экземпляров, с небольшим отрывом от RandomForest с 78,00%. На рис. 13 показано сравнение между этими тестами «Точность», «Напоминание» и «F1».

Некоторые примечательные примеры угроз, обнаруженных алгоритмом NaïveBayes, включают тематические сообщения, в которых продаются эксплойты кода оболочки и эксплойты повышения привилегий 32-битной Windows. Примеры:
«shellcode win x8664 download execute generator»
«cve20151701 win32k повышение привилегий уязвимость»
Во втором анализе алгоритмов машинного обучения была добавлена полная база данных из 600 помеченных элементов и разделена на 25% с использованием Weka в качестве дополнения к ручному разделению данных. Это повысило эффективность классификатора NaiveBayes до 81,77% с 368 правильно классифицированными экземплярами. Алгоритмы SMO и RandomForest имеют лишь незначительную разницу менее 1% по сравнению с первым тестом. Однако производительность алгоритма IBk увеличилась с дополнительной поддержкой обучения с точностью 74%.

7.3 Обсуждение
Наиболее очевидный результат анализа машинного обучения показывает, что NaiveBayes и RandomForest обеспечивают наиболее эффективную точность из четырех классификаторов. Отмечается, что оба этих алгоритма обеспечивают высокую степень точности при классификации текстовых данных и позволяют эффективно прогнозировать угрозы. Это особенно очевидно при применении n-граммовых токенизаторов для предоставления машине большого количества атрибутов. Было обнаружено, что без применения токенизаторов n -грамм такого уровня точности будет трудно достичь. Кроме того, было отмечено, что количество помеченных данных увеличилось, точность была заметно лучше, поэтому точность классификации с 25% помеченных данных приводит к положительному и эффективному результату. В качестве общей оценки изучаемого процесса результат применения данных Darknet, просканированных через Интернет, к алгоритмам машинного обучения может обеспечить эффективный метод обеспечения CTI. Хотя очевидно, что для создания набора обучающих данных и анализа обработанных тестовых данных требуется некоторый уровень знаний, этот процесс может предоставить экспертам автоматизированную систему для анализа угроз.
Продвигая это исследование, продвигая систему для автоматизации процесса сканирования и анализа данных непосредственно в системе машинного обучения, можно создать постоянный поток ценных аналитических данных об угрозах из даркнета. Кроме того, можно провести дальнейшие исследования, применив полууправляемые алгоритмы для проверки эффективности, которые могут подтвердить необходимость маркировки данных.
После изучения и реализации каждого этапа системы, представленной на Рисунке 7, эффективность и потенциальные возможности такой модели CTI становятся очевидными. В заключение, хотя каждый этап представлял ряд проблем, сам процесс представляет собой в значительной степени убедительный и ценный результат для первичного исследования. Это исследование показало, что эффективный и точный уровень интеллекта CTI из даркнета можно получить с помощью веб-сканеров и машинного обучения.
8. Заключение
Предполагаемая цель этого исследования состояла в том, чтобы изучить применение интеллектуального анализа данных, машинного обучения и извлечения текстовых функций на форумах по взлому даркнета для обеспечения CTI. Было обнаружено, что, несмотря на то, что в каждой отдельной области проводилось много исследований, только небольшое количество исследований проводилось с этой конкретной целью. Это подчеркивает важность CTI на основе данных, генерируемых пользователем, в отличие от данных, генерируемых системой. В частности, хотя CTI может быть получен из трафика или протоколов даркнета, он не может предоставить специалистам по безопасности жизненно важную информацию о потенциальных и возникающих атаках. Более того, CTI применялся по-разному и иногда может быть истолкован неверно. Разъяснение относительно того, представляет ли метод CTI упреждающее обнаружение атаки на «ранней фазе», имеет первостепенное значение для индустрии кибербезопасности, на которую направлено данное исследование. Это в рамках обсуждения и общения пользователей на хакерских форумах и сайтах даркнета, которые содержат ключевые индикаторы потенциальных кибератак. Один из наиболее важных выводов, сделанных в результате этого исследования, заключается в том, что сбор данных из сообществ хакеров даркнета является эффективным средством разработки упреждающего подхода к информации об атаках. По сути, это позволяет специалистам по безопасности иметь преимущество против эксплойтов, чтобы смягчить будущие или возникающие атаки. Первичное исследование этого исследования собирало и обрабатывало данные Darknet, применяя веб-сканеры к скрытым хакерским форумам. Это предоставило эффективные средства извлечения данных, специфичных для атрибутов, необходимых для машинного обучения. Сканеры могут позволить исследователям и профессионалам собирать информацию из любой области Интернета. Затем эти данные были использованы
