Как и в других социальных сетях, спортсмены Strava по-разному взаимодействуют друг с другом. Они могут следовать друг за другом, просматривать действия друг друга и отмечать достижения с похвалой. Возможно, самое богатое взаимодействие происходит, когда спортсмены сочетают социализацию со спортом, участвуя вместе в реальных мероприятиях и кратко прослеживая смежные пути в пространстве и времени. В отличие от кудо, это взаимодействие не является чем-то, что мы собираем явным образом. Мы должны делать выводы об этих событиях, тщательно обрабатывая необработанные пространственно-временные данные и точно определяя, когда и где спортсмены из нашего глобального набора данных проводили время вместе.
Есть три основных способа вывода данных о групповой активности в наш продукт:
- Сгруппированные действия в ленте: в вашей ленте Strava действия пользователей, за которыми вы следите, отображаются вместе в одном наборе действий, если они были сопоставлены вместе в группе.
- Сгруппированные действия с одним действием: для каждого действия на своей странице сведений Strava покажет список всех действий, сгруппированных с этим действием. Эта функция работает только для неприкосновенных действий, и ее можно отключить для каждой активности или ограничить, чтобы только ваши подписчики могли видеть, когда вы совпадаете с другими действиями.
- Flyby: для каждого действия Strava будет определять все другие действия, которые пересекались (пролетели!) С вами (в дополнение к полностью согласованным действиям). Вы можете просмотреть список этих подходящих занятий и воспроизвести свои собственные занятия вместе с другими. Эта функция работает только для неперсонализированных действий и может быть полностью отключена через настройки конфиденциальности.

Наше определение групповой деятельности происходит из этого социального происхождения: для того, чтобы занятия выполнялись в группе, два спортсмена должны были находиться близко друг к другу на расстоянии в течение значительной части времени, затраченного на занятия. Обычно мы используем порог в 30%. Это уравновешивает компромисс между ложными срабатываниями (действия других людей, которые случайно были рядом с вами какое-то время) и ложными отрицаниями (фактические групповые действия, которые могут не совпадать из-за долгого пути к месту встречи или непреднамеренное разделение во время групповой части).
Чтобы узнать больше, посетите страницу поддержки Strava, посвященную групповой деятельности:
Работа над этой проблемой была одной из моих любимых технических задач в Strava. Во время пиковой нагрузки на Strava загружается более 100 операций в секунду. Средняя активность Strava пересекается с более чем 40 другими видами деятельности Strava. В пиковые события, такие как Ride London или NYC Marathon, мы увидим более 10 000 мероприятий, каждое из которых пересекается с большинством всех остальных 10 000 мероприятий.
Это сообщение в блоге призвано дать представление о проблемах реализации этих функций, показать, как развивались подходы по мере продолжения масштабирования, и объяснить, как наша последняя система может непрерывно и без усилий открывать этот удивительный график данных.
Хронология группировки действий
В 2010 году была выпущена реализация v1 группировки действий. Он определял схожесть действий полностью с использованием времени начала / окончания совпадения сегментов. Напоминаем, что сегмент - это участок дороги или тропы, на котором спортсмены Strava могут сравнить время. Чтобы считаться сгруппированными вместе, пара действий должна завершиться одними и теми же сегментами в совпадающее время. Сходство двух действий основывалось на том, какой процент совпадений сегментов произошел одновременно. Очевидным ограничением этой системы было то, что для ее работы требовалось согласование сегментов.
В 2013 году я представил v2 группировки действий, которая больше не зависит от совпадений сегментов. Этот алгоритм был представлен вскоре после того, как мы построили новый пространственно-временной индекс данных об активности, который изначально предназначался для решения другой проблемы (определения того, какие действия будут соответствовать вновь созданному сегменту). Для каждого действия алгоритм v2 собирал набор подходящих кандидатов, используя запрос по этому индексу. Подходящие кандидаты - это любые действия, которые в какой-то момент пересекаются с основным действием (пересекаются в любой отдельной пространственно-временной плитке). Эти наборы кандидатов на совпадение затем сохранялись и отображались в функции Strava Labs Flyby, которая также была выпущена в то же время.
