В этой части мы продолжим обсуждение оптимизаторов. В предыдущей статье я показал на очень простом примере, как работают оптимизаторы и как выбор параметров влияет на то, как они движутся к минимумам. Пришло время протестировать их на наборе данных MNIST и посмотреть, какой из них лучший.
Способы оценки производительности оптимизатора
Очевидный способ назвать лучший оптимизатор - это ранжировать их по полученной точности проверки к концу обучения. Однако это сложно. Как вы видели в предыдущей части, некоторые оптимизаторы могут достигать минимумов очень быстро, тогда как другие будут двигаться очень медленно. Если вы тренируетесь в течение 100 эпох, вы можете не быть уверены, что значение, которое вы видите на 100-й эпохе, не улучшится в 101-ю эпоху.
Более того, инициализация весов нашей нейронной сети (которую мы обсудим в следующих частях) подразумевает случайность, поэтому каждый раз, когда вы тренируете свои сети, конечные результаты могут значительно отличаться для одного и того же набора параметров. Чтобы сделать результаты сопоставимыми, кажется разумным усреднить результаты каждого оптимизатора по некоторому количеству экспериментов.
Еще одна случайность для многих типов оптимизаторов - это вычисление и применение градиентов. Вспомните SGD, который использует случайный мини-пакет для вычисления ошибки и решения, в каком направлении двигаться на следующем шаге. Это вызывает ситуации, когда в середине обучения вы видите, что оптимизатору повезло и он получил очень репрезентативный мини-пакет, который позволил ему значительно повысить точность по всему набору валидации. Но на следующем этапе он получает не очень сбалансированную мини-партию, точность падает и никогда не возвращается к максимуму. Есть способы справиться с такими ситуациями, которые будут рассмотрены позже в этой серии, но пока предположим, что их не существует. В этом случае стоит изучить, насколько далеко максимальное значение точности, наблюдаемое за весь процесс обучения, от значения точности, полученного в последнюю эпоху. Если разница велика, мы можем сказать, что обучение было нестабильным, и максимальная точность, которую мы наблюдаем для конкретной конфигурации, является всего лишь разовым событием, на которое мы не можем полагаться. С другой стороны, если наблюдаемая максимальная точность близка к значению для последней эпохи, мы можем быть уверены, что результаты этой конкретной конфигурации воспроизводимы.
Подводя итог, мы будем тестировать оптимизаторы с двух точек зрения: какова максимальная точность, усредненная по пяти экспериментам, и насколько далеко этот максимум от среднего значения точности за последнюю эпоху.
Результаты эксперимента - Факты
Для вашего удобства вот ссылка на всю таблицу рейтингов. (Я выделил конфигурации, которые совсем не сходились или которые имеют значения точности ниже 90, на отдельный лист.)
В части 2 при тестировании различных функций активации с помощью оптимизатора RMSProp максимальная наблюдаемая точность составила 98,2 для активации SELU, а максимальная усредненная точность составила 98,02 для активации ELU, как для нормализованных данных. На этот раз, изменив оптимизатор и настроив параметры, мы смогли значительно улучшить эти результаты. Усредненный максимум теперь составляет 98,17 для активации ELU с настроенным оптимизатором Adamax на нормализованных данных, а общий максимум составляет 98,37 для активации SELU с настроенным Adam на стандартизованных данных.
Теперь давайте рассмотрим топ-20 конфигураций, отсортированных по усредненному максимуму:
Первое, что вы можете заметить, это то, что в этой топ-20 присутствуют только две активации: ELU и SELU. Фактически, они полностью входят в топ-100, за исключением SoftPlus, который 3 раза попадает в топ-100.
Далее, не существует единственного оптимизатора, который можно было бы назвать «лучшим». Разница между первым и 20-м местом всего 0,08%. Кроме того, у большинства наиболее эффективных оптимизаторов есть параметры, отличные от параметров по умолчанию. Есть несколько случаев, когда оптимизаторы, обученные с параметрами по умолчанию, работают немного лучше, чем настроенные, но в целом мы видим, что точная настройка параметров оптимизатора приводит к более высокой точности.
