
Мы все хотим создавать вещи, вводить новшества, возиться, экспериментировать, не так ли? Разработчики обычно сталкиваются с трудностями при получении данных для своих личных проектов. Было несколько раз, когда я хотел создать несколько проектов не для коммерциализации, а просто для того, чтобы добавить их в свой арсенал или просто повеселиться, и я уверен, что многие люди будут относиться к этому, но мне не хватало данных, потому что какое приложение или веб-сайт без данных? Либо приложение собирает данные от пользователя и показывает вам тщательно подобранную версию, либо у него есть данные, которыми вы можете воспользоваться. В конечном итоге все сводится к тому, есть ли в вашем приложении данные или нет.
Рассмотрим этот пример: что, если бы Facebook просто разрешил вам загружать свои фотографии, статус и все остальное, но не будет отображать данные других пользователей. В этом сценарии Facebook (технический гигант) превратится в паршивый Facebook (просто говорю), потому что в этом сценарии кто бы это использовал? Я бы выбрал первый переулок домой, если бы эта гипотеза была реальностью.
Итак, мы знаем, что данные важны для заинтересованности пользователей. Но здесь возникает вопрос: как нам получить данные? Что ж, есть разные способы получить нужные данные, например, если вы создаете веб-сайт, на котором перечислены рестораны, вы можете создать команду людей и обследовать конкретную область, получить необходимую информацию, а затем вставить эти данные в базу данных и использовать ее в соответствии с вашими потребностями, но это просто абсурд, потому что доступны различные сервисы, которые предоставят вам данные о ресторане, включая географические данные, охватывающие весь земной шар в форме API, или вы можете просто купить их данные. Если вы не знаете об API, здесь есть отличное видео, объясняющее это. Есть и другие способы, но это выходит за рамки данной статьи.
Есть вероятность, что API или данные, которые вас интересуют, очень дороги или у вас может не быть ресурсов для создания команды для сбора информации. И действительно, если мы просто хотим создать прототип, тогда эти API или данные станут бесполезными, поскольку в долгосрочной перспективе у нашего продукта может не быть активной аудитории. А иногда может случиться так, что нужные данные размещены на веб-сайте, но нет API или способа их купить.
Последний случай, который я объяснил, можно обработать с помощью очистки веб-страниц. Если некоторые данные присутствуют на веб-сайте, есть вероятность, что мы получим эти данные с помощью веб-скрапинга. Теперь, прежде чем вы вскочите со стула, думая, что можете запросить все данные мира, позвольте мне объяснить несколько вещей.
- При парсинге веб-страниц вы запрашиваете веб-страницу с сервера, как и любой другой пользователь веб-сайта.
- Получив веб-страницу, вы извлекаете доступные данные с веб-страницы.
- После извлечения данных вы можете обработать их, сохранив в базе данных или любом переносимом файловом формате.
- Получив данные, вы можете использовать их в своих личных проектах.
Теперь, пожалуйста, обратите внимание, что если вы запрашиваете веб-страницу как автоматический пользователь или боты, если хотите. Затем вы потребляете ресурсы сервера, на что вы можете быть авторизованы или нет. Кроме того, если количество веб-страниц, запрошенных вашим ботом, или количество раз, когда вы обращаетесь к серверу для запроса своей веб-страницы, неоправданно велико, вы можете исчерпать сервер, что сделает его неспособным обработать запрос подлинных пользователей веб-сайта. По сути, это будет DDoS-атака (распределенный отказ в обслуживании) на веб-сервер, хотя может и не распространяться, но ее можно рассматривать как атаку.
Поэтому, прежде чем вы попытаетесь что-либо объяснить, позвольте мне заверить вас, что я не несу ответственности за ваши действия. Вот несколько полезных советов по парсингу:
- Прежде чем вы решите очистить какой-либо веб-сайт, попробуйте внимательно прочитать файл robots.txt. В этом файле перечислены ресурсы / каталоги, которые ботам / паукам разрешено сканировать, с именем ботов, обычно определяемым как User-Agent и User-Agent: * означает все боты. Разрешить означает разрешенные каталоги, а Запретить означает ограниченные каталоги. Этот файл обычно находится в корне веб-сайта, например, файл robots.txt на носителе можно найти здесь https://medium.com/robots.txt. Каждый крупный веб-сайт поддерживает свой файл robots.txt.
- Вы также можете связаться с веб-сайтами, чтобы получить разрешение на удаление их данных. И это правильный способ парсинга веб-страниц.