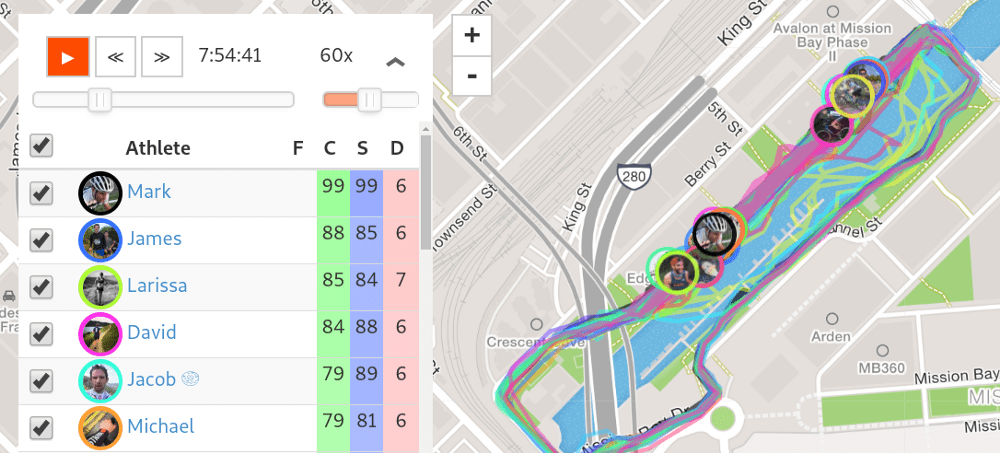
Чтобы вычислить схожесть действия запроса и кандидата на совпадение, мы загружаем полные необработанные данные (широта, долгота, время) обоих действий (в Strava мы называем эти данные потоками). Затем мы повторяем во времени основное действие, одновременно измеряя расстояние от основного действия до места действия кандидата. Окончательная оценка сходства - это процент времени, в течение которого действие кандидата находилось на определенном расстоянии от основного действия. Для группового занятия кандидат должен находиться рядом с вами более 30% времени.
Подводя итоги по времени, мы могли бы правильно представить, что социальный характер деятельности часто не предполагает переезда. Например, посещение кафе или пекарни может быть всей социальной частью поездки. Если вы выполняете запись во время остановки, алгоритм группировки v2 это заметит, тогда как v1 будет учитывать только усилия, которые вы приложили к сегментам. Эта версия группировки также позволяла правильно группировать стационарные действия и действия в области без каких-либо сегментов.
С 2016 года наихудший случай для группировки v2 начал вызывать реальные проблемы: в очень больших групповых действиях, таких как Ride London, мы могли бы увидеть 10000 действий, все пересекающие одну пространственно-временную плитку, генерируя до 100000000 пар подходящих кандидатов для обработки. В этих случаях нам обычно приходилось откладывать вычисление групповых действий, потому что задержка группировки увеличивалась более чем в 10 раз и вызывала нагрузку на другие внутренние службы, от которых зависела группировка, такие как наша служба хранения потоков.

К концу 2017 года этот наихудший сценарий стал повседневным явлением с появлением виртуальной велосипедной платформы Zwift. Пользователи Zwift ездят на стационарных велотренажерах в любой точке мира, но генерируют синтетические данные GPS в одной области, которая была выбрана Zwift в качестве фиктивного местоположения виртуального велосипедного маршрута. Действия Zwift обрабатываются Strava так же, как и любые другие действия, поэтому функции, основанные на местоположении, будут использовать эти синтетические данные. Эти виртуальные курсы могут иметь тысячи одновременных пользователей и всегда активны, что может сравниться только с самыми крупными реальными событиями. По сути, для команды инфраструктуры каждый день превратился в поездку по Лондону.
К январю 2018 года деятельность Zwift составляла небольшую часть всей деятельности Strava, но на нее приходилось 90% ресурсов, потраченных на обработку групповых матчей. Вскоре после этого мы были вынуждены отключить группировку действий для виртуальных действий.