в рамках машинного обучения для разработки модели, которая может предсказывать киберугрозы. Это решает большое количество проблем, связанных с кибератаками, которые ставят перед специалистами по кибербезопасности, как обсуждалось ранее, путем устранения «неизвестных неизвестных» и превращения их в «известные известные» MWR InfoSecurity (2015). Комбинация веб-сканеров, интеллектуального анализа данных, машинного обучения и извлечения текстовых функций обеспечивает эффективное решение для обработки данных о кибератаках в реальном времени и с учетом времени. Кроме того, уровень информации, предоставляемой этой системой, поддерживает расследование эксплойта вручную, что позволяет получить такую информацию, как ссылка на веб-страницу, автор и опубликованное время. Одним из наиболее важных аспектов этого исследования является то, что этот метод CTI не ограничивается одним вектором атаки или отраслью. Таким образом, его ценность очевидна для широкого спектра вычислений и может применяться во множестве сценариев. Рекомендации для будущих исследований могут повлечь за собой изучение таких систем, как эта, в различных областях киберпреступности. Более того, исследования по этой теме могут быть перенесены в даркнет, как обнаружение детской порнографии или радикального терроризма. Это может позволить правоохранительным органам отслеживать активность в даркнете в связи с конкретным преступлением или расследованием. Дополнительная область исследований может повлечь за собой развитие машинного обучения для классификации текстовых данных. Более конкретный подход к созданию инструментов машинного обучения для более точной маркировки и прогнозирования экземпляров. В заключение, в этом исследовании рассматриваются исследования, уже собранные в области машинного обучения и CTI в даркнете. При этом первичные исследования в этой области были собраны путем разработки системы, основанной на знаниях, полученных в результате веб-сканирования и машинного обучения, чтобы предоставить средства и решение для Darknet CTI. Эффективность машинного обучения для CTI была положительно оценена как упреждающий подход к противодействию кибератакам. Наконец, доказательство этого было сделано с помощью рабочего метода, который может предсказывать киберугрозы с точностью 81,77% на основе 6944 атрибутов, 600 экземпляров и модели обучения с 25% метками.
9. Ссылки
Форум 0day - Домашняя страница. 0day Форум. Получено 5 сентября 2017 г. с сайта http://qzbkwswfv5k2oj5d.onion.
1. Установка - документация Selenium Python Bindings 2. Селен - python.readthedocs.io. Получено 1 сентября 2017 г. с сайта http: // selenium- python.readthedocs.io/installation.html#introduction.
ABI-Research. (2017). Машинное обучение в кибербезопасности для увеличения расходов на большие данные, аналитику и аналитику до 96 миллиардов долларов к 2021 году. Abiresearch.com. Получено 18 августа 2017 г. с сайта https://www.abiresearch.com/press/machine-learning-cybersecurity-boost-big-data- inte /
ACS. (2016). Кибербезопасность: угрозы, вызовы, возможности. Получено с https://www.acs.org.au/content/dam/acs/acs-publications/ACS_Cybersecurity_Guide.pdf
Аль-Ровайли, К., Абулаиш, М., Аль-Хасан Халдар, Н., и Аль-Рубайан, М. (2015). BiSAL - двуязычный лексикон анализа настроений для анализа форумов Dark Web на предмет кибербезопасности. Цифровое расследование, 14, 53–62. Http://dx.doi.org/10.1016/j.diin.2015.07.006
Аннетт М. и Кондрак Г. (2008). Сравнение методов анализа настроений: поляризационные блоги о фильмах. Достижения в области искусственного интеллекта, 5032, 25–35. Получено с https: //link.springer .com / chapter / 10.1007% 2F978–3–540–68825–9_3
Armona, L., & Stackman, D. (2014). Изучение рынков даркнета.
