
Музыка играет неотъемлемую часть нашей жизни. Это общий язык, который помогает нам выразить себя, когда никакие слова не могут описать наши чувства. Музыка также помогает нам поднять настроение. Это влияет на нашу душу и наши эмоции, заставляя нас чувствовать себя счастливыми, грустными или полными энергии. Мы, вероятно, будем играть песни петь во время наших долгих поездок или слушать оптимистичную песню во время нашего занятия в тренажерном зале, или слушать расслабляющую ПЕСНИ при кодировании, поэтому вам не Разбейте
SCREEN.
У многих из нас есть особые вкусы к музыке, которую мы слушаем, и они могут время от времени меняться. Это заставило меня задуматься ...
- Изменились ли мои музыкальные предпочтения с годами? Если да, то когда произошли изменения?
- Исходя из моего недавнего вкуса в музыке, какой тип музыки я слушаю сейчас?
Благодаря Spotify API я могу извлекать и исследовать песни, которые мне нравится слушать - те, которые заставили меня щелкнуть значок сердца.
Настройка
Чтобы получить данные из Spotify API, нам нужно будет выполнить первоначальную настройку, выполнив следующие шаги:
- Войдите в Spotify для разработчиков и создайте приложение.
- На странице панели инструментов приложения выберите изменить настройки и установите URI перенаправления как http: // localhost: 8888.
- Обратите внимание на идентификатор клиента и секрет клиента.
Сбор данных
Мы можем использовать Spotipy, библиотеку Python для Spotify Web API, чтобы получить соответствующие данные. Чтобы получить песни, нам нужно сгенерировать токен авторизации.
import spotipy
import spotipy.util as util
from spotipy.oauth2 import SpotifyClientCredentials
cid = '<INSERT CLIENT ID>'
secret = '<INSERT CLIENT SECRET>'
username = ""
client_credentials_manager = SpotifyClientCredentials(client_id=cid, client_secret=secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
# Get read access to your library
scope = 'user-library-read'
token = util.prompt_for_user_token(username, scope)
if token:
sp = spotipy.Spotify(auth=token)
else:
print("Can't get token for", username)
Есть два API: current_user_saved_tracks и audio_features, позволяющие получить название, исполнителя, время добавления песни и такие функции, как акустичность, танцевальность и инструментальность. Эти функции помогут нам лучше понять наш плейлист.
Некоторые описания функций приведены в таблице ниже:

Чтобы просмотреть все функции песни, вы можете просмотреть эту ссылку.
df_saved_tracks = pd.DataFrame()
track_list = ''
added_ts_list = []
artist_list = []
title_list = []
more_songs = True
offset_index = 0
while more_songs:
songs = sp.current_user_saved_tracks(offset=offset_index)
for song in songs['items']:
#join track ids to a string for audio_features function
track_list += song['track']['id'] +','
#get the time when the song was added
added_ts_list.append(song['added_at'])
#get the title of the song
title_list.append(song['track']['name'])
#get all the artists in the song
artists = song['track']['artists']
artists_name = ''
for artist in artists:
artists_name += artist['name'] + ','
artist_list.append(artists_name[:-1])
#get the track features and append into a dataframe
track_features = sp.audio_features(track_list[:-1])
df_temp = pd.DataFrame(track_features)
df_saved_tracks = df_saved_tracks.append(df_temp)
track_list = ''
if songs['next'] == None:
# no more songs in playlist
more_songs = False
else:
# get the next n songs
offset_index += songs['limit']
#include timestamp added, title and artists of a song
df_saved_tracks['added_at'] = added_ts_list
df_saved_tracks['song_title'] = title_list
df_saved_tracks['artists'] = artist_list
Вот образец полученного набора данных.

Изменились ли мои музыкальные предпочтения?
После получения данных пора выяснить, как характеристики меняются с течением времени. Мы можем сгруппировать песни по добавленному году и месяцу, получить среднее значение для каждой функции с течением времени и визуализировать его.
