Искусственные нейронные сети, такие как MLP (многослойный перцептрон) и CNN
(сверточные нейронные сети), успешно используются для статической
классификации вредоносных программ. Эта статья должна помочь новичкам в области глубокого обучения применять эти модели на практике, поскольку мы рассмотрим задачу статической классификации вредоносных программ. Предположим, что читатель только что изучил, что такое MLP и CNN, но еще не использовал их. Мы также не будем сосредотачиваться на коде, а скорее проведем читателя через весь процесс и, надеюсь, дадим интуицию, которая пригодится в будущем. Мы также объясним различные метрики, которые полезны в двоичной классификации. Вы также можете изучить код на странице https://gitlab.fit.cvut.cz/bielima2/mvi-sp.
Описание данных
Набор данных EMBER содержит функции, извлеченные из исполняемых файлов в формате PE (Portable Executable). Каждый файл абстрагируется в объект JSON, который впоследствии может быть преобразован в вектор признаков, содержащий 2351 размер. Помимо данных JSON, авторы набора данных также предоставили методы для преобразования его в векторы признаков. Эти методы реализуют методы внедрения, например, при необходимости, трюк с хешированием. Мы сосредоточимся на EMBER2018, который содержит:
- данные обучения:
- - 200 000 немаркированных образцов
- - 300 000 вредоносных образцов
- - 300 000 доброкачественных образцов
- данные испытаний:
- - 100 000 вредоносных образцов
- - 100 000 доброкачественных образцов
Предварительная обработка данных
В самом начале немаркированные образцы были убраны. Первое препятствие, которое возникло в процессе построения наших классификаторов, заключалось в том, что его нельзя было обучить на необработанных 2351 размерных векторах, предоставленных набором данных. Точность даже на обучающих данных всегда была не лучше, чем точность случайного классификатора, независимо от архитектуры сети. Причина в том, что дисперсия данных была слишком большой, а именно 8,8196516 × 10¹⁴. С другой стороны, точность дерева решений с градиентным усилением, предоставленная авторами набора данных, составила 93,61%. Мы решили стандартизировать данные, рассчитав стандартный балл. Поскольку полученные данные содержали значения NaN (Not a Number), точность по-прежнему была не лучше случайной. После установки значения NaN на ноль нейронные сети начали обучение.
Следующим шагом было изучение данных с помощью PCA (анализа главных компонентов). PCA показал, что первое измерение нового пространства содержит примерно 3,5% дисперсии и что первые 1024 компонента содержат примерно 90% дисперсии. Поскольку обучение с использованием 1024-мерных векторов намного быстрее, чем обучение с исходными векторами, и потеря информации была допустимой, мы решили использовать это сокращение.
Эксперименты
Нейронные сети в экспериментах реализованы с использованием библиотеки Keras. Мы также применили метод оптимизации гиперпараметров, называемый случайным поиском, который реализован в библиотеке Keras Tuner.
Помимо метрики точности для оценки модели, мы также будем учитывать метрики точности и отзыва. В этих показателях используются понятия истинных и ложных срабатываний и отрицаний. При обнаружении вредоносных программ ложное срабатывание означает, что файл считается вредоносным, хотя на самом деле он безвреден. С другой стороны, ложноотрицательный результат означает, что вредоносная активность не обнаружена.
В нашем случае точность описывает стоимость ложных срабатываний (когда наша модель ошибочно считает, что доброкачественный файл является вредоносным) и определяется следующей формулой:

Напоминание определяется аналогичным образом:
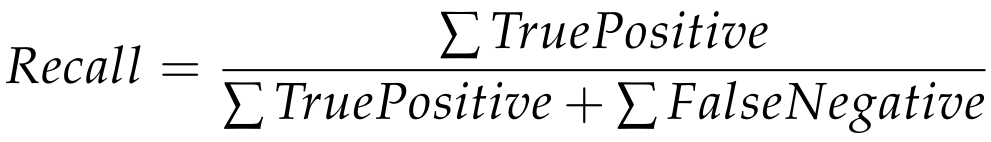
Обратите внимание, что знаменатель в определении отзыва на самом деле является суммой всех действительно положительных образцов. Напомним, описывает, насколько хороша наша модель для захвата действительно вредоносных файлов, и поэтому ее можно рассматривать как вероятность обнаружения.
Мы также будем использовать термины FPR (ложноположительная ставка) и TPR (истинно положительная ставка). FPR определяется по следующей формуле:

Еще раз обратите внимание, что знаменатель - это сумма всех действительно отрицательных образцов. TPR определяется так же, как отзыв, и поэтому является просто синонимом. Мы будем использовать кривые ROC (рабочие характеристики приемника), которые показывают взаимосвязь между FPR и TPR. Цель двоичного классификатора - иметь высокий TPR при низком FPR. Таким образом, мы можем сравнивать наши модели на основе этого показателя. Другой показатель - AUC (Площадь под кривой). Эта метрика объединяет площадь под кривой ROC. В идеальном классификаторе AUC должна быть равна 1.
Многослойные сети персептронов
Поскольку машинное обучение с использованием нейронных сетей - это эмпирическая область, мы начинаем с экспериментов с сетевой архитектурой и ее гиперпараметрами. Чтобы оценить эти параметры, модель была запущена несколько раз на сокращенном наборе данных за 5 эпох.
Модель MLP была запущена 6000 раз с помощью процедуры случайного поиска с различными гиперпараметрами, и лучшие 10 запусков имели следующие общие свойства: выпадение было установлено на ноль, функция активации была ReLU (выпрямленная линейная единица) и метод оптимизации был Адам (Адаптивная оценка моментов). Ширина слоя наиболее эффективных моделей составляла от 512 до 64 нейронов. Слои большего или меньшего размера не были предпочтительны. Эти результаты предоставили элементарное представление о подходящих моделях, и предыдущие гиперпараметры были установлены для всех последующих моделей.
Следующим шагом была оценка наиболее подходящей глубины сети. Модель была запущена снова 3000 раз, и наиболее эффективная сеть имела 4 слоя с 512 нейронами, 2 слоя с 128 нейронами и один слой с 64 нейронами. Затем эта сеть была повторно обучена на полном наборе данных для 50 эпох, поскольку дальнейшее обучение не дало никакого улучшения производительности.
Последний слой всегда имел один нейрон с сигмовидной функцией в качестве функции активации. Функция потерь представляет собой меру кросс-энтропии. Скорость обучения была выбрана библиотекой Keras автоматически.
Сверточные нейронные сети
Как упоминалось во введении, CNN также использовались для статического анализа вредоносных программ. Мы попытались построить 1D CNN аналогично тому, как описано в предыдущем разделе. В этот раз; однако поиск гиперпараметров был намного медленнее из-за более высоких вычислительных требований - модель намного медленнее обучалась, а пространство поиска гиперпараметров было намного больше. Модель запускалась 3000 раз, и наиболее эффективная сеть имела следующие свойства: было три сверточных слоя с 16 ядрами, размер каждого ядра был 32. Также было четыре плотных слоя MLP с размерами 512, 256, 128 и 64 Параметр шага сверточных слоев был установлен вручную на два, чтобы ускорить обучение. Остальные гиперпараметры остались такими же, как в модели MLP.
Исследователи также пытались обнаружить вредоносное ПО, преобразовав его в изображения, а затем применив 2D CNN. Мы также попробовали такой подход, преобразовав векторы признаков в матрицы (с 32 строками и столбцами, поскольку векторы признаков имеют 1024 измерения), а затем наивно попытались адаптировать и переобучить предварительно созданную CNN под названием VGG16. Мотивом для этого было выяснить, может ли сеть с архитектурой, которая хорошо работает для распознавания общих изображений, иметь хорошую производительность и в нашей области. Первоначально в сети было 1000 выходных нейронов. Мы добавили еще один нейрон поверх этого слоя, чтобы преобразовать сеть в бинарный классификатор. Функция активации нейрона была сигмовидной функцией. Метод оптимизации и функция потерь также были выбраны такими же, как и в модели MLP. Сверточные сети также обучались на полном наборе данных за 50 эпох.
Результаты
В следующей таблице показано сравнение показателей обученных моделей на тестовых данных. Модель MLP имеет высочайшую точность, а также превосходит базовую версию GBDT, предоставляемую библиотекой ember. Также стоит отметить, что модель MLP имеет гораздо более простую архитектуру, чем, например, сеть VGG16.