- Наконец, будьте вежливы, не пытайтесь перегружать сервер своими запросами.
Теперь, сказав это, давайте посмотрим, как это делается. Парсинг веб-страниц - это искусство, которое требует тщательного анализа веб-сайта, например того, как разбивка на страницы представлена на веб-сайте, как данные хранятся на веб-странице, путем создания настраиваемых xpaths для эффективного извлечения данных.
XPath (XML Path Language) - это язык запросов для выбора узлов из XML документа. Кроме того, XPath может использоваться для вычисления значений (например, строк, чисел или логических значений) из содержимого XML-документа. XPath был определен Консорциумом всемирной паутины (W3C).
Xpaths также можно использовать для выбора узлов на HTML-страницах. Мы будем использовать их для получения данных от узлов. Вы можете следовать краткому руководству this, чтобы разобраться в нем, и его довольно легко понять.
Прежде чем мы углубимся в сферу программирования😂, давайте сначала настроим среду для нашего бота. Вы можете использовать PyCharm, чтобы упростить задачу, или Python IDLE будет работать нормально.
- Для PyCharm создайте новый проект и установите виртуальную среду или воспользуйтесь системным интерпретатором.
- После этого добавьте в проект пакет selenium.
- Загрузите chromedriver с здесь.
- Разместите хромированную отвертку где-нибудь в каталоге проекта.
- Если вы используете python IDLE, используйте pip для установки пакета selenium.
- Введите команду pip install selenium
- Последние 2 пункта совпадают с использованием хромированной отвертки.
Поскольку наша среда настроена, теперь приступим к кодированию😁. Мы собираемся написать скрипт, который перейдет на трендовую страницу github и получит имя репо, количество звездочек, количество вилок, булит, и мы экспортируем его в CSV. Наша программная структура будет примерно такой:
- SelExtract (класс)
- __init __ (конструктор)
- extract_trends (метод-член)
- process_xpath (метод-член)
- create_csv (метод-член)
Прежде чем переходить к коду, вам необходимо проанализировать страницу, которую мы хотим извлечь. Мы должны проверить, какие данные нам нужны и где они находятся на веб-странице.
Страница, которую мы собираемся извлечь, называется https://github.com/trending, на этой странице мы должны проанализировать ее структуру, чтобы создать xpaths, которые мы будем использовать для получения данных.

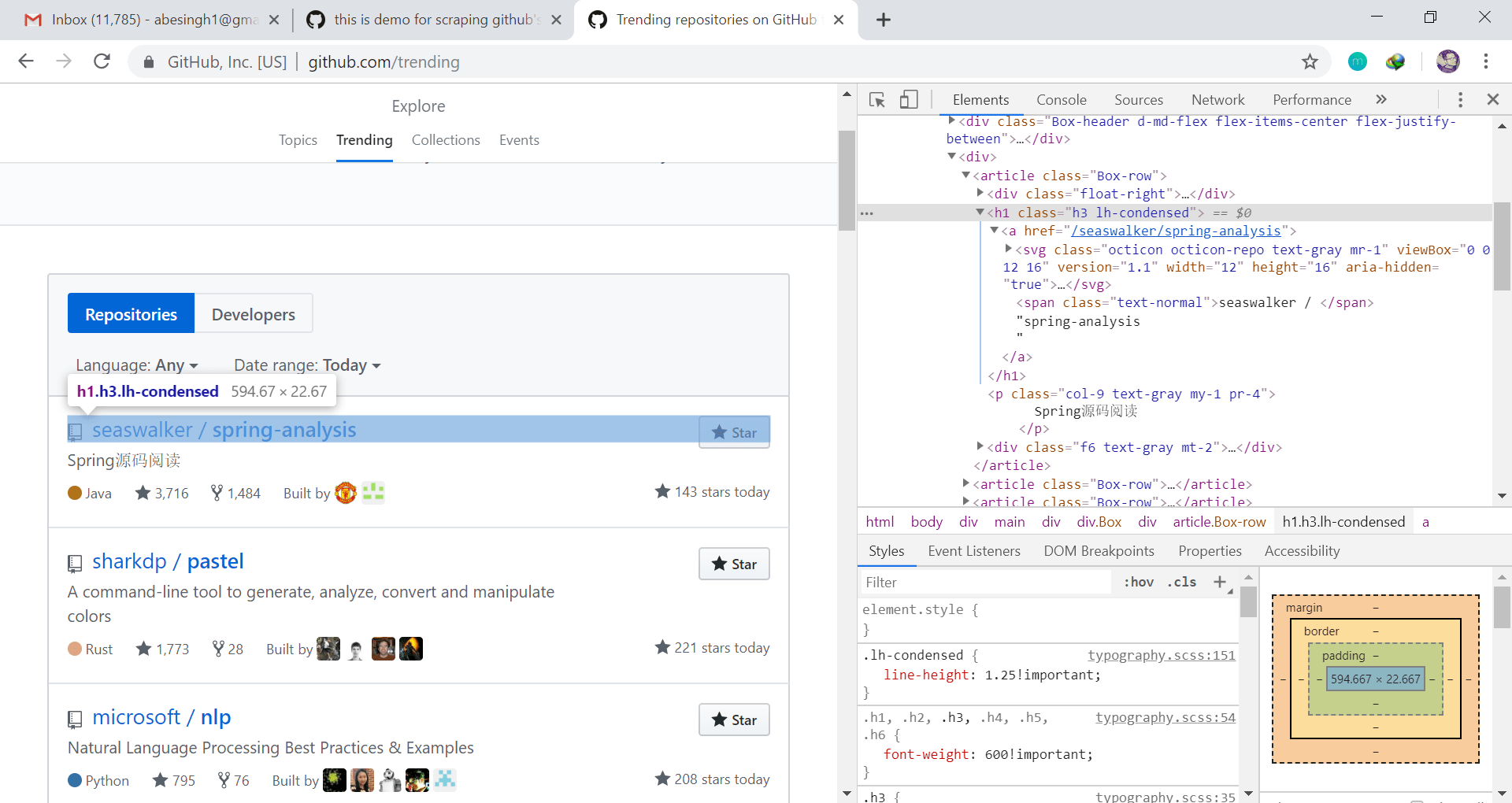
Вы можете использовать хромированный отладчик, чтобы увидеть структуру страницы. На изображении видно, что информация о каждом репо находится внутри элемента article с class = ”Box-row”, поэтому мы должны пройти каждую article элемент. Для названия репо есть тег h1 с class = ”h3 lh-condensed” внутри тега article и внутри h1 есть тег , значение узла которого имеет имя репо, поэтому xpath будет примерно таким:
// article [@ class = ”Box-row”] / h1 [ @ class = ”h3 lh-condensed”] / a

