Обычно в контролируемом обучении матрица путаницы представляет собой матрицу (таблицу), которую можно использовать для измерения производительности при классификации машинного обучения.
Это своего рода матрица (таблица), которая помогает вам обобщить, описать или оценить производительность модели классификации на наборе тестовых данных, для которых известны истинные значения.
Каждый столбец матрицы путаницы представляет экземпляры реального класса, а каждая строка представляет экземпляры предсказанного класса. , но может быть и наоборот, т. е. столбец для предсказанных классов и строка для реальных классов.
Матрица путаницы визуализирует точность классификатора путем сравнения фактических и предсказанных классов.
В случае 2-х классов, то есть «отрицательного» и «положительного», матрица путаницы может выглядеть так:

2 строки и 2 столбца состоят из,
Истинные плюсы, правда минусы
Ложные срабатывания, ложноотрицательные результаты
- TP (истинно положительный): истинно положительный: предсказанные значения правильно предсказаны как фактические положительные
- FP (ложноположительный): предсказанные значения неверно предсказали фактическое положительное значение. т. е. отрицательные значения прогнозируются как положительные
- FN (ложноотрицательный результат): ложноотрицательный результат: положительные значения прогнозируются как отрицательные
- TN (истинно отрицательный): истинно отрицательный: предсказанные значения правильно предсказаны как фактические отрицательные
Давайте разберемся на примере предсказания текста (на изображении есть текст или нет):
· Истинные положительные результаты (TP): мы прогнозируем положительный результат (изображение, содержащее текст) и фактически получаем изображение, содержащее текст.
· Истинные негативы (TN): мы прогнозируем негатив (изображение, не содержащее текста) и фактическое отсутствие текста на изображении.
· Ложные срабатывания (FP): мы прогнозируем положительный результат (изображение, содержащее текст), а в действительном тексте нет. (Также известна как «ошибка типа I».)
· Ложноотрицательные результаты (FN): мы прогнозируем негатив (изображение, не содержащее текста) и фактически имеем текст на изображении. (Также известна как «ошибка типа II».)
Теперь давайте возьмем числовой пример классификации животных.
Предположим, что у нас есть выборка из 20 животных, т.е. 10 собак и 10 кошек. Матрица путаницы нашего алгоритма распознавания может выглядеть как следующая таблица:
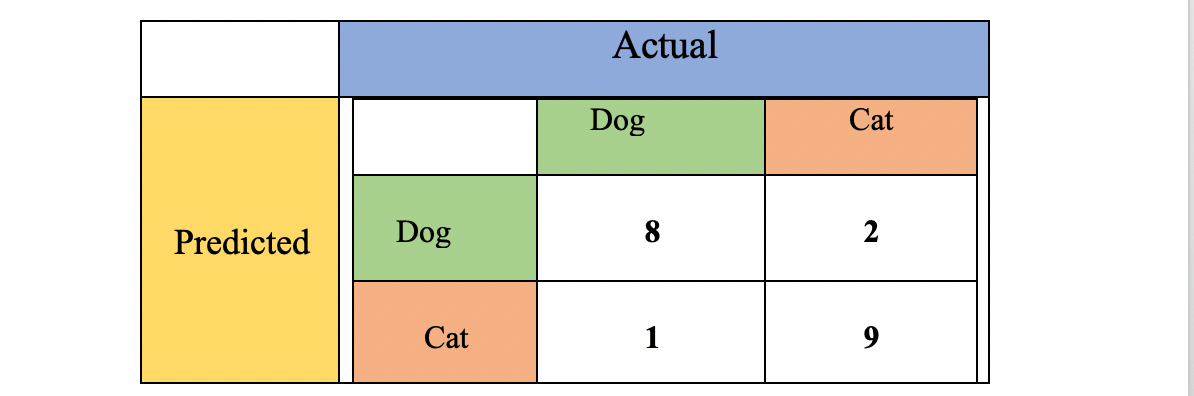
В приведенной выше матрице путаницы наша система правильно предсказала восемь из 10 реальных собак, но в двух случаях она приняла собаку за кошку. Десять реальных кошек были правильно распознаны в девяти случаях, но в одном случае кошка была принята за собаку.
Теперь разберемся со списком показателей (точность, истинно положительный показатель, ложноположительный показатель, точность и отзыв), которые рассчитываются из матрицы путаницы для двоичного классификатора.
Точность: точность означает, как часто классификатор оказывается правильным.

Истинная положительная оценка (собака): когда это на самом деле да, как часто это предсказывает да?

Истинно отрицательный показатель (собака): · Когда на самом деле нет, как часто он предсказывает нет?

Точность:
Метрика точности показывает точность положительного класса. Он измеряет, насколько вероятно предсказание положительного класса правильно (означает, когда он предсказывает «да», как часто это правильно).

Напомнить:
Отзыв — это доля случаев, когда алгоритм правильно предсказал, из всех помеченных случаев.
Показатель отзыва. Отзыв также называется чувствительностью или процентом истинных положительных результатов.

Примечание.
Высокая полнота, низкая точность. Указывает, что большинство положительных примеров распознаются правильно (низкий FN), но есть много ложных срабатываний.
Низкий отзыв, высокая точность. Указывает на то, что мы упускаем много положительных примеров (высокий FN), но те, которые мы прогнозируем как положительные, действительно положительные (низкий FP).
Оценка F1:
F1 Score — это средневзвешенное значение Precision и Recall. Таким образом, эта оценка учитывает как ложноположительные, так и ложноотрицательные результаты. Интуитивно это не так просто понять, как точность, но F1 обычно более полезен, чем точность, особенно если у вас неравномерное распределение классов. Точность работает лучше всего, если ложные срабатывания и ложные отрицания имеют одинаковую стоимость. Если стоимость ложных срабатываний и ложных отрицаний сильно различается, лучше смотреть как на Precision, так и на Recall.
Оценка F1 = 2*(напоминание * точность) / (напоминание + точность)
Если вам понравилось читать этот пост, пожалуйста, поделитесь им и дайте несколько аплодисментов, чтобы другие могли его найти 👏👏👏👏👏 !!!!
Вы можете следить за мной на Medium, чтобы получать свежие статьи. Кроме того, свяжитесь со мной в LinkedIn.
Если у вас есть какие-либо комментарии, вопросы или рекомендации, не стесняйтесь публиковать их в разделе комментариев ниже!