Кроме того, нет четкого предпочтения с точки зрения типа преобразования данных: в равной степени присутствуют как нормализованные, так и стандартизованные типы.
Примечательно то, что разница между максимальным достигнутым значением и значением в последнюю эпоху может очень сильно отличаться, как и разница между одним и тем же усредненным максимумом и максимумом в пяти экспериментах. Вверху есть как очень стабильные конфигурации (например, №1, 3), так и те, для которых эти различия относительно велики (№12, 16).
Вот как выглядит общая картина:
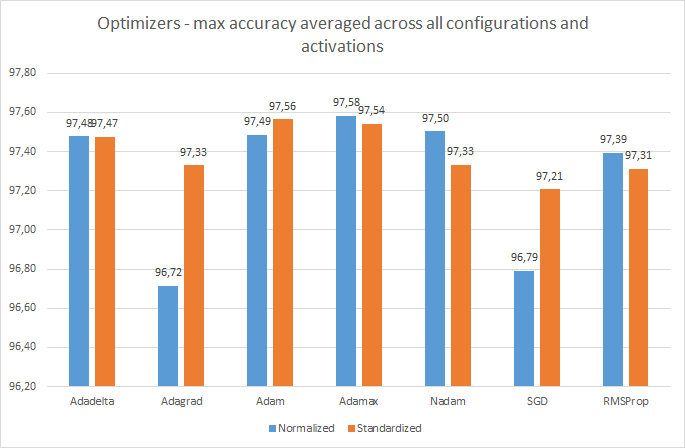
Мы видим, что оптимизаторы на основе Adam работают лучше, а Adamax показывает лучшие результаты. Я понимаю, что их усреднение не очень научно. Лучше сравнить конкретные конфигурации этих оптимизаторов. Тем не менее, эта картина является хорошей иллюстрацией общих тенденций в результатах моего эксперимента. Чтобы подтвердить эту тенденцию, давайте посмотрим на те же усредненные значения, но только для активации ELU:
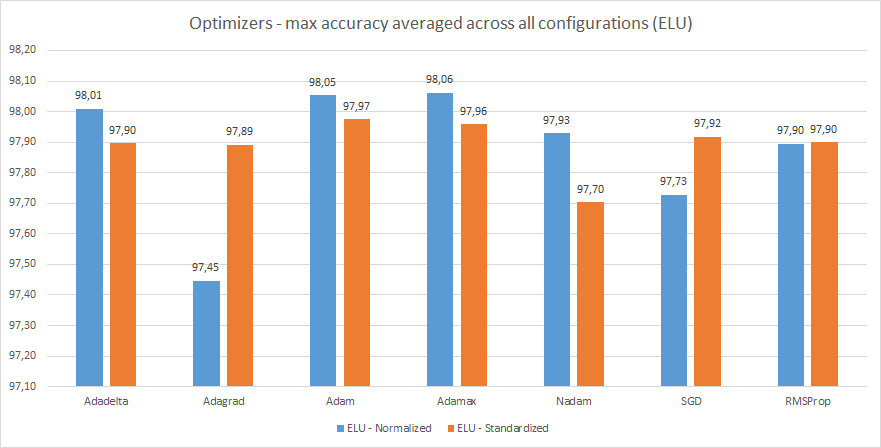
Адам и Адамакс снова стали лучшими, за ними следуют Ададелта и RMSProp.
Теперь давайте подробнее рассмотрим каждый оптимизатор и обсудим, какие из них работают лучше всего.
SGD
Использование правильного значения импульса значительно повышает точность: в нашем случае значение 0,9 показало лучшие результаты как на нормализованных, так и на стандартизованных данных. Импульс Нестерова не сильно повлиял на точность, но в других задачах разница может быть больше. Так что здесь рекомендуется всегда использовать Нестерова - хуже не будет.
На этой диаграмме показана максимальная точность, усредненная по всем функциям активации. Таким образом, вы получите представление об общей производительности различных конфигураций оптимизатора и не будете ошеломлены количеством столбцов.

