Разве вы не ненавидите, когда какой-то неоплачиваемый стажер «случайно» удаляет все метаданные Reddit? В частности, данные, которые говорят вам, к какому субреддиту принадлежит сообщение? К счастью, цель проекта на этой неделе состояла в том, чтобы попытаться определить, какой субреддит был создан с использованием обработки естественного языка, так что, возможно, мы сможем исправить часть ущерба!
Для своего выбора сабреддитов для работы я выбрал два, которые бросили бы мне вызов и совпадали с моими интересами: Metal и Metalcore! Поскольку они так похожи, я думаю, что метод моделирования, который может надежно отличить их друг от друга, был бы подходящим методом для использования и для других субреддитов. В конце концов, мне удалось создать модель с предсказательной точностью ~ 90%, и я понял, что для различения жанров люди используют не характеристики музыки, а группы.
Сбор и очистка данных:
Для сбора данных я использовал API Reddit с помощью «запросов» и цикла for. Я собрал извлеченные данные, которые включали заголовки сообщений и собственный текст, в список для каждого субреддита и сохранил их как CSV для будущего использования:
Поскольку я напрямую нацелился на два источника текста, которые мне нужны в моем цикле for, данные не потребовали особой очистки; Мне нужно было только удалить пустые записи из сообщений, у которых был заголовок, но не было собственного текста (например, изображения и ссылки). Чтобы создать окончательный моделируемый набор данных, я сгенерировал pandas DataFrame из объединенных данных и добавил новый столбец для классификации субреддитов, который включал двоичный 0 для Metal и 1 для Metalcore.
Беглый взгляд на данные показал, что два субреддита не так уж сильно отличаются, как я ожидал. У них обоих были сообщения о песнях, группах и новостях, все в разной степени актуальности и бессмысленности. Некоторые примеры вашей средней горячей темы:

НЛП векторизация и моделирование:
Чтобы разбить гигантские списки текстов в удобную для использования форму, я использовал два разных векторизатора: Count Vectorizer и TFIDF Vectorizer. Стоп-слова, которые я использовал, были стандартным набором английских стоп-слов из базы данных SK Learn. Кроме того, в качестве моделей я использовал логистическую регрессию (наказание L2) и MultinomialNB. Фух! Теперь, когда технические детали уложены, давайте посмотрим на некоторые результаты:

В целом комбинация CountVectorizer / Logistic Regression была наиболее точной, хотя каждая комбинация давала довольно похожие результаты. Однако, поскольку он был наиболее точным, я использовал CV / LR, чтобы посмотреть на последствия модели.
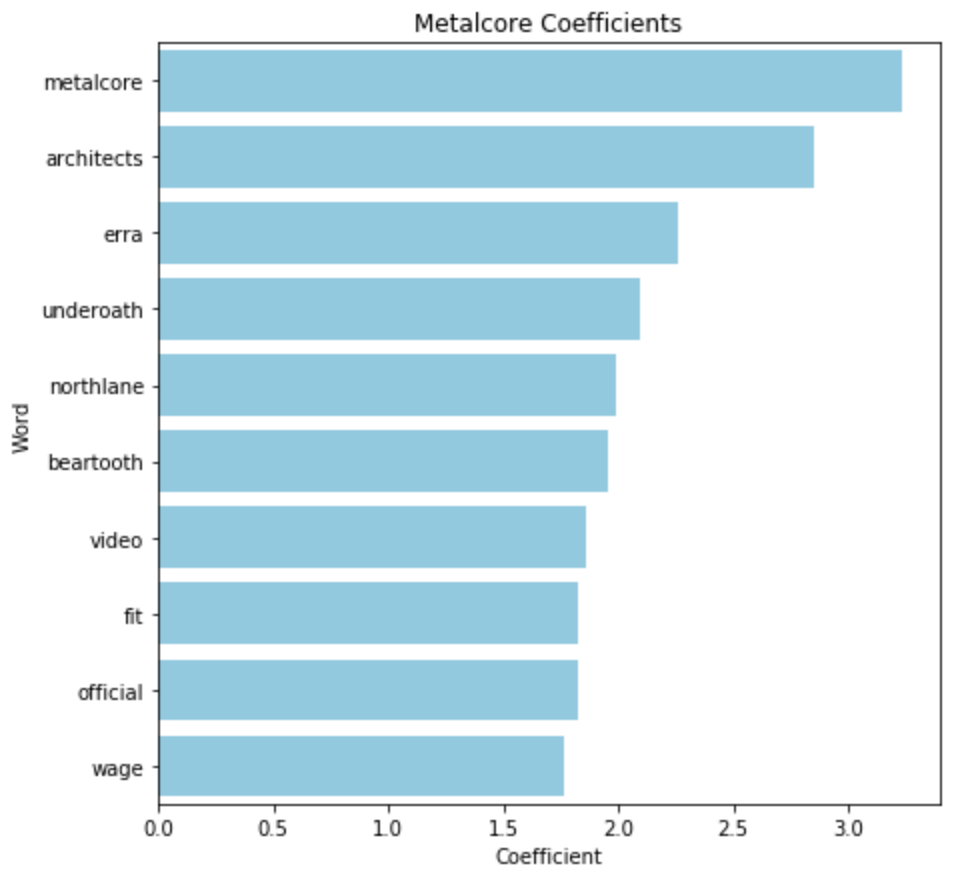
Неудивительно, что наиболее надежным предиктором публикации в сабреддите Metalcore является слово «metalcore». Столь же неудивительно, что семь из следующих девяти предикторов являются частями или целыми названиями групп (два выброса - «видео» и «официальный»). Чего я не ожидал, так это отсутствия слов, описывающих саму музыку. Фактически, из 50 ведущих предсказателей Metalcore только 25 было связано со структурой песни («разбивка»).