К августу 2018 года была развернута совершенно новая версия группировки действий v3. Новая версия в конечном итоге приводит к 50-кратному сокращению ресурсов ЦП, необходимых для выполнения группировки операций. С помощью группировки действий v3 мы снова сможем обрабатывать все действия Zwift и сможем масштабировать группировку в обозримом будущем.
В этой последней версии группировки действий используется MinHashing. Вместо того, чтобы рассчитывать попарное сходство действий, точно используя полные пространственно-временные данные потока, мы вычисляем подпись MinHash для каждого действия. Эти сигнатуры примерно описывают в фиксированном количестве байтов пространственно-временной характер действия. Учитывая сигнатуры любых двух действий, мы можем оценить их сходство за очень небольшое количество циклов ЦП. Остальная часть этого сообщения в блоге представляет собой подробное объяснение техники MinHashing и обзор того, как Strava теперь использует ее для решения важной проблемы группировки действий.
Что такое Минхешинг?
MinHashing - эффективный метод оценки схожести пары наборов. Набор часто является представлением некоторого нижележащего объекта. В часто используемом примере объекты - это документы, а набор, определяющий каждый документ, - это набор слов в каждом документе. Понятие подобия - это подобие Жаккара - количество общих элементов в наборах, деленное на общее количество различных элементов: | A∩B | / | A∪B |.
MinHash набора X при некоторой хэш-функции H определяется как наименьшее значение H при применении к элементам этого набора - min (H (X)). Цель этого можно лучше понять, если вы подумаете о H как о представлении случайной перестановки (или строгого упорядочения - мы предполагаем, что в H нет столкновений) всех возможных элементов, которые могут появиться в наборах. MinHash просто выбирает крайний левый элемент в X в соответствии с этим порядком: x = argmin (H (X)) - это минимальный член X в соответствии с H, а H (x) = min (H (X)) - это « Значение MinHash »X с учетом H.
Давайте сначала рассмотрим MinHash A∪B, объединение A и B, где A и B - любые непустые множества. Пусть z = argmin (H (A∪B)). Теперь посмотрим, находится ли z также в A∩B. В обоих случаях мы будем использовать общее и очевидное утверждение о множествах, чтобы доказать что-то о MinHash A и B: argmin набора равен argmin подмножества этого набора тогда и только тогда, когда подмножество содержит argmin оригинального набора. Применяя это утверждение к двум случаям:
- Если z также является членом A∩B: в этом случае z находится в A и в B, поэтому он должен быть argmin и для этих множеств, таким образом, z = argmin (H (A)) = argmin (H (B) ).
- Если z не является членом A∩B: WLOG, предположим, что z находится в A, но не в B. Тогда z = argmin (H (A)), но z! = Argmin (H (B)), таким образом, argmin (H (А))! = Argmin (H (B)).
Итак, мы использовали хеш-функцию для выбора произвольного элемента A∪B. Мы показали, что этот элемент также находится в A∩B тогда и только тогда, когда MinHash A и MinHash B равны. Таким образом, шанс того, что MinHash A равен MinHash B, в точности равен | A∩B | / | A∪B | - что является определением подобия Жаккара A и B.
Таким образом, мы можем сравнить значения MinHash двух наборов, чтобы получить хоть один бит информации об их сходстве. Это окажется полезным, потому что мы можем получить информацию о наших исходных произвольно больших наборах, используя только хеш-значения конечной длины.
Вместо одной хэш-функции обычно используют M попарно независимых хэш-функций H_1,…, H_M. Мы будем называть результирующие M хэш-значений сигнатурой MinHash набора - min (H_1 (X)),…, min (H_M (X)). Проверяя равенство каждого из M компонентов сигнатур MinHash двух наборов, мы получаем M (независимых) бит информации о сходстве двух наборов. Мы знаем, что ожидаемое значение одного бита равно подобию Жаккара двух наборов, поэтому, увеличивая M, мы можем уменьшить дисперсию нашей меры подобия по мере необходимости. Если N из M компонентов имеют равные хэш-значения, то N / M - наша наилучшая оценка подобия Жаккара.