Барнум, С. (2014). Стандартизация информации разведки киберугроз с помощью структурированной информации об угрозах (STIXTM). Получено с https://stixproject.github.io/about/STIX_Whitepaper_v1.1.pdf
Бен-Га, Л. (2007). Байесовские сети. Энциклопедия статистики качества и надежности.
Чаудри, П. (2017). Надвигающаяся тень незаконной торговли в Интернете. Business Horizons, 60 (1), 77–89. Http://dx.doi.org/10.1016/j.bushor.2016.09.002
Чианкаглини, В., Бальдуцци, М., Гончаров, М., и МакАрдл, Р. (2013). Deepweb и киберпреступность - дело не только в TOR. Получено с http://www.trendmicro.ie/media/wp/deepweb-and-cybercrime-whitepaper-en.pdf
Крейн, Б. Обучение на основе экземпляров (AKA Rote Learning) - Бетопедия. Wiki.bethanycrane.com. Получено 3 сентября 2017 г. с сайта http://wiki.bethanycrane.com/instance-based-learning
Даниэль - Домой. (2017). Danwin1210.me. Получено 1 сентября 2017 г. с сайта https://danwin1210.me/.
Дуа, С., & Ду, X. (2016). Интеллектуальный анализ данных и машинное обучение в кибербезопасности. CRC Press.
Епишкина А., Запечников С. (2016). Программа по интеллектуальному анализу данных и машинному обучению с приложениями для кибербезопасности. 2016 Третья международная конференция по цифровой обработке информации, интеллектуальному анализу данных и беспроводной связи (DIPDMWC). Http://dx.doi.org/10.1109/dipdmwc.2016.7529388
Известные торговые площадки даркнета для покупки эксплойтов - уязвимости нулевого дня - вредоносные программы для исследований. (2015). Международный институт кибербезопасности. Получено 1 сентября 2017 г. с сайта https://iicybersecurity.wordpress.com/2015/06/10/famous-dark-net-marketplaces-to- buy-exploits-0-day-weakrabilities-malwares-for-research /
Феррара, Э., Де Мео, П., Фьюмара, Г., & Баумгартнер, Р. (2014). Извлечение веб-данных, приложения и методы: обзор. Системы, основанные на знаниях, 70, 301–323. Http://dx.doi.org/10.1016/j.knosys.2014.07.007
Фишер Э. (2016). Проблемы и вызовы кибербезопасности: кратко. Получено с https://fas.org/sgp/crs/misc/R43831.pdf
Флах, П. (2015). Машинное обучение: искусство и наука об алгоритмах, распознающих данные. Кембридж: Издательство Кембриджского университета.
Фримантл П. и Скотт П. (2017). Обзор безопасного промежуточного программного обеспечения для Интернета вещей. Peerj Computer Science, 3, e114. Http://dx.doi.org/10.7717/peerj-cs.114
Гудин Д. (2017). Рекордные DDoS-атаки, как сообщается, ›145 тыс. Взломанных камер. Ars Technica. Получено 17 августа 2017 г. с веб-сайта https://arstechnica.com/information- technology / 2016/09 / botnet-of-145k-camera-reportly-delivery-internets-large-ddos-ever /.
Хайленд, Х. (1997). История компьютерных вирусов - знаменитое трио. Компьютеры и безопасность, 16 (5), 416–429. Http://dx.doi.org/10.1016/s0167-4048(97)82246-8
Хатчинс, Э., Клопперт, М., & Амин, Р. (2012). Интеллектуальная защита компьютерной сети, основанная на анализе противоборствующих кампаний и цепочек уничтожения вторжений. Корпорация Локхид Мартин. Получено с http://www.lockheedmartin.com/content/dam/lockheed/data/corporate/documents/LM-White- Paper-Intel-Driven-Defense.pdf
Икономакис, М., Коциантис, С., и Тампакас, В. (2005). Классификация текста с использованием техники машинного обучения. WSEAS ОПЕРАЦИИ НА КОМПЬЮТЕРАХ, 4 (8), 966–974.
Inj3ct0r Exploit DataBase. (2015). Facebook.com. Получено 1 сентября 2017 г. с сайта https://www.facebook.com/inj3ct0rs/posts/923071377754222
Джайн П. и Бансал М. (2014). Эффективное сканирование глубокой сети. Международный журнал перспективных исследований в области компьютерных наук и разработки программного обеспечения, 4 (5).