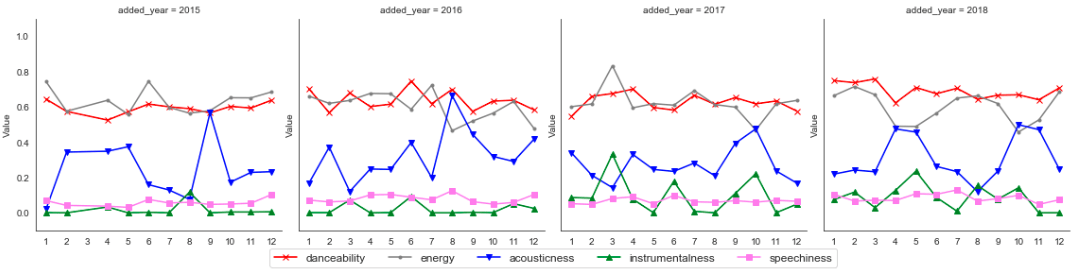
Линейный график был разделен по годам, чтобы сделать его более крупным. Речь (фиолетовым цветом) наиболее стабильна ближе к 0 по годам. Это означает, что я обычно слушаю песни, в которых меньше рэпа. Акустичность (отмечена синим) колеблется, что означает, что у меня есть смесь акустических и неакустических песен с течением времени.
Что меня больше всего интересует, так это инструментальность (выделена зеленым). В 2015 и 2016 годах он был стабильным, ближе к 0. Однако с 2017 года инструментальность начала колебаться. Вероятно, это показатель того, что мой музыкальный вкус изменился с 2017 года. Мы можем фильтровать наши данные по песням, которые были добавлены с 2017 года.
Какие типы песен я слушаю?
Кластеризация
Судя по диаграмме выше, я знаю, что слушаю больше инструментальных песен. Но разве это инструментальные танцевальные песни? Или более классические песни? А что насчет остальных? Каков мой нынешний музыкальный вкус? Мы могли бы сгруппировать песни со схожими характеристиками вместе и профилировать каждую группу. Один из методов кластеризации - это кластеризация по K-средним, которую я буду использовать для анализа своих песен.
Для кластеризации мы хотим, чтобы точки в одном кластере были как можно ближе. Мы также хотим, чтобы расстояние между кластерами было как можно дальше друг от друга. Благодаря этому каждый кластер выглядит компактным, будучи удаленным друг от друга.
Вот визуализация того, как выглядит кластеризация для 4 кластеров. Зеленая точка представляет собой центроид каждого кластера (центр кластера).

Поскольку кластеризация зависит от расстояния, масштаб наших данных повлияет на результаты. Например, если мы хотим сгруппировать по высоте от 1,5 до 1,9 м и по весу от 60 до 80 кг. Таким образом, точки разбросаны по оси высоты на 0,4, а вес - на 20. Это означает, что вес будет доминирующим при определении кластеров.
Мы можем стандартизировать диапазон данных, чтобы функции повлияли на результат.
cluster_features = ['acousticness', 'danceability', 'instrumentalness', 'energy', 'speechiness'] df_cluster = df_recent[cluster_features] X = np.array(df_cluster) scaler = StandardScaler() scaler.fit(X) X = scaler.transform(X)
Получив представление о том, что делает кластеризация, сколько типов / групп песен мы слушаем? Один из способов - сделать обоснованное предположение на основе собственных знаний. Если вы слушаете все виды музыки, от edm до хип-хопа, джаза и многих других, вы можете указать большее число, например… 7, может быть? Поскольку для кластеризации K-средних требуется указать количество кластеров, которое мы хотим, мы можем установить k = 7, где k - количество кластеров.