Эта оценка подобия может быть вычислена за O (M) времени и памяти, где M может быть намного меньше, чем исходные размеры набора | A | или | B |. Прямой алгоритм получения подобия Жаккара для двух множеств - не менее O (| A | + | B |). Кроме того, вместо сложной функции подобия, которая, вероятно, требует построения хеш-таблицы для точного вычисления подобия множеств, с MinHash вам просто нужно проверить попарное равенство каждого элемента в двух массивах длины M. Это невероятно быстрая операция для компьютеров. - для 64-битных значений хэша и M = 100 на ядро ЦП возможно несколько миллионов проверок в секунду.
Я был вдохновлен взглянуть на MinHash из-за недавней статьи / алгоритма под названием SuperMinHash. SuperMinHash дает умное и асимптотическое улучшение скорости (теперь уже 20-летней!) Техники MinHashing, одновременно увеличивая ее точность. Полную версию статьи приятно читать, но эта техника примерно сокращает временную сложность для вычисления подписи MinHash из O (NM), где N - размер входных данных, установленный на O (N + M * log (M)). Это большое дело, потому что значения M обычно могут составлять 100–10 000. Это также дает уменьшение ожидаемой дисперсии оценки сходства по сравнению с наивным MinHash. Но помимо генерации подписей SuperMinHash и MinHash можно использовать и обсуждать точно так же.
Установить представление пространственно-временных потоков активности
В нашем приложении MinHash объект - это действие Strava - одиночный пробег или поездка, определяемые массивом измерений широты, долготы и времени с плавающей запятой на протяжении действия (потоков). Чтобы вызвать MinHashing для действий, нам нужно найти способ представить эти данные в виде набора дискретных элементов. Более того, чтобы быть подходящим для группирования действий, это представление должно также обладать тем свойством, что сходство таких наборов по Жаккару тесно коррелирует со сходством с нашим старым алгоритмом v2.
После многих экспериментов мы нашли схему, которая хорошо работала. Мы преобразуем поток в последовательность дискретных кубических плиток в трехмерном пространстве (широта, долгота, время). Последовательность плиток непрерывна - мы используем алгоритм Брезенхэма, чтобы обеспечить это. Каждая плитка - это элемент в наборе, используемый в качестве входных данных для MinHashing.
Затем мы повторяем это еще несколько раз, используя немного разные размеры плитки, а также вращение в подпространстве широты / долготы, чтобы избежать случаев плохих краев. Например, если дорога, идущая точно на север, оказалась точно на границе плитки, небольшая разница GPS между вами и вашим партнером по бегу может привести к нулевому перекрытию плитки. Множественные схемы мозаики помогают снизить влияние такого краевого случая. Это также помогает в крайнем случае очень небольших действий, которые в противном случае могли бы иметь небольшое количество тайлов относительно количества компонентов MinHash M. Последний набор - это просто набор отдельных тайлов из каждой из различных схем координат тайлов.
Наши плитки имеют размер примерно 80 метров на 80 метров на 120 секунд. Это примерно означает, что вы должны находиться в пределах 80 метров + 120 секунд от того, с кем вы бежите или едете, иначе вы рискуете, что ваши действия не совпадают.
Создание подписи довольно дешево из-за ускорения SuperMinHash и должно выполняться только один раз за действие. Мы можем использовать сигнатуру длиной M = 100 и 64-битный хэш для наших приложений. С этими параметрами полная подпись действия MinHash составляет 800 байт. Наше тестирование показало, что по сравнению с подобием v2, наш подход к v3 имел менее 10% ложных срабатываний и менее 10% ложных отрицательных результатов, но мы выбрали более строгие параметры, чтобы уменьшить количество ложных срабатываний за счет ложноотрицательных.
