Ресурс для тех, кто хочет извлекать данные с веб-страницы

В сегодняшнем технологическом климате данные очень важны. Данные собираются для изучения тенденций и анализа информации, сбор которой в противном случае занял бы гораздо больше времени.
Однако сбор этих данных - непростая задача. Часто данные не передаются вам, и вам нужно выйти и собрать эти данные.
К счастью, у нас есть Beautiful Soup, библиотека на языке программирования Python, которая позволяет нам очищать веб-страницы в поисках данных. С этими данными мы можем затем поместить в удобные для просмотра столбцы и продолжить оценку тенденций.
Многие проекты, над которыми я работал лично, требовали от меня использования библиотеки Beautiful Soup, и я стремлюсь создать полезный ресурс для тех, кто хочет сделать то же самое.
Начиная
Во-первых, нам нужно импортировать библиотеки в нашу записную книжку. Это позволит нам получать данные с веб-страницы.
Первый импорт, который мы собираемся добавить, - это панды, и мы будем импортировать его как pd.
Второй импорт, который мы будем использовать, это Запросы, которые мы можем импортировать как req. Запросы используются для получения данных HTML с внешнего URL-адреса.
В моем случае я также импортировал библиотеку времени, которую использовал для паузы на одну секунду перед повторным сканированием. Обычно это используется, когда вам нужно открыть несколько страниц.
Причина, по которой нам может потребоваться это сделать, заключается в том, что слишком быстрое сканирование может привести к тому, что вас пометят как хакера. Хакеры стремятся завалить сервер системы запросами, что в конечном итоге приведет к поломке сервера.
Рекомендуется также проверять страницу условий использования веб-сайта. Это связано с тем, что на странице условий и положений может быть информация о том, что вам разрешено очищать.
Теперь, когда у нас есть импорт и мы проверили, можем ли мы очистить желаемую веб-страницу, мы можем проверить код состояния.
Первым делом нужно передать желаемый URL в библиотеку запросов, чтобы получить контент. Это позволяет нам определить, позволяет ли веб-страница очистить нужную веб-страницу. В качестве примера я буду использовать справочный сайт по баскетболу.

Код, который мы ищем, - 200. Код 200 означает, что очистить желаемую веб-страницу можно. Код состояния аналогичен ошибке 404, которую вы получаете при вводе несуществующего URL-адреса в адресную строку, что означает страница не найдена.
Обычно ошибки, начинающиеся с 4, означают, что ошибка была на вашей стороне. Ошибки, начинающиеся с 5, обычно означают, что на серверах произошла ошибка, и вы ничего не можете сделать.
Теперь, когда у нас есть 200 код состояния и разрешение на парсинг, мы можем перетащить содержимое запроса в Beautiful Soup с помощью библиотеки синтаксического анализа ‘lxml’.

Теперь нам нужно перейти на нашу веб-страницу, щелкнуть правой кнопкой мыши в любом месте страницы и выбрать проверить.

Таким образом, будет возвращено содержимое HTML на странице.

Выше мы видим, что, поскольку у нас выделена таблица тегов HTML, она выделяет всю таблицу на веб-странице. Это идеально, потому что это данные, которые мы хотим очистить.
Чтобы очистить контент, который нам нужен, нам нужно найти что-то уникальное, чтобы идентифицировать конкретную таблицу. Для этого мы используем table = soup.find, чтобы найти определенные теги HTML.
Метод словаря находит определенные HTML-теги в ‘table’, который мы ищем. Как вы можете видеть ниже, я использовал идентификатор расширенной статистики, как она отображается на веб-странице.

Далее мы создаем пустой список. Пустой список выйдет из цикла for, который будет перебирать все содержимое HTML.
Внутри цикла for мы создаем словарь и заполняем словарь всей информацией из цикла for и используем метод append, чтобы добавить его в список.

Когда мы смотрим на таблицу, нам нужно определить, какие атрибуты мы хотим в каждом столбце. Опять же, нам нужно найти конкретную информацию в теге HTML, чтобы вернуть содержимое столбца.
Мы также можем индексировать определенные элементы, чтобы лучше идентифицировать содержимое, которое мы хотим извлечь.
Еще одна полезная техника - это техника .all. Метод .Find_all дает вам список всех ячеек в строке. Мы можем использовать это, чтобы определить точный HTML-тег, который мы ищем.

Весь код, возвращающий каждый столбец, заключен в try, за исключением указания Python продолжать работу, если мы не очистили какие-либо данные.
Как я упоминал выше, я использовал sleep 1, сообщая Python спать на одну секунду после каждой очистки.
Затем я добавляю список в словарь и использую имя фрейм данных. Для проверки работоспособности я также прошу первые пять строк данных, чтобы убедиться, что все данные в порядке.
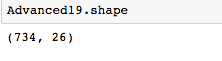
Мы также можем посмотреть на фигуру, чтобы увидеть, сколько столбцов и строк находится в нашем новом фрейме данных.

На этом этапе мы затем используем .to_csv panda, чтобы преобразовать фрейм данных в CSV.
Надеюсь, эта статья оказалась находчивой для тех, кто хочет извлечь данные с веб-страницы. Я решил написать эту статью, потому что Beautiful Soup был огромной частью моей вершины.
Я считаю, что это очень ценный навык, который можно использовать для возврата CSV-файла, в котором вы можете изучить свои данные дальше.