
Будучи заядлым читателем манги, я вижу, как цифровые художники раскрашивают черно-белые страницы и размещают их на социальных платформах. Они крутые
Прежде чем я смог сразу перейти к созданию моделей для обучения, отсутствовала часть набора данных.
Набор данных
Сначала идет часть сбора данных. Нейронные сети жадны до данных, то есть им нужно огромное количество данных. Я не смог найти готовый набор данных в сети. Так что пришлось выдрать из сети и скачать.
Множество данных означает множество глав манги. В таком случае нас может спасти только One Piece. В нем более 1000 глав, и, поскольку у него огромное количество поклонников, художники раскрасили их и загрузили на сайты. Каждую главу раскрашивает специальная команда людей, но это занимает много времени.
Сбор данных занял очень много времени. У него был свой набор проблем — неоднородные каналы, типы изображений и многое другое. Очистка датасета заняла много времени — из датасета пришлось убрать рекламу, переводчик и QA ODA.

Юнет
Первой реализацией, которую я попробовал, была базовая архитектура UNET, состоящая из 4 блоков понижающей дискретизации, мостового соединения и 4 блоков повышающей дискретизации. Экспериментировал с различными функциями активации, магистральными сетями MobileNet, DenseNet и MobileNetV2, с разными временными периодами для каждой сети.



Вывод не был ожидаемо цветным, а выглядел как тип сегментации. Правый (c) — худший результат, полученный при игре с архитектурой — сделал скрытое пространство чрезвычайно маленьким. Средний (b) был получен с использованием активации RELU, магистрали MobileNet, а первый (a) получен с использованием функции SWISH, нормальных сверток.

GAN (генеративно-состязательная сеть)
«Генеративно-состязательные сети — самая интересная идея в машинном обучении за последние 10 лет», — Ян ЛеКун.
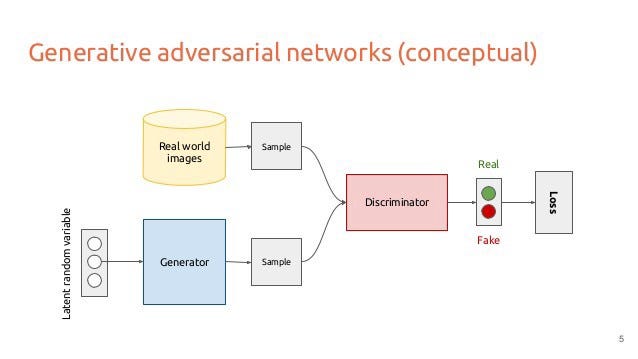
GAN — это захватывающая и быстро меняющаяся область, реализующая обещания генеративных моделей в их способности генерировать реалистичные примеры в различных предметных областях.
В первую очередь в задачах преобразования изображения в изображение, таких как перевод фотографий лета в зиму или дня в ночь, а также в создании фотореалистичных фотографий объектов, сцен и людей, которые даже люди не могут подделка.
3 основные части GAN:
- ) Генератор — использование генератора для создания выходных данных с использованием случайного шума или, в нашем случае, с использованием инициализатора ядра случайного нормального шума вместо обычного униформа глорота.
- ) Дискриминатор — одновременная передача реального (целевого изображения) и поддельного генерируемого вывода генератора путем объединения с дискриминатором для проверки подлинности или подделки. Он выступает в роли критика.
- ) Функция потерь — создание функции потерь на основе выходных данных генератора и дискриминатора.
Для этой задачи я решил использовать Conditional Gan. См. бумага. Различные эксперименты с GAN проводились с набором данных из 1 тыс. изображений (почему? Объясню позже) —
1.)Функции активации — relu, дырявый relu и swish
2.) Методы нормализации — [0,255] и [-1,1]
3.) Финальный слой активации — softmax и tanh
4.) Генератор — без магистрали, уровень узкого места MobileNetV2
5.) Увеличение/уменьшение скрытого пространства
Наилучший результат был получен по следующим параметрам:
- Использование RELU в генераторе, нормализация изображения до [-1,1] и использование функции tanh в выходном слое.
- Использование LeakyRelu и Dropout в Дискриминаторе.
- Инициализатор ядра — random_normal_initializer(0., 0.01)
Функция потерь
В этой архитектуре у нас есть две потери — потеря генератора и потеря дискриминатора.
Потери генератора рассчитываются путем нахождения сигмовидной кросс-энтропийной потери выхода генератора и массива единиц. Кроме того, чтобы выход был структурно похож на целевое изображение, мы берем вместе с ним потери L1. Функция общих потерь рассчитывается на основе статьи с использованием лямбда как 100.
Потери дискриминатора рассчитываются аналогичным образом с использованием сигмовидной кросс-энтропии. Общие потери представляют собой сумму потерь сгенерированного фальшивого изображения и потерь реального целевого изображения.
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
LAMBDA = 100
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
Что касается оптимизатора, был использован Адам.
Результаты


Учитывая набор данных из 1k изображений, результаты достаточно хорошие, но не выдающиеся.
Почему только 1k изображений и как улучшить результаты?
Условный GAN следует использовать, когда изображения представлены парами, то есть черно-белое изображение и цветное. Так в чем же дело?
Изображения манги не могут быть легко объединены, потому что оригинальная работа написана на японском языке, а цветные — на английском. Проводится большая работа по редактированию, чтобы преобразовать мангу в цветную. Но все же есть много проблем -



Вот пример. Страницы разделены и расположены по-разному. Более того, в некоторых главах есть большая разница в словах звуковых эффектов, некоторые в японском, а