Что касается типов преобразования данных и активаций, SGD лучше работает со стандартизованными данными с активациями ELU и SELU.
Адаград
Этот оптимизатор не имеет настраиваемых параметров, поэтому здесь мы можем копнуть на один уровень глубже и показать производительность для каждой активации:
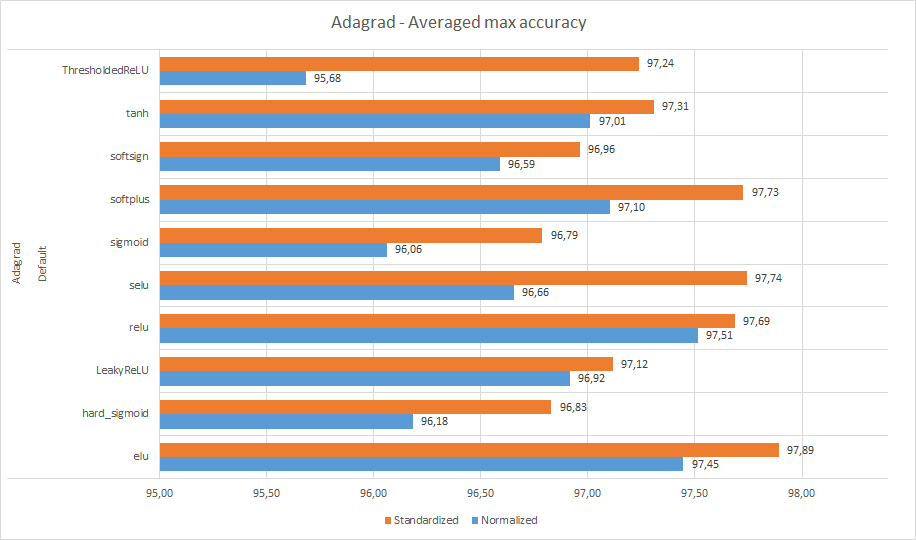
Очевидно, что оптимизатор отдает предпочтение стандартизированным данным. И как и раньше, активация ELU была лучшей, а ReLU, похоже, идет вторым.
RMSProp
Здесь конфигурация по умолчанию была не лучшей:
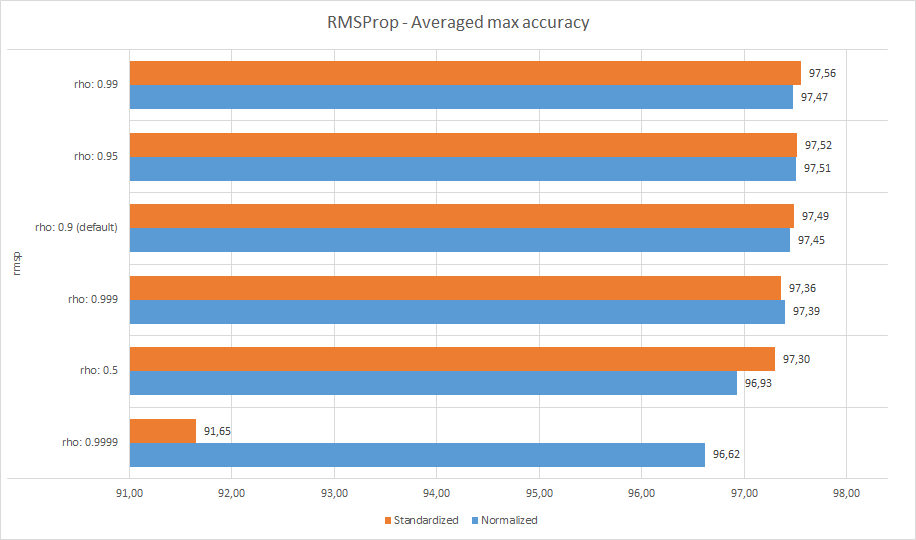
Более высокие значения RHO приводят к более высокой точности как стандартизованных, так и нормализованных данных. Однако при слишком высоком RHO (0,999) производительность значительно падает. Поэтому рекомендуется проверять значения в диапазоне 0,9–0,99 при использовании этого оптимизатора.
