Автор: Ада Чжу ([email protected]) и Сиддхарт Суреш ([email protected])

Мотивация:
Это руководство представляет собой введение в алгоритм обнаружения аномалий на основе неконтролируемого дерева — Isolation Forest. Мы намерены направить эту статью всем, кто интересуется методами интеллектуального анализа данных, ориентированными на обнаружение аномалий. Будучи аспирантами Школы наук о данных Университета Вирджинии, мы нашли этот метод уникальным, но он очень мало освещается в Интернете (у него нет страницы в Википедии). Надеюсь, что эта статья поможет привлечь больше внимания к этому алгоритму.
Введение:
Обнаружение аномалий[1] — это метод, используемый для выявления выбросов или аномалий в данных. Он основан на том принципе, что некоторые наблюдения отклоняются от общих характеристик или свойств набора данных до такой степени, что их можно отнести к категории аномалий.
Аномалии обычно становятся частью набора данных через:
- Ошибки в наборе данных
2. Действия, которые отклоняются от обычного/нормального поведения
Обнаружение аномалий полезно для различных вариантов использования, включая, помимо прочего, обнаружение мошенничества, атаки на веб-сервер, наблюдение, безопасность.
Хотя существует множество методов обнаружения аномалий, одним из них является использование метода, называемого изолированным лесом.
Свойства изолированного леса:
- Это неконтролируемая модель на основе дерева
- На основе длины пути вместо измерения расстояния или плотности
- Может масштабироваться для обработки больших размерных данных
- Обеспечивает подвыборку данных и может эффективно обучаться даже при отсутствии аномалий в выборке.
- Имеет линейную временную сложность и минимальные требования к памяти
Как это работает:
Изолирующий лес работает по принципу, согласно которому легче изолировать аномалии в наборе данных, чем изолировать обычные экземпляры/наблюдения. Чтобы понять это, давайте сначала посмотрим, как работает древовидная модель.
Модель на основе дерева использует дерево решений для определения значения/класса наблюдения с учетом его значения. То есть он определяет путь от корневого узла к конечному узлу на основе значения рассматриваемого наблюдения. Конечный узел в этом случае может быть либо непрерывным значением, либо классом, что делает дерево соответственно деревом регрессии или деревом классификации (см. рисунок [2] ниже).
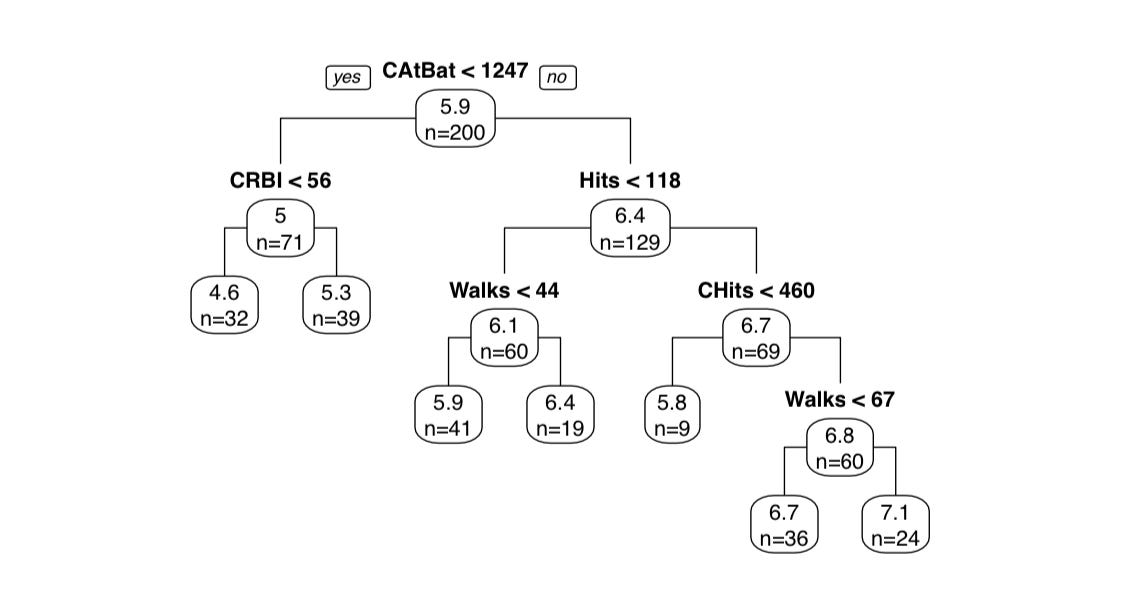
Случайный лес [3], тип модели на основе дерева, использует ансамблевое обучение для принятия решений. Он работает, создавая множество различных деревьев решений и усредняя их, чтобы получить окончательное решение. Он делает это путем случайного выбора «m» объектов из «k» общих объектов в наборе данных и создает дерево на основе наилучшей точки разделения среди «m» объектов и создает два узла. Этот процесс выполняется итеративно для каждой точки разделения, где выбираются «m» случайных признаков и, следовательно, название «случайный лес». После создания множества таких деревьев их можно усреднить, чтобы получить окончательное дерево решений.
