Извлечение данных Apache NiFi и преобразование в JSON
Apache NiFi - это высоконадежная и мощная система с открытым исходным кодом для обработки, преобразования и распространения данных. Он предоставляет веб-интерфейс для непрерывного проектирования, контроля и мониторинга данных.
В этой истории мы увидим, как мы можем подключиться, извлечь запись таблицы MySQL DB и преобразовать ее в JSON.
Предварительное условие:
MySQL
Apache NiFi: скачать по данной ссылке
https://nifi.apache.org/download.html
После установки Apace NiFi вы можете открыть веб-интерфейс в своем браузере, используя связанный порт во время установки, например:
http://localhost:9090/nifi/
Теперь мы готовы приступить к выполнению упражнения. Убедитесь, что сервер БД MySQL работает.
- Добавить процессор для получения записи таблицы
а. QueryDatabaseTable: широко используется для извлечения инкрементных данных на основе инкрементного столбца из таблицы. вывод записывается в формате AVRO
б. ExecuteSQL: выполнить SQL и вернуть полученные данные в формате AVRO.
c. GenerateTableFetch: может использоваться для извлечения «страниц» строки из таблицы, что полезно при управлении большим набором данных в управляемых фрагментах.
d. QueryDatabaseTableRecord: выполнить SQL и получить все строки, значения которых больше указанного максимального столбца, который последний раз просматривался, результат запроса будет преобразован в формат, указанный средством записи.
мы будем использовать пример QueryDatabaseTable для этого упражнения:
Перетащите процессор в веб-интерфейс и выберите QueryDatabaseTable.
перейдите к настройке процессора, вкладки свойств и службы пула соединений базы данных свойств, добавьте DBCPConnectionPool и щелкните стрелку GoTo, чтобы настроить его:

щелкните значок настройки конфигурации NiFi Flow и добавьте URL-адрес подключения к БД, драйвер, путь к расположению драйвера, пользователя БД и пароль, как показано ниже.

нажмите OK и убедитесь, что добавлены тип БД, имя таблицы и имя инкрементного столбца (ID здесь на скриншоте ниже).
В моем примере ID - столбец в таблице employee.

2. Добавить процессор SplitAvro: поскольку результатом шага 1 является файл Avro, этот процессор может разбивать несколько наборов записей на отдельные записи на основе настроенных свойств.

3. Добавьте процессор ConverAvroToJSON.
Это преобразует двоичный файл Avro в формат JSON, который будет очень использоваться для управления и мониторинга потока данных.

4. Добавьте обработчик MergeContent, чтобы сгруппировать запись JSON обратно в файлы.
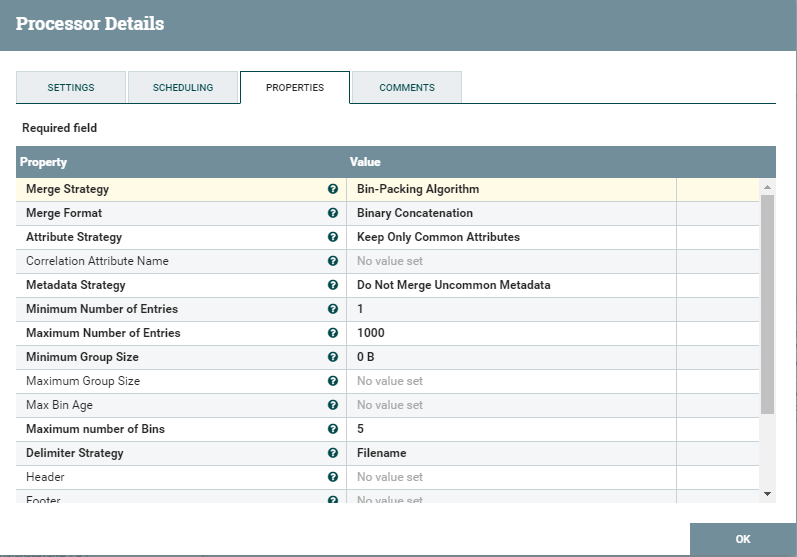
5. Добавьте обработчик PutFile, чтобы сохранить файл JSON для дальнейшей обработки.
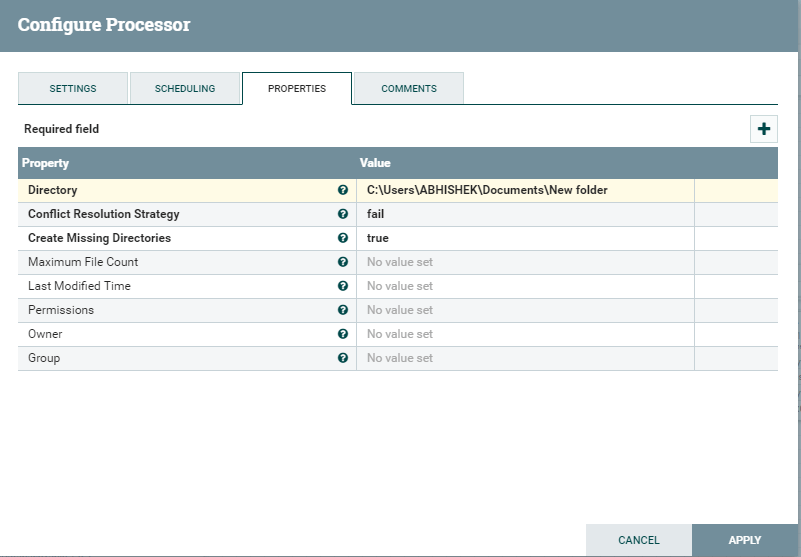
После этого вы можете определить свой поток и успех, условия отказа и запустить процессоры.
см. полный дизайн данного упражнения:

Таблица сотрудников в MySQL mytestdb

Просмотр выходного файла JSON (4-я запись, записанная в файлы, когда данные были вставлены в таблицу.
{“ID”: 4, “first_name”: “Nilesh”, “middle_name”: null, “last_name”: “singh”, “manager_id”: “3”, “department”: “PSS”, “date_of_joining”: null}