Другой способ - использовать метод локтя для определения количества кластеров. В методе локтя мы можем выполнить кластеризацию для диапазона заданных номеров кластеров, например k = 1, k = 2,…, k = 9, k = 10. Для каждого k мы возьмем каждую точку, измерим ее квадрат расстояния до центра тяжести кластера и просуммируем их. Это называется суммой квадратов расстояний (SSD). SSD измеряет, насколько близко каждая точка находится к центроиду кластера. Следовательно, чем меньше размер SSD, тем ближе точки в одном кластере.
ss_dist = []
K = range(1, 11)
for k in K:
km = KMeans(n_clusters=k, init='k-means++', random_state=123)
km = km.fit(X)
ss_dist.append(km.inertia_)
plt.plot(K, ss_dist, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum of squared distances')
plt.title('Elbow Method For Optimal k')
plt.show()
Итак, если мы построим SSD для каждого k, мы получим изогнутую линию, как показано ниже:
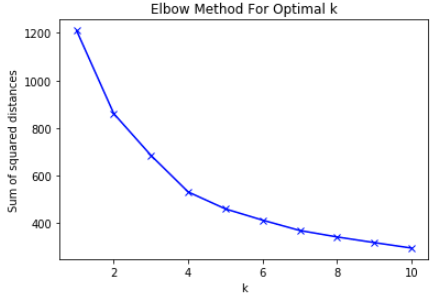
Из приведенного выше графика видно, что с увеличением k SSD уменьшается. Это имеет смысл, потому что для точек может быть назначен более близкий кластер, что приводит к более низкому SSD.
Ранее я упоминал, что мы хотим, чтобы точки в каждом кластере были как можно ближе. Однако мы не можем выбрать k = 10, потому что это наименьшее значение. Представьте себе это. Если мы выберем k = N, где N - количество песен, у нас будет каждая песня как отдельный кластер, и поэтому SSD будет равен 0. Это потому, что центроид кластера каждой точки является самой точкой.
Вместо этого мы собираемся выбрать k так, чтобы, если мы добавим еще один кластер, SSD немного уменьшился. Это известно как метод локтя. Если мы будем думать о кривой как о нашей руке, мы получим крутой уклон в начале, который внезапно становится пологим на полпути. Это придает ему форму «локтя».
На основе метода изгиба рекомендуется количество кластеров 4, потому что линия стала пологой от k = 4 до k = 5. Однако я также поигрался с k = 5 и обнаружил, что мне нравятся данные кластеры. Поэтому в этом посте я поделюсь результатами, которые я получил для k = 5.
Кластерная визуализация
Отлично, у нас наконец-то есть кластер! Так как же выглядит наш кластер? К сожалению, пока мы не можем его просмотреть. Это потому, что наши кластеры сформированы с использованием 5 функций. Если вы думаете о каждой функции как о измерении, вы получите 5-D. Поскольку мы можем просматривать изображения вплоть до 3-D, нам нужно будет применить технику, называемую уменьшение размеров. Это позволяет нам уменьшать размеры от 5-D до любых меньших размеров.
Чтобы попытаться объяснить это как можно более интуитивно, сокращение размерности направлено на создание низкоразмерного набора функций из более высокого измерения при сохранении как можно большего количества информации. Если вы хотите лучше понять, что он делает, вы можете посмотреть это видео об анализе главных компонентов (PCA), который является одним из методов уменьшения размерности.
Давайте посмотрим, сколько данных сохраняется, если мы используем PCA для уменьшения размера.

Синяя полоса показывает, сколько информации каждый главный компонент (ПК) вносит в данные. Первый компьютер передает 40% информации о данных. Второй и третий вносят по 20% каждый. Красная линия показывает совокупную информацию о данных ПК. При уменьшении с 5 измерений до 2 сохраняется 60% информации данных. Точно так же, если бы мы сократили до 3-х измерений, 80% информации данных сохраняется.
Теперь давайте посмотрим, как наши кластеры выглядят на двухмерном и трехмерном графике рассеяния.
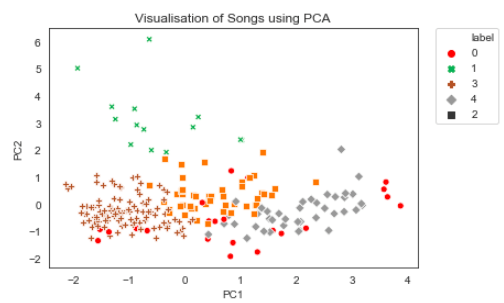

Точки на двумерном графике рассеяния перекрываются друг с другом и могут не выглядеть так, как будто кластеризация была проведена правильно. Однако, если мы посмотрим на это с трехмерной точки зрения, мы сможем лучше увидеть кластеры.