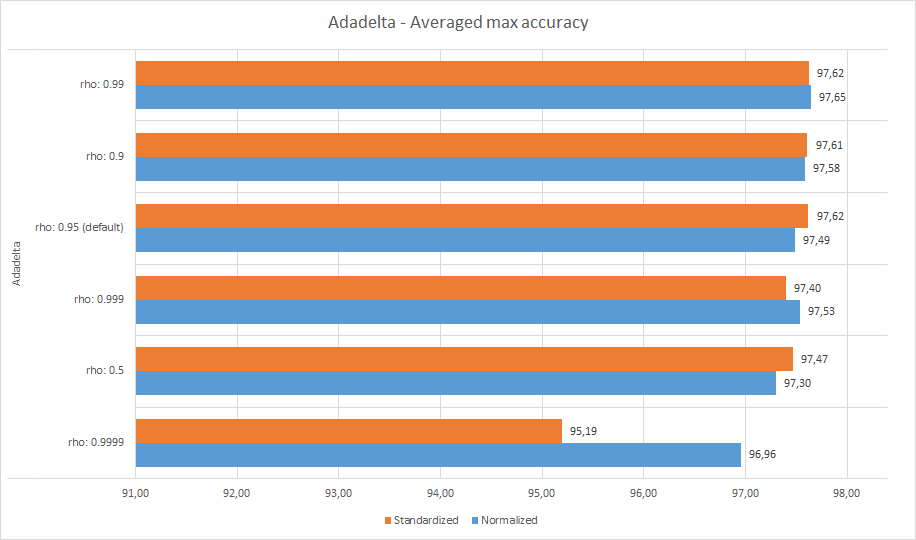
Ададелта
Очень похоже на RMSProp, значения RHO в диапазоне 0,9–0,99 являются хорошими:
Адам
Этот оптимизатор показал очень близкие результаты почти для всех конфигураций. Различия между их характеристиками становятся очевидными, когда мы устанавливаем шкалу x на очень короткий диапазон:

Примечательно, что конфигурация по умолчанию показала лучшие результаты, а оптимизатор лучше работает со стандартизованными данными. Кроме того, установка для AMSGrad значения true обычно улучшает результаты.
Adamax
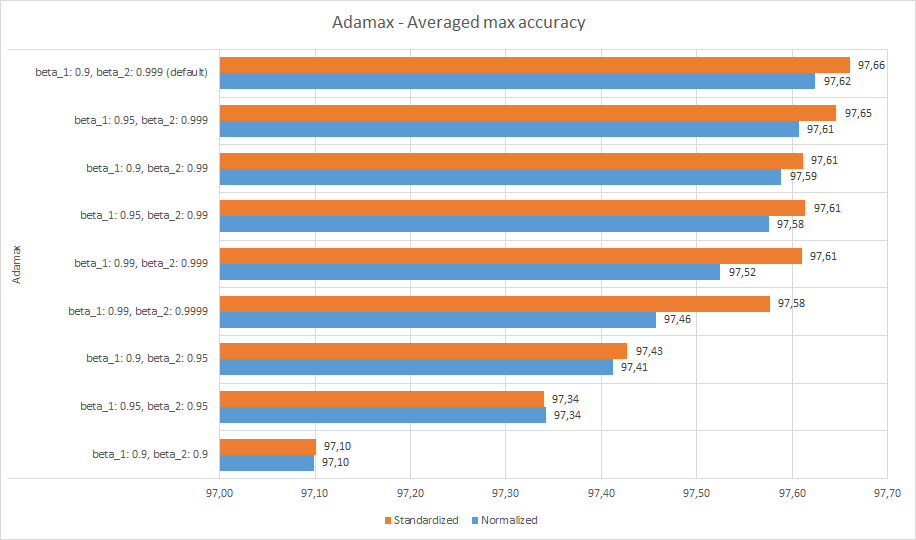
Здесь конфигурация по умолчанию снова была лучшей, и та же история со стандартизованными данными. Хороший выбор для beta_1 - 0,9–0,95, а для beta_2 - 0,999.
