
Сравнительная оценка источника: она тоже удаляет шум!
Использование встраивания источников для удаления динамического шума из монофонического звука
Представьте, что вы записываете еженедельное собрание компании, которое планируете расшифровать позже. Вы кладете смартфон в центр стола для совещаний, нажимаете запись и начинаете обдумывать еженедельные цели своей команды. Расшифровывая аудиозапись на следующий день, вы поражаетесь тому, насколько сложно ее понять временами. То, что во время встречи вызывало оживленные дискуссии, превращается в беспорядок, потому что на заднем плане гудят машины. Люминесцентные светильники и системы вентиляции и кондиционирования в конференц-зале также создают раздражающий гул на протяжении всей записи. В середине встречи ваш коллега подышит свежим воздухом, открыв окно. Это имело непредвиденные последствия, так как в питомнике через улицу доносился громкий отвлекающий лай собаки.
Проблемы, затронутые в приведенном выше сценарии, относятся к числу основных проблем обработки монофонического (однодорожечного) звука. Слуховая система человека способна локализовать и изолировать различные источники звука и сосредоточиться только на тех, которые она считает наиболее интересными. Мы делаем это подсознательно, используя сложный набор слуховых органов чувств в сочетании со сложной когнитивной обработкой, которая включает понимание контекста, в котором возникают звуки. Единственный микрофон на смартфоне (на самом деле в телефонах обычно используются массивы, хотя их смещение невелико) не хватает этого сложного механизма, который есть у людей для фильтрации отвлекающих факторов. Наша предыдущая запись в блоге о контрастной оценке источников (SCE) для слепого разделения источников показывает, насколько глубокие нейронные сети могут быть использованы для изоляции различных динамиков в монофонических аудиозаписях. В этом посте описывается работа Lab41 по адаптации этой техники для удаления источников шума также из монофонических записей.
Возвращаясь к сценарию еженедельного собрания, здесь присутствует два типа шума: стационарный и нестационарный (или динамический). Стационарный шум возникает из-за постоянного гула, исходящего от осветительных приборов. Этот тип шума легко обнаруживается и удаляется с помощью традиционных методов обработки сигналов, таких как фильтры Винера или Калмана. Эти методы полагаются на шум, имеющий некоторую статистическую регулярность, и являются стандартной частью многих коммерческих аудиоконвейеров. Убрать динамические шумы гораздо сложнее. Шум от лая собак - хороший пример нестационарного шума. На следующем рисунке показано отсутствие статистической регулярности как в форме звуковой волны, так и в спектрограмме лающей собаки в сравнении с шумом от системы HVAC (белый шум).

Хотя динамическое шумоподавление популярно в потребительских устройствах (наушники с шумоподавлением и т. Д.), Все они полагаются на наличие фиксированного набора микрофонов, специально откалиброванного для определенных задач (например, смартфоны слушают команды человеческого голоса и т. Д.). Это не так во многих сценариях, в том числе с удаленными динамиками (записывающие устройства плохо откалиброваны для этого), неизвестным количеством отвлекающих шумов, комнатами с неизвестной импульсной характеристикой и т. Д. Устранение стационарного шума - относительно простая задача. Идентификация и извлечение динамического шума сложнее и требует моделирования и автоматического выделения конкретных источников каждого типа шума.
За последнее десятилетие подходы к машинному обучению начали успешно устранять динамический шум. В частности, оказалась полезной адаптация методов матричной факторизации к обработке спектральных представлений аудиосигналов. Эти методы сложно сделать эффективными, и во многих случаях требуется дополнительная сложность для точного моделирования характеристик источника. Хотя мы исследовали один такой метод (факторизация разреженной неотрицательной матрицы (SNMF)), этот алгоритм показывает неоптимальную производительность по сравнению с нелинейными подходами (то есть нейронными сетями).
Удаление динамического шума требует значительного объема моделирования для устранения неоднозначности как сигналов (человеческие динамики), так и шумов (например, лай собак), каждый из которых имеет очень сложные временные паттерны. Разве не было бы хорошо, если бы можно было изучить временные закономерности для каждого источника, а не прибегать к линейным приближениям или придумывать специальные модели, созданные вручную? Действительно, глубокие нейронные сети хорошо подходят для таких задач, как продемонстрировано в нашей работе с использованием SCE для разделения нескольких динамиков в монофоническом аудио. Мы использовали эту работу, чтобы смоделировать набор источников шума вместе с человеческими голосами, чтобы разделить их. Однако мы внесли несколько улучшений, которые дополнительно оптимизируют мощность разделения источников в контексте шумоподавления.
Напомним, что SCE изучает плотное представление «встраиваемого вектора» для каждого частотно-временного (t-f) значений в спектрограмме БПФ. Каждое значение t-f присваивается известному набору источников с помощью процедуры маскирования по принципу «все или ничего» (каждое значение t-f присваивается одному и только одному источнику). Во время обучения векторы, принадлежащие разным источникам, разделяются, в то время как векторы из одного источника сдвигаются вместе. Чтобы затем изолировать источники, вектор вычисляется для каждого значения t-f, и выполняется кластеризация с использованием K -средних для группировки значений t-f. Затем каждая группа значений t-f подвергается обратному преобразованию с помощью операции обратного БПФ (iFFT) в результирующую форму сигнала. Это оптимальная процедура при соблюдении следующих критериев:
1. Разделить произвольное количество источников.
2. Количество источников постоянно и известно.
3. Кластеры для всех источников в пространстве встраивания изотропны и хорошо разделены (т. Е. Способствуют кластеризации K -средств).