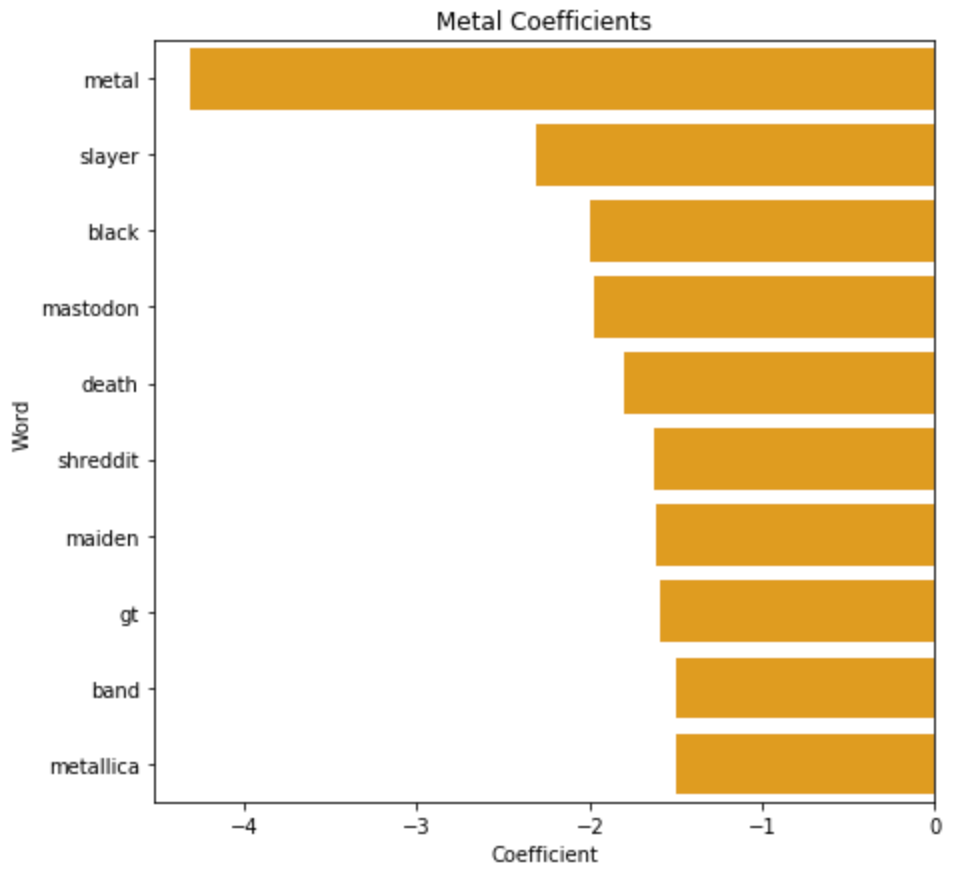
Чтобы не отставать, «металл» - еще более сильный предсказатель для металла! Как и в списке Metalcore, в Metal тоже есть несколько групп: mastodon, slayer, maiden и Metallica. Также в список попали поджанры «черный» и «смерть», «шреддит» (прозвище металлического субреддита) и «группа», что говорит само за себя. Единственное слово, которое меня не устраивает, - это «gt», но после небольшого исследования я догадываюсь, что это часть названия усилителя (имеет смысл!)
Последние мысли:
В целом производительность модели получилась неплохой. Однако он больше опирался на известные жанровые группы, песни и альбомы, а не на музыкальные аспекты («Эта песня - металкор, потому что это Beartooth» против «Эта песня Beartooth - металкор из-за x, y и z»). Сделав шаг назад, этот результат имеет смысл, если учесть, откуда берутся данные; эти субреддиты не предназначены для обсуждения тонкостей теории музыки металла!
Двигаясь вперед, я бы определенно попытался улучшить этот проект путем поиска по сетке оптимальных параметров модели. Кроме того, я бы хотел попробовать разные субреддиты. В идеале, два даже более тесно связанных жанра (я думаю, хардкор против пост-хардкора) или два субреддита с большим упором на обсуждение (возможно, AskHistorians против AskAnthropology).