Изолирующий лес — это просто расширение случайного леса, где цель меняется с прогнозирования значения/класса наблюдения на предоставление оценки аномалии каждому из наблюдений на основе средней длины пути, которую имеет узел. В то время как Random Forest работает по контролируемому методу, Isolation Forest работает по неконтролируемому методу из-за этой разницы в каждой из их целей.
Основной алгоритм:
Алгоритм дерева изоляции состоит из двух этапов, и алгоритм работает следующим образом [4]:
Обучение
- Создайте подвыборку исходных данных дерева
- Проверьте, можно ли разделить подвыборку. Если оно не делится, верните его размер. Если можно разделить, перейдите к следующим шагам
- Случайным образом выберите одну из переменных из подвыборки и разделите ее на основе случайного выбора значения из минимального и максимального значения этой переменной.
- Создайте два поддерева, одно из которых содержит все значения, большие или равные разбиению (Xr для правого поддерева), а другое содержит значения, меньшие разбиения (Xl для левого поддерева).
- Рекурсивно вызывать поддеревья, чтобы пройти через все остальные переменные в наборе данных дерева.
- Вернуть дерево изоляции
- Повторите вышеуказанные шаги определенное количество раз в зависимости от количества деревьев, указанных на входе алгоритма, и объедините деревья из каждой из итераций для построения ЛЕСА.
Оценка
- Рассчитайте длину одного пути, подсчитав количество ребер от корневого узла до предопределенного узла, когда экземпляр проходит через дерево.
- Если длина превышает предопределенный предел высоты, возвращает текущую длину плюс значение корректировки, которое оценивает или корректирует длину на основе средней длины пути.
- Вычислите показатель аномалии, используя формулу:

4. Оценка, близкая к 1, означает, что наблюдение, скорее всего, является аномалией, а оценка 0,5 или меньше означает, что наблюдение, скорее всего, является нормальным наблюдением.
Пакеты R:
Вот некоторые из пакетов, с которыми мы столкнулись:
- Одиночество [5]
- ИзоляцияЛес[6]
- Изофор[7]
Пакет, который мы использовали в руководстве, называется «Solitude». Он реализует весь процесс Isolation Forest в R. Он создает объект одиночества с помощью функцииisolationForest$new(). Затем он соответствует дереву изоляции в наборе данных, используя метод fit(). Функция score() вычисляет глубины и оценки аномалий каждого наблюдения в наборе данных. Предсказание () принимает тестовые данные и возвращает соответствующие оценки аномалий на основе дерева, построенного на обучающем наборе.
Набор данных:
Мы создали два набора данных для изучения целей — обучение и тестирование. Оба набора данных были построены в двумерном пространстве, при этом в наборе поездов было 650 строк, а в тестовом наборе — 2525 строк. Мы намеренно установили набор поездов маленьким, а набор тестов большим, чтобы наблюдать, может ли обучение на ограниченных данных по-прежнему давать хорошие прогнозы на относительно большом наборе тестов.
В наборе поездов мы сгенерировали кластеры из трех нормальных распределений с разными средними значениями и стандартными отклонениями (окрашены синим, зеленым и фиолетовым цветом) и аномалии из равномерного распределения размера 50 (окрашены красным).
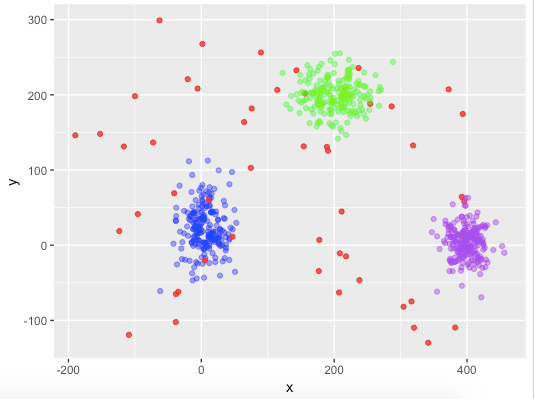
Мы сгенерировали тестовые данные, нарисовав точки из одного нормального распределения и 25 аномалий из равномерного распределения.