Надам
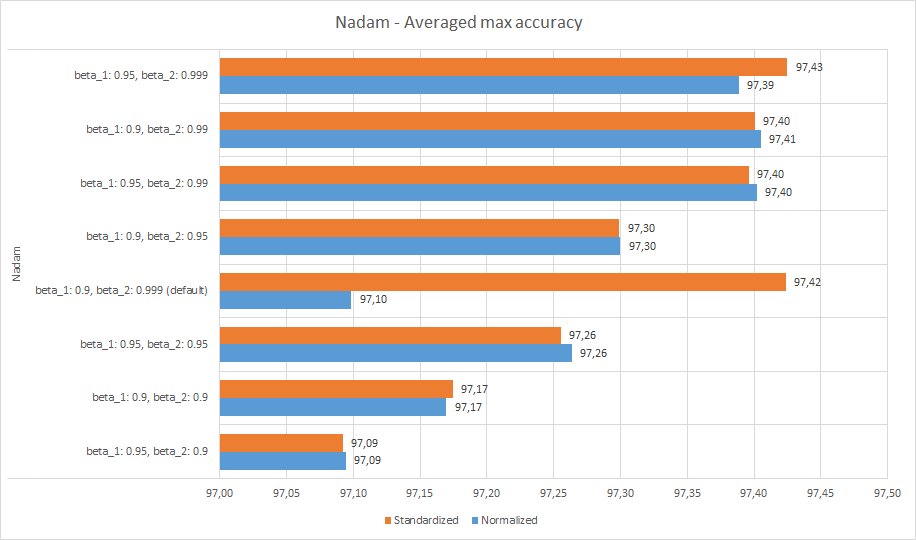
Здесь мы не видим, что стандартизированные данные предпочтительнее нормализованных, а пользовательские конфигурации работают лучше, чем стандартные. Оптимальные значения beta_1 такие же, как для Adamax, но для beta_2 значение 0,99 почти так же хорошо, как 0,999.
Какой оптимизатор лучший?
Словом, однозначного ответа на этот вопрос нет. Наш эксперимент показал, что это зависит от того, как вы настраиваете параметры оптимизатора, и от того, как вы настраиваете свою нейронную сеть. В нашем случае оптимизаторы Adam и Adamax с конфигурациями по умолчанию были лучше других, но это может быть не так в других задачах и с другими данными. Как всегда, вы должны проверить несколько вариантов и поиграть с параметрами оптимизаторов, чтобы увидеть, какие из них лучше подходят для вашего случая.
Также стоит отметить, что при выборе оптимизатора важно учитывать его стабильность. Блокнот на моем github визуализирует процесс обучения каждой конфигурации, и из него вы можете увидеть, например, что SGD, несмотря на немного меньшую точность, приводит к более стабильным результатам, чем другие оптимизаторы. Я нашел очень хорошее обсуждение этого вопроса:
«Https://www.quora.com/Why-do-the-state-of-the-art-deep-learning-models-like-ResNet-and-DenseNet-use-SGD-with-momentum-over-Adam -для тренировки"
Вероятно, если бы мы дали SGD немного больше времени на обучение и немного больше настроили нашу сеть, в конечном итоге она достигла бы гораздо более высоких значений точности.
Пришло время завершить обсуждение оптимизаторов и перейти к следующей части, где мы поговорим о гиперпараметре скорости обучения и о том, как его изменение может повысить точность модели. Увидимся в следующей части!
Я всегда рад знакомиться с новыми людьми и делиться идеями, поэтому, если вам понравилась статья, предложите добавить меня в LinkedIn.
Глубокое исследование серии не очень глубоких нейронных сетей:
- Часть 1. Что в наших данных
- Часть 2: Функции активации
- Часть 3а: Обзор оптимизаторов
- Часть 3б: Выбор оптимизатора
- Часть 4: Как найти правильную скорость обучения
- Часть 5: Пропадание и шум
- Часть 6: Инициализация весов
- Часть 7: Регуляризация
- Часть 8: Пакетная нормализация
- Часть 9: Размер имеет значение
- Часть 10: Объединение всего вместе