Давайте попробуем другой метод, называемый t-распределенным стохастическим соседним встраиванием (t-SNE). t-SNE хорошо работает для визуализации данных большой размерности. Подробнее читайте в этом уроке.

В этом случае двухмерный график рассеяния t-SNE может хорошо визуализировать 5 кластеров. Мы также можем приблизительно сказать, что кластер 3 - это самый большой кластер, а кластер 0 или 1 - самый маленький. Давайте посмотрим, как распределены кластеры, с помощью гистограммы.

Кластерное профилирование
Теперь мы можем понять, каковы характеристики различных кластеров. Давайте сравним распределение функций по кластерам.
# set binning intervals of 0.1
bins = np.linspace(0,1,10)
# create subplots for number of clusters(Rows) and features(Cols)
num_features = len(cluster_features)
f, axes = plt.subplots(num_clusters, num_features,
figsize=(20, 10), sharex='col'
row = 0
for cluster in np.sort(df_recent['cluster'].unique()):
df_cluster = df_recent[df_recent['cluster'] == cluster]
col = 0
for feature in cluster_features:
rec_grp = df_recent.groupby(pd.cut(df_recent[feature], bins)).size().reset_index(name='count')
cluster_grp = df_cluster.groupby(pd.cut(df_cluster[feature], bins)).size().reset_index(name='count')
sns.barplot(data=rec_grp, x=feature, y='count',
color='grey', ax=axes[row, col])
sns.barplot(data=cluster_grp, x=feature, y='count',
color='red', ax=axes[row, col])
axes[row, col].set_xlabel('')
axes[row, col].set_xticklabels(range(1,10))
if col > 0:
axes[row, col].set_ylabel('')
if row == 0:
axes[row, col].set_title(feature)
col += 1
row += 1
f.suptitle('Profile for each clusters')
plt.show()

Каждая строка представляет кластер, от 0 до 4, а каждый столбец представляет функцию. Серая полоса представляет собой распределение функции. Это позволяет нам получить приблизительное представление о распределении функции. Красная полоса представляет собой распределение объекта в этом кластере, которое используется для сравнения с другими кластерами.
Когда мы смотрим на распределение каждого кластера, мы видим, что каждый кластер имеет высокие или низкие показатели по определенным характеристикам. Это определяется тем, находится ли красная полоса справа (вверху) или слева (внизу) по отношению к серой полосе. По этим характеристикам мы можем профилировать их и даже придумать идентичность кластера.
Кластер 0 (Инструментальный): Высокая инструментальность. Низкая речь.
Кластер 1 (Лирический): Высокая танцевальность, энергия, речь. Низкая акустика, инструментальность.
Группа 2 (холодные вибрации): Высокая танцевальность. Низкая энергия, инструментальность, речь.
Группа 3 (Танцы): Высокая танцевальность, энергия. Низкая акустичность, инструментальность, речь.
Кластер 4 (Уменьшение): Высокая акустика. Низкая танцевальность, стремительность, энергичность, речь.
Мы также можем профилировать, взяв среднее значение кластерного объекта и нанеся его на радарную диаграмму. Это может быть проще для быстрого просмотра различий между всеми кластерами.