Наше решение для шумоподавления черпает вдохновение в недавней работе о разделении музыки и певца. Здесь также существует всего две большие категории источников, которые необходимо разделить. Вместо кластеризации векторов внедрения изучается нелинейное преобразование, которое берет каждый вектор и изучает так называемые маски отношения, которые пропорционально разделяют каждое значение t-f между категориями певец и музыка. Процесс оценки этих масок называется выводом маски (MI). Затем спектральная величина умножается на каждую маску отношения и проходит через операцию iFFT, чтобы получить формы сигналов для каждого источника. Во время обучения член потерь, который соответствует ошибке восстановления спектрограммы с коэффициентом маскирования, добавляется к потерям при глубокой кластеризации (DC). В нашей реализации мы использовали потери SCE, а не потери постоянного тока. Эта архитектура с двумя источниками показана ниже.
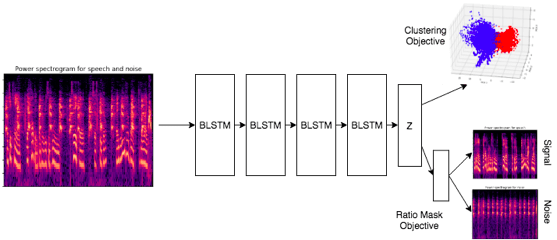
Здесь мы видим, что после того, как спектральная амплитуда проходит через четыре двунаправленных слоя LSTM (BLSTM) и последний слой линейного изменения формы (Z), выходные данные направляются как в цель кластеризации, так и в цель маски отношения, специально разработанную для разделения только сигнала ( человеческая речь) и шум (например, лай собаки).
Мы обучили нашу и несколько других сетевых архитектур и сравнили производительность шумоподавления с использованием комбинации речевого слова LibriSpeech и наборов данных шума UrbanSound8K. Присутствующие шумы варьировались от периодических (HVAC, отбойный молоток) до очень нестационарных (лай собак, уличная музыка). В качестве основы для глубокого обучения мы протестировали шумоподавляющий автоэнкодер (DAE), целью которого было восстановить чистую спектрограмму с использованием зашумленной версии. Мы также протестировали вывод маски в сочетании с глубокой кластеризацией (MI + DC) и вывод маски в сочетании с SCE (MI + SCE). Эти две сети могут выполнять как кластеризацию ©, так и вывод по маске (MI). Таким образом, мы протестировали оба метода отделения сигнала от шума.
Ниже приведены характеристики этих алгоритмов с точки зрения улучшения отношения искажений источника (SDR) по сравнению с входным SNR.
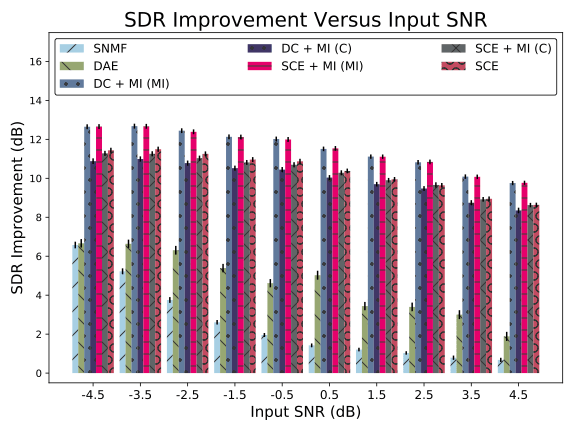
Производительность головы логического вывода маски SCE + MI находится на одном уровне с DC + MI (+13 дБ при входном SNR [-5, -4] дБ), в то время как производительность кластеризации SCE (+11,5 дБ) немного ниже. лучше, чем кластеризация алгоритмов SCE + MI и DC + MI. Следовательно, SCE может быть более желательным, когда количество разделяемых источников является произвольным. Производительность методов, основанных на глубоком обучении, относительно стабильна для входных SNR, в то время как SNMF видит более существенные различия. Кроме того, улучшения в SDR наиболее заметны для входов с более низким SNR. Это можно объяснить тем фактом, что при более высоких значениях отношения сигнал / шум на входе сигнал уже достаточно заметен, поэтому возможности для улучшения меньше. А теперь сравнение производительности и типа шума:
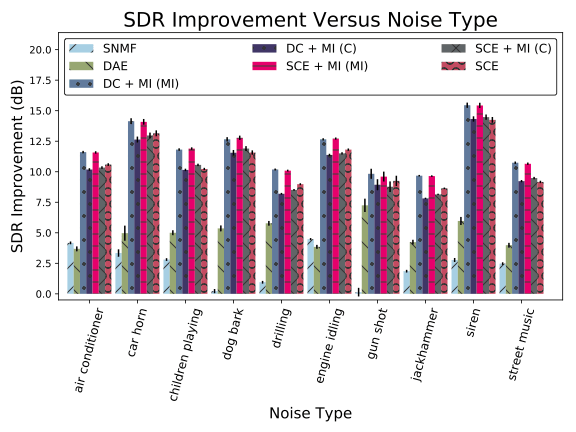
В целом, улучшения в SDR наиболее заметны для более статистически стационарных источников шума, а методы глубокого обучения работают достаточно хорошо как для стационарных, так и для нестационарных источников шума.
С такими многообещающими результатами есть несколько возможностей для изучения и улучшения. Одно из таких исследований состоит в том, чтобы лучше согласовать цели кластеризации K -средств и обучения векторному пространству (т. Е. Критерий 3 в приведенном выше обсуждении). Еще один метод потенциального улучшения - это использование сигналов как на входе, так и на выходе сети, которая изучает разреженное представление и может разделять произвольное количество источников.