Индексирование
Другое приложение подписей MinHash позволяет эффективно извлекать все объекты, похожие на объект запроса, при условии, что мы уже вычислили и проиндексировали подписи для всех объектов. Чтобы две подписи MinHash имели ненулевое сходство, они должны иметь одинаковое значение по крайней мере в одном компоненте своих подписей MinHash. Мы используем этот факт в следующей структуре таблицы:
Таблица поиска: карта от activityId до MinHash Signature этого действия, где каждое значение хэш-функции представляет собой массив [бит]:
getSig(activityId: Long): Array[Array[Bit]]
Таблица индексов: сопоставление каждого значения компонента сигнатуры MinHash с набором идентификаторов действий, которые имеют сигнатуры с одинаковым значением для этого одного компонента:
getIds(hashValue: Array[Bit], componentIndex: Int): Set[Long]
Каждое действие появляется один раз в таблице поиска и один раз для каждого значения хеш-функции в его сигнатуре в таблице индекса (M раз). Мы можем запросить эти таблицы, чтобы вернуть набор всех действий, которые имеют ненулевое сходство с целевым действием:
def candidateQuery(activityId: Long): Set[Long] =
getSig(activityId)
.zipWithIndex
.flatMap{ case(hashValue, componentIndex) =>
getIds(hashValue, componentIndex)
}
Запрос получает подпись для входного действия, затем ищет действия-кандидаты в индексе для каждого компонента этой подписи и, наконец, собирает их объединение.
Запрашивать и хранить эту полную индексную таблицу дорого. Кроме того, похоже, что шаблон запроса-кандидата может быть дорогостоящим - особенно для действий в популярных областях, где размер набора в индексе может быть большим. Однако есть несколько оптимизаций, которые могут сделать этот поиск невероятно быстрым.
Оптимизация 1. Храните только часть индекса.
Если нас в конечном итоге интересуют только действия, которые очень похожи друг на друга, и мы не заботимся о том, чтобы упустить небольшой процент аналогичных действий, нам не нужно хранить весь индекс. Предположим, нас интересуют только пары действий с более чем 50% -ным сходством. С вероятностью не менее 1/2 пара таких действий будет иметь конфликт в любом отдельном компоненте сигнатуры. Вероятность того, что одна пара не будет иметь ни одного столкновения в первых K компонентах, составляет примерно (1/2) ^ K. Например, для K = 1 и порога подобия 50% у нас будет ложноотрицательный коэффициент 1/2. Для K = 20 у нас будет примерно 10 ^ -6 ложных отрицательных результатов.
Мы вычисляем и храним подписи MinHash длины M в таблице поиска, но сохраняем только K элементов подписей в таблице индексов. Мы выбираем M в соответствии с желаемой дисперсией в значениях попарного сходства, а затем выбираем K ‹= M в соответствии с желаемым порогом сходства и частотой ложных отрицательных результатов для поиска действий кандидата. Если M = 100, то K = 20 дает индекс 1/5 размера за счет ложноотрицательной ошибки 0,0001%.
Оптимизация 2: Расчет локального сходства данных
Чтобы вычислить сходство двух действий, мы могли бы наивно получить полные подписи (800 байт) из таблицы поиска, а затем вычислить их сходство на клиентской машине. С правильной базой данных мы можем вместо этого вычислить сходство на машине хранения базы данных и вернуть клиенту только оценку подобия (одно двойное значение), тем самым значительно уменьшив сетевой трафик между базой данных и клиентом. Это уменьшит сетевой ввод-вывод, необходимый для получения результата, с 2 * 800 байтов до 8 байтов.
Если база данных распределена, этот трюк все еще работает, пока наш запрос направлен на сходство одного основного действия с большим набором действий-кандидатов. В этом случае мы ищем подпись основного действия и транслируем ее всем узлам базы данных, где в таблице поиска есть записи для действий-кандидатов. Это экономия на передаче по сети примерно до тех пор, пока количество узлов базы данных меньше, чем количество возможных действий.