Здесь // article [@ class = ”Box-row”] / используется для обхода каждой статьи с классом «Box-row» внутри его xpath расширяется до h1 [@ class = ”h3 lh-condensed”], который используется для обхода h1 с классом ”h3 lh-condensed” внутри тега article, затем он расширяется до a, который будет проходить через все теги a внутри тега h3 внутри article с учетом классов.
Вот как вы создаете xpath для выборки данных, но это только часть, потому что они чрезвычайно гибкие. Вы начнете понимать его ценность, как только познакомитесь с кодом парсинга.
Кто-нибудь сказал код? Тогда приступим.
Сначала вам нужно импортировать webdriver из пакета selenium для выполнения всей тяжелой работы, а затем пакет csv для создания ... ну, вы знаете, CSV-файла.
Внутри нашего класса 3 метода и один конструктор.
Поговорим о конструкторе:
- Наш конструктор используется для создания объекта selenium webdriver и установки его параметров.
- Он также определяет URL-адрес веб-страницы, которую мы хотим извлечь, и многое другое.
def __init__(self):
# getting chrome driver option object to modify preferences
self.chromeOptions = webdriver.ChromeOptions()
# setting preferences of chrome driver such that
# images are not loaded (this approach is faster)
self.prefs = {'profile.managed_default_content_settings.images': 2}
# setting preferences
self.chromeOptions.add_experimental_option("prefs", self.prefs)
# assigning selenium webdriver object to self.driver
self.driver = webdriver.Chrome(executable_path="chromedriver.exe",
chrome_options=self.chromeOptions)
self.url = "https://github.com/trending"
# initially final data is set to None
self.sending_data = None
Существует 3 метода: extract_trends, process_xpath, create_csv . Начнем с метода process_xpath (), который используется для обработки xpath и выборки данных.
def process_xpath(self, x_path, d_type, n_type):
"""This function takes xpath and returns the fetched data"""
data = []
# get elements using xpath provided
con_ele = self.driver.find_elements_by_xpath(x_path)
""" this if elif block is used for checking which
function to execute to get data for example if
we want to get node value we will .text()
and if want to get attribute of element we use .get_attribute"""
if n_type == 1:
for i_ele in con_ele:
data.append(i_ele.text)
elif n_type == 0:
for i_ele in con_ele:
data.append(i_ele.get_attribute(d_type))
# return data if exists
if data:
return data
else:
return False
- Он принимает 3 аргумента:
- x_path (принимает xpath как строку)
- d_type (d_type определяет, какой атрибут хочет получить пользователь)
- n_type (это параметр флага, который используется для проверки если пользователю нужно значение узла или атрибут из выбранных элементов) - Используя все параметры, данные выбираются и отправляются вызывающей стороне функции, которая в данном случае является методом extract_trends ().