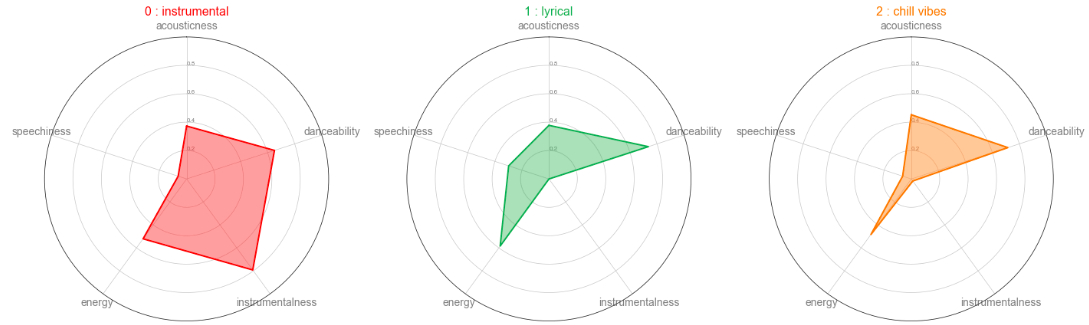
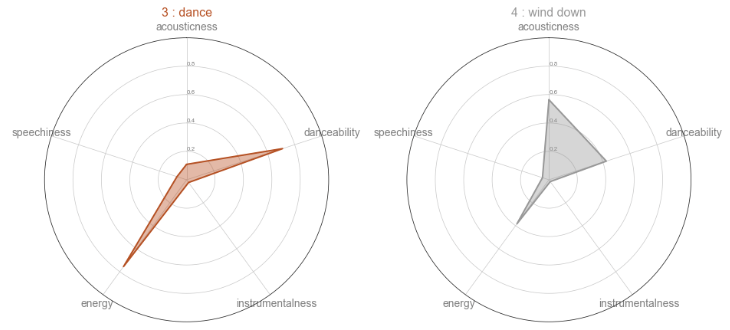
Показания радиолокационной карты аналогичны профилю, приведенному выше. Мы также можем видеть, что кластеры 2 и 4 имеют схожую статистику. Разница в том, что кластер 2 больше ориентирован на танцевальность, а кластер 4 больше на акустику.
Образец кластера
Посмотрим, соответствуют ли песни в каждом кластере профилю кластера. Вот по 3 песни в каждом кластере, и вы можете послушать их и посмотреть, имеет ли это смысл:
Группа 0 (инструментальная):
"Вернуться домой", автор - FKJ.
Загипнотизированный Coldplay.
"Либертанго", автор - Астор Пьяццолла, Бонд
Группа 1 (текст):
"Сентябрьская роза", автор - Кейлин Руссо,
Candlelight, автор: Жавия Уорд.
BBIBBI, автор - АйЮ.
Cluster 2 (Chill vibes):
Drop the Game от Flume, Chet Faker
Livid от ELIZA
Find a Way от Matt Quentin, Rinca Yang
Cluster 3 (Dance):
Ultralife от Oh Wonder
Little Man от Pb Underground
Finesse (Remix) [feat. Карди Б] Бруно Марс, Карди Б
Кластер 4 (Сдвиг):
"Холодное сердце", Сабрина Клаудио.
"Преодоление дистанции 2.0", Эштон Эдминстер.
"Кто-то, чтобы остаться", Ванкуверская клиника сна
Заключение
Сначала мы изучили различные функции с течением времени и попытались выяснить, изменились ли музыкальные вкусы. На основе отфильтрованного набора данных мы провели кластерный анализ. Затем мы визуализировали, чтобы получить приблизительное представление о том, как это выглядит, и убедиться, что с кластеризацией все в порядке. Наконец, мы построили график распределения каждой функции и профилировали их. В конце концов, мы можем лучше понять, какие песни нам нравятся.
Сбор данных можно найти здесь, а анализ - здесь на моем Github.
Спасибо за чтение и надеюсь, что вы нашли это интересным. Пожалуйста, не стесняйтесь оставлять свои отзывы в разделе комментариев ниже или свяжитесь со мной в моем LinkedIn. Надеюсь, у вас впереди отличная неделя!
использованная литература
- Построение диаграмм аспектов:
https://seaborn.pydata.org/examples/many_facets.html - Пошаговое руководство по анализу основных компонентов (PCA):
https://www.youtube.com/watch?v=FgakZw6K1QQ - Учебник по t-SNE:
https://www.datacamp.com/community/tutorials/introduction-t-sne - Построение радарных / паучьих диаграмм:
https://python-graph-gallery.com/392-use-faceting-for-radar-chart/