В производстве мы используем Cassandra и достигаем этого с помощью Cassandra UDFs. Это может выглядеть следующим образом, где функция similarityUDF принимает подпись и набор activityIds и возвращает сходство подписи с подписью каждого activityId , рассчитывая его удаленно.
def candidateSimilarities(activityId: Long): Map[Long, Double] = {
signature: Array[Array[Bit]] = getSig(activityId)
candidateIds: Set[Long] = candidateQuery(activityId)
similarityUDF(signature, candidateIds)
}
Оптимизация 3: Сокращение битов в поисковой таблице
Для ключей индексной таблицы мы хотим, чтобы наши хеш-значения были глобально устойчивы к конфликтам хеш-кодов (ложным срабатываниям). С миллиардом действий в таблице не более 100 миллиардов (2³⁶) отдельных ключей. Мы хотим, чтобы ожидаемое количество ложных срабатываний поиска в одном действии (keywordQuery) было не очень большим. Для этого нам просто нужно, чтобы количество значений хэш-функции было большим по сравнению с количеством элементов. 2³⁶ значений 64-битной хеш-функции более чем достаточно. Обратите внимание, что это более низкий стандарт, чем предотвращение любого одиночного столкновения в базе данных, для которого потребуется хэш-функция с вдвое большим количеством битов.
При использовании подписей MinHash только для определения сходства одной пары действий у нас гораздо меньше требований к ложным срабатываниям. Нам нужно только предотвратить слишком высокую оценку подобия для нашей выбранной пары. Если бы каждое из наших значений M MinHash было усечено до только B битов, мы ожидали бы увидеть, что компоненты M / (2 ^ B) дают ложные срабатывания из-за этого усечения. Использование только одного байта (B = 8) только добавляет ошибку к ожидаемому значению подобия в полпроцента.
С помощью этих оптимизаций мы приходим к следующей схеме: для оптимизации №1 в индексной таблице сохраните только первые K компонентов как полные 8-байтовые хеш-значения в качестве ключей. В основной таблице поиска также сохраните полные хеш-значения для первых K компонентов. Чтобы реализовать оптимизацию №3, в другой (сокращенной) таблице поиска сохраните M компонентов, уменьшенных до одного байта каждый. Наша реализация подобияUDF может использовать подписи в этой сокращенной таблице поиска.
Дополнительные приложения
Наборы групповых действий
Еще одно приложение для подписей активности MinHash обслуживает группы активности в лентах спортсменов. Лента - это набор недавних действий, принадлежащих спортсменам, за которыми следит владелец ленты. Группа действий в ленте - это подмножество действий в ленте, которые также сгруппированы вместе.
В предыдущей системе для каждого действия в фиде мы выбирали все действия, которым оно соответствовало. Этот запрос должен был смотреть на глобальный набор действий Strava, даже учитывая совпадения с действиями, которые не отслеживаются владельцем канала. Затем мы отфильтровали эти результаты и отфильтровали только другие действия, которые есть в ленте. Наконец, мы построили кластеры сгруппированных действий из этого набора совпадений.
Если у нас есть F действий в фиде, и каждое действие сопоставляется с набором M других действий, этот подход требует загрузки O (FM) записей. Невозможно иметь индекс, который снижает сложность этого запроса, по крайней мере, без денормализации совпадений действий в каждом фиде. Предположим, владелец корма следит за 200 спортсменами, которые участвовали в очень большой общественной деятельности, такой как Ride London. Ride London генерирует более 10 000 загрузок в Strava, каждая из которых обычно может быть сгруппирована с 1 000 другими действиями. В этом примере мы должны обработать 200 * 1000 строк базы данных, чтобы найти правильную групповую активность, установленную в ленте. Это явно не масштабируемая реализация, и на самом деле она была причиной сбоев на предыдущих сайтах. В качестве предохранительного клапана от этой проблемы мы ограничили количество возвращаемых строк соответствия активности, что привело к неправильной группировке в фиде.