На следующих двух рисунках показаны кривые ROC для наших обученных моделей. Модель MLP имеет лучший ROC примерно до 15% FPR, где он превосходит модель GBDT. Адаптированный VGG16 на самом деле имеет худшие характеристики.


На следующем рисунке показано классификационное распределение модели MLP. Мы видим, что для большинства образцов модель дает уверенно правильный ответ. Однако существует также значительное количество образцов, для которых модель также с уверенностью дает неверный ответ.

Следующие два рисунка показывают, что сверточные сети имеют поведение, подобное модели MLP, в отношении распределения классификации.


На следующем рисунке показано распределение классификации для модели MLP, которая классифицирует необработанные данные из набора данных. Мы видим, что модель классифицировала большинство образцов как положительные (выходное значение для большинства образцов было 0,5). Это причина, по которой эта модель пользуется наибольшим спросом в таблице выше. Однако точность очень низкая, и поскольку набор данных содержит равное количество доброкачественных и вредоносных образцов, точность близка к точности случайного классификатора, которая составляет ровно 50%.

Эксперименты по уменьшению размерности
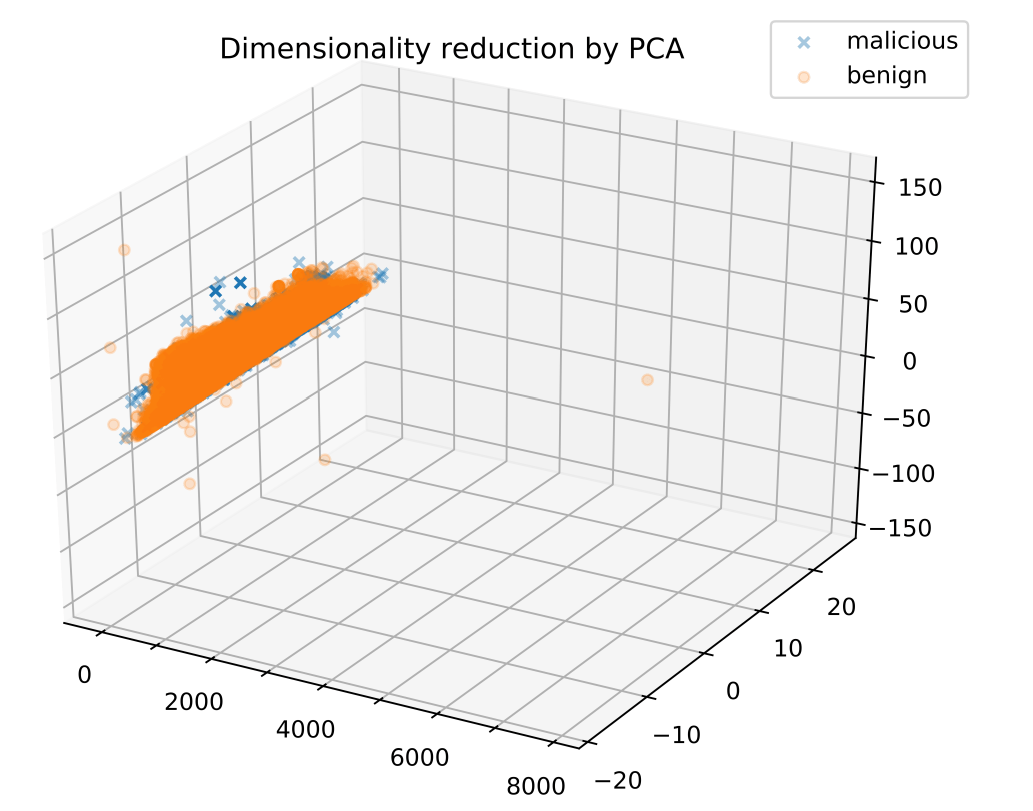
Помимо PCA, VAE (Variational AutoEncoder) также может использоваться для уменьшения размерности данных. Мы экспериментально построили и обучили VAE, который сокращает наши данные до трех измерений. Архитектура и гиперпараметры кодера и декодера VAE были выбраны таким образом, чтобы они соответствовали наиболее эффективной модели MLP. На следующем изображении показаны полученные трехмерные данные.

Мы видим, что все образцы собраны в одно плотное облако, а это значит, что классификация - непростая задача. Для сравнения, последнее изображение показывает те же данные после сокращения до трех измерений с помощью PCA.