Теперь метод create_csv () не принимает аргументов, он просто обрабатывает обновленные извлеченные данные и записывает их в файл CSV.
def create_csv(self):
"""This function takes data and produces CSV file"""
# if data exists
if self.sending_data:
# path with file name, in this case CSV will
# be created in the folder from
# where script is executing
data_tbl_name = "git_trends.csv"
# opens file in writing mode
myfile = open(data_tbl_name, 'w',
encoding='utf-8', newline='')
# creating writer object with specifying
# delimiter as ';' for our csv
writer = csv.writer(myfile, delimiter=';')
# traversing through data
with myfile:
for i in range(len(self.sending_data[0])):
data_l = []
for q in range(len(self.sending_data)):
data_l.append(str(self.sending_data[q][i]))
# pushing data into CSV
writer.writerows([data_l])
- Он определяет xpath.
def extract_trends(self):
"""This function extracts data
from github trending page"""
# chromedriver opens github's trending page
self.driver.get(self.url)
# xpath for fetching name of repos
x_path_name = '//article[@class="Box-row"]' \
'/h1[@class="h3 lh-condensed"]/a'
# xpath for fetching number of stars
x_path_stars = '//article[@class="Box-row"]' \
'/div[@class="f6 text-gray mt-2"]/a[1]'
# xpath for fetching number of forks
x_path_forkers = '//article[@class="Box-row"]' \
'/div[@class="f6 text-gray mt-2"]/a[2]'
# fetching name data using our
# utility function 'process_xpath'
name_data = self.process_xpath(x_path_name, '', 1)
name_data.insert(0, 'Repo Names') # inserting heading in list
# fetching stars data using our
# utility function 'process_xpath'
stars_data = self.process_xpath(x_path_stars, '', 1)
stars_data.insert(0, 'No of Stars') # inserting heading in list
# fetching fork data using our
# utility function 'process_xpath'
fork_data = self.process_xpath(x_path_forkers, '', 1)
fork_data.insert(0, 'No of forks') # inserting heading in list
user_data = ['Built By'] # inserting heading in list
# getting list of all the article
# elements with class "Box-row"
count = self.driver.\
find_elements_by_xpath('//article[@class="Box-row"]')
for c in range(1, len(count)+1):
# creating custom path for fetching
# "built by" under each article element
x_count = '(//article[@class="Box-row"])' \
'[{}]/div[@class="f6 text-gray mt-2"]' \
'/span[@class="d-inline-block mr-3"]' \
'/a/img'.format(str(c))
img_elem = self.driver.\
find_elements_by_xpath(x_count)
# joining all the 'built by' with "|"
users_ = "|".\
join([elem.get_attribute('alt') for elem in img_elem])
# appending result to user_data list
user_data.append(users_)
- Вызывает process_xpath () для получения данных из xpaths.
- Отправляет полученные данные в create_csv () для экспорта данных в виде файла CSV.
И это все, что вам нужно сделать, чтобы очистить веб-сайт. Я имею в виду, что еще многое можно сделать, но этого должно хватить для простой веб-страницы.
Весь код хорошо документирован, поэтому вам будет легче понять, но если кто-то где-то застрянет, я буду более чем счастлив помочь 😊. Код соответствует PEP 8, был запущен и протестирован.
Вы все еще можете много повозиться с этим кодом, вот некоторые из моих предложений:
- Вы можете преобразовать метод create_csv () в статический метод, поскольку это просто служебная функция.
- Я не копал формулировки или описания репо, потому что есть вероятность, что они могут отсутствовать для конкретного репо. Вы можете исправить это, указав значение по умолчанию, если элемент отсутствует.
Так что вперед, протестируйте его, создайте своего собственного бота, но будьте вежливы, потому что помните, что я не несу ответственности за ваши действия, всегда принимайте во внимание robots.txt и принимайте разрешения.
Хороших выходных. Удачного кодирования 🍻.