С помощью подписей MinHash мы можем улучшить этот процесс: в частности, мы получаем подпись MinHash для каждого действия в ленте. Затем мы (наивно) оцениваем сходство всех пар действий и на основании этого строим связанные наборы действий. Для этого потребуется O (F²) сравнений, но в фиде никогда не бывает более 200 действий, а 200² сравнений могут быть выполнены менее чем за 10 мс. Немного более сложный подход требует проверки асимптотически меньшего количества пар, чем это. Преимущество этого метода заключается в том, что все поиски являются локальными для набора действий в ленте, в отличие от предыдущего метода, который требовал сначала искать глобальный набор совпадений для каждого действия.
Восстановление асимметрии
Одним из недостатков подобия Жаккара является его симметричность. В идеале подобие активности было бы асимметричным: мы хотим иметь возможность представить, что А ехал с В, но что В не ехал с А. B равно | A∩B | / | А |. Учитывая симметричное подобие Жаккара J = | A∩B | / | A∪B | и мощности исходного множества | A | и | B | мы можем вывести: | A∩B | / | A | = J * (| A | + | B |) / (| A | * (J + 1)). Это выражение полезно, пока | A | / | B | не очень мала, так как она становится меньше, дисперсия нашей оценки резко возрастает, и мы просто не должны рассматривать ее как совпадение. Это улучшение скромное, но реализуется дешево - нам нужно только сохранить мощность каждого набора MinHash в таблице поиска (вместе с подписью).
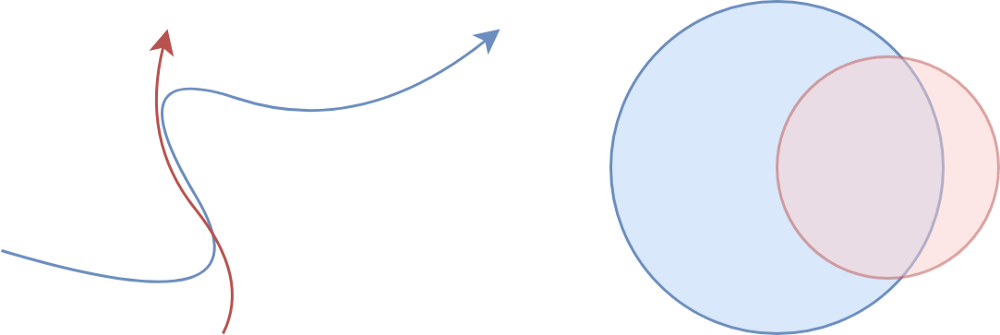
Многоцелевая группировка
Наша реализация позволяет легко хранить несколько схем хеширования с разными параметрами хеш-функции. Например, мы можем создать схему листов с тем же пространственным разрешением, но с гораздо меньшим временным разрешением листов - скажем, за один день. Понятие подобия в этой схеме будет более гибким со временем, но более строгим с пространством. Это может позволить автоматическое обнаружение всех гонок и массовых мероприятий, когда спортсмены едут по одной и той же трассе, но в разное время в течение дня.
Одно предостережение в этой схеме заключается в том, что повторение одной и той же координаты плитки не взвешивается должным образом, поскольку MinHash Similarity в конечном итоге работает с наборами и не может представлять элемент несколько раз. Например, критериумная велогонка, в которой один и тот же цикл проходит несколько раз, будет засчитана только один раз. Один из способов решить эту проблему - BagMinHash - еще один алгоритм от того же автора, что и SuperMinHash. Более простой способ решить эту проблему - просто подсчитывать каждое повторное посещение данной плитки как отдельную плитку.
Развивая эту технику еще дальше, мы можем полностью опустить временное измерение, просто учитывая пространственное сходство действий. Мы даже можем использовать эту метрику пространственного сходства и быстрый и распределенный алгоритм кластеризации для кластеризации глобальных наборов данных из сотен миллионов действий в общие кластеры маршрутов.
Заключение
Группировка действий - это огромная техническая задача, которую необходимо реализовать в масштабе и во время быстрого роста. Последовательные инновации с годами улучшили производительность и качество сопоставления. Эти инженерные усилия привели к созданию совершенно нового компонента социального графа спортсменов, который иначе был бы недоступен. Наконец, есть еще большой потенциал для будущих применений этих методов для новых приложений и открытий.