Цзинь, Х., де Вел, О., Чжан, К., и Лю, Н. (2008). Обнаружение знаний из данных приманки для мониторинга вредоносных атак. AI 2008: достижения в области искусственного интеллекта, 470–481. Http://dx.doi.org/10.1007/978-3-540-89378-3_48
Иоахим, Т. (2005). Категоризация текста с помощью машин опорных векторов: обучение с помощью множества важных функций. European Conference on Machine Learning, 98, 137–142.
Кеминг, К., и Цзяньго, З. (2016). Исследования по классификации текстов на основе обработки естественного языка и машинного обучения. Балканская трибологическая ассоциация, 22 (3–1), 2484–2494.
Колиас, К., Камбуракис, Г., Ставру, А., и Воас, Дж. (2017). DDoS в IoT: Mirai и другие ботнеты. Компьютер, 50 (7), 80–84. Http://dx.doi.org/10.1109/mc.2017.201
Кононенко И., Кукар М. (2013). Машинное обучение и интеллектуальный анализ данных. Оксфорд [u.a.]: Woodhead Publ.
Кузис-Лукас, Д. (2016). Изучение Scrapy. Пакт Паблишинг Лтд.
Учимся классифицировать текст. Nltk.org. Получено 3 сентября 2017 г. с сайта http://www.nltk.org/book/ch06.html.
Ли, X., & Лю, Б. (2005). Учимся классифицировать тексты с использованием положительных и немаркированных данных. Получено с https://www.ijcai.org/Proceedings/03/Papers/087.pdf
Ли, X., Ng, S., & Wang, J. (2014). Биологический анализ данных и его приложения в здравоохранении. Сингапур: World Scientific Pub. Компания
Лю Б., Ли X., Ли В. и Ю П. (2004). Классификация текста по надписи на словах. Получено с http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.66.572&rep=rep1&type=pdf
Маглогианнис И. (2007). Новые приложения искусственного интеллекта в компьютерной инженерии. Амстердам: IOS Press.
МакКаллум, А., & Нигам, К. (2005). Сравнение моделей событий для наивной байесовской классификации текста. Получено с сайта http://staff.icar.cnr.it/manco/Teaching/2005/datamining/articoli/multinomial-aaaiws98.pdf
Милошевич, Н. (2013). История вредоносных программ. Получено с https://arxiv.org/pdf/1302.5392.pdf
MWR Infosecurity. (2015). Анализ угроз: сбор, анализ, оценка. CPNI. Получено с https://www.ncsc.gov.uk/content/files/protected_files/guidance_files/MWR_Threat_Intelligen »ce_whitepaper-2015.pdf
Назарио, Дж. (2004). Стратегии защиты и обнаружения от интернет-червей. Бостон (Массачусетс): Artech House.
Нигам К., МакКаллум А., Трун С. и Мичелл Т. (2017). Классификация текста из помеченных и немаркированных документов с помощью EM. Машинное обучение, 39 (2–3), 103–134. Получено из https: //link.springer .com / article / 10.1023% 2F A% 3A1007692713085? LI = true
Оманд, Д. (2015). Даркнет: контроль над преступным миром Интернета | Институт мировой политики. Worldpolicy.org. Получено 17 августа 2017 г. с сайта http://www.worldpolicy.org/journal/winter2015/dark-net.
OpenCV. Пример машины опорных векторов. Получено с сайта http://docs.opencv.org/2.4/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
Панг Б. и Ли Л. (2008). Анализ мнений и настроений. Основы и тенденции® в поиске информации, 2 (1-2). Http://dx.doi.org/http://dx.doi.org/10.1561/1500000011
Планке, Д. (2017). Анализ киберугроз: от путаницы к ясности; Расследование Cyber Threat Intelligence. Получено с https://www.csacademy.nl/images/scripties/2017/Daan- Planque_CSA_Thesis_Cyber_Threat_Intelligence_Final.pdf
Платт Дж. (1998). Быстрое обучение машин опорных векторов с помощью последовательной минимальной оптимизации. Получено с сайта https://www.microsoft.com/en-us/research/wp- content / uploads / 2016/02 / smo-book.pdf
Регистрация. (2017). 0day Форум. Получено 1 сентября 2017 г. с сайта http://qzbkwswfv5k2oj5d.onion.