Анализ данных:
Isolation Forest определяет аномалии на основе их оценок. Чем ближе они к 1, тем больше вероятность того, что это аномалии. Однако, если их оценки ниже 0,5, это, вероятно, просто нормальные точки в тренде. На приведенном ниже графике плотности видно, что большинство точек в нашем поезде ниже 0,5, в то время как некоторые из сгенерированных данных имеют оценки ближе к 0,7, что можно классифицировать как аномалии.

Результаты:
На следующих двух графиках показаны фактически сгенерированные аномалии и аномалии, предсказанные с помощью Isolation Forest соответственно. Сравнивая с фактическим тестовым набором, мы видим, что большинство точек классифицируются правильно, за исключением нескольких точек в правом верхнем углу, которые не классифицируются как аномалии, и нескольких точек в нижней части толпы, которые ошибочно классифицируются как аномалии.
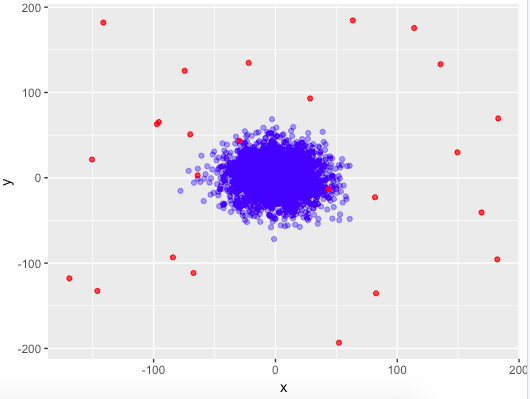
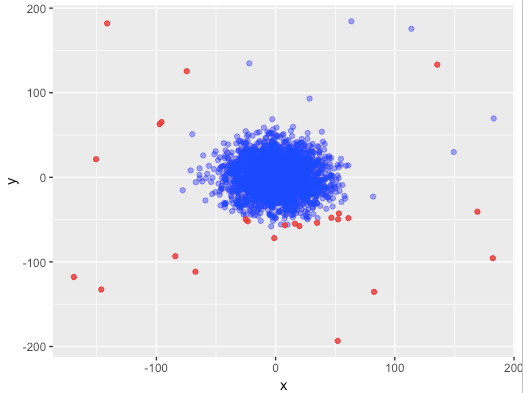
Следует отметить, что классификация аномалий зависит от порога, который мы устанавливаем для показателей аномалий. Мы установили пороговое значение 0,53, чтобы включить такое же количество аномалий, как и в тестовом наборе, но это значение может быть скорректировано в разных случаях. Если порог увеличить, будет обнаружено меньше аномалий, и наоборот.
Мы можем заметить, что алгоритм способен идентифицировать большинство аномалий и хорошо работает даже в двумерном пространстве.
Вывод:
Изолирующий лес — это эффективный способ выявления аномалий в группах данных. Он гибкий и может классифицировать точки на основе длины пути/баллов, а не показателей расстояния или плотности. Алгоритм может стать полезным с данными высокой размерности, когда имеется больше предикторов, и изоляция аномалий на основе более низкой средней длины пути становится намного более эффективной.
Кажется, что эта тема менее известна, и мы надеемся изучить ее больше в будущем. Надеюсь, это краткое руководство поможет.
Пожалуйста, проверьте нашу страницу Github для получения самого обновленного кода:
https://github.com/adazhu365/Isolation-Forest
Ссылки:
[1] https://en.wikipedia.org/wiki/Anomaly_detection
[2] Стр. 5/17, Лекция 10, SYS6018 | Осень 2019 г., доктор Майкл Д. Портер, доцент Университета Вирджинии.
[3] https://en.wikipedia.org/wiki/Random_forest
[4] Ф. Т. Лю, К. М. Тинг и З.-Х. Чжоу. Изолирующий лес, 2008 г. https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
[5] https://cran.r-project.org/web/packages/solitude/solitude.pdf
[6] https://sourceforge.net/projects/iforest/
[7] https://github.com/Zelazny7/isofor
[8] Предварительный просмотр изображения: https://www.pinclipart.com/downpngs/oRxRRh_anomaly-and-fraud-detection-anomaly-detection-clipart-png/