Рид Ф. и Харриган М. (2012). Анализ анонимности в системе Биткойн. Безопасность и конфиденциальность в социальных сетях, 197–223. Получено с
https: //link.springer .com / chapter / 10.1007 / 978–1–4614–4139–7_10
Робертсон Дж. (2017). Интеллектуальный анализ киберугроз в Darkweb. Издательство Кембриджского университета.
Сабанал П., Ясон М. (2012). Углубляясь в песочницу Flash. Получено с http://media.blackhat.com/bh-us- 12 / Briefings / Sabanal / BH_US_12_Sabanal_Digging_Deep_WP .pdf
Сантини, М. (2013). Машинное обучение для языковых технологий - деревья принятия решений и ближайшие соседи. Презентация, www.forum.santini.se.
Себастьяни, Ф. (2002). Машинное обучение в автоматизированной категоризации текста. ACM Computing Surveys, 34 (1), 1–47. Http://dx.doi.org/10.1145/505282.505283
Су, Х., и Пан, Дж. (2016). Платформа краудсорсинга для управления совместной работой при проверке уязвимостей. Симпозиум по сетевым операциям и управлению (APNOMS). Http://dx.doi.org/10.1109/APNOMS.2016.7737235
Telefonica. (2016). Анализ команды Inj3ct0r. Получено с https://www.elevenpaths.com/wp- content / uploads / 2016/10 / CyberSecurity_Avatar_Inj3ct0r_v1_0_EN.pdf
Министерство обороны. (2016). Cyber Primer. МО. Получено с https://www.gov.uk/government/uploads/system/uploads/attachment_data/file/549291/20160 »720-Cyber_Primer_ed_2_secured.pdf
Проект Tor, I. (2017). Проект Tor: инструкции по установке Mac OS X. Torproject.org. Получено 1 сентября 2017 г. с сайта https://www.torproject.org/docs/tor-doc-osx.html.en
Тоннард О. и Дасье М. (2008). Фреймворк для обнаружения шаблонов атак в данных сети. Цифровое расследование, 5, S128-S139. Http://dx.doi.org/10.1016/j.diin.2008.05.012
Торнтон, К. KR-IST Лекция 9a Байесовские сети. Users.sussex.ac.uk. Получено 3 сентября 2017 г. с сайта http://users.sussex.ac.uk/~christ/crs/kr-ist/lec09a.html
Тренкл, Дж., & Кавнар, В. (1994). Категоризация текста на основе N-граммов
Министерство обороны США. (2017). Словарь военных и связанных терминов Министерства обороны США. Получено с http://www.dtic.mil/doctrine/new_pubs/dictionary.pdf
Варсалон Дж., Макфадден М. и Моррисси С. (2012). Защита от черных искусств. Бока-Ратон, Флорида: CRC Press.
Verizon. (2015). Отчет о расследовании утечки данных. Получено с http://www.verizonenterprise.com/resources/reports/rp_data-breach-investigation- report_2015_en_xg.pdf
Weka 3 - интеллектуальный анализ данных с помощью программного обеспечения для машинного обучения с открытым исходным кодом на Java. Cs.waikato.ac.nz. Получено 4 сентября 2017 г. с сайта http://www.cs.waikato.ac.nz/ml/weka/.
Виданапатирана, К. (2015). Интеллектуальные методы вывода для автоматической диагностики сети.
Вольперт Д. и Макреди В. (1997). Нет теорем о бесплатном обеде для оптимизации. IEEE Transactions по эволюционным вычислениям, 1 (1), 67–82. Http://dx.doi.org/10.1109/4235.585893
Инициатива нулевого дня. (2017). Zerodayinitiative.com. Получено 17 августа 2017 г. с сайта http://zerodayinitiative.com/advisories/published/2016/.
Чжэн, К., Ву, З., Ченг, X., Цзян, Л., и Лю, Дж. (2013). Учимся сканировать глубокую сеть. Информационные системы, 38 (6), 801–819. Http://dx.doi.org/10.1016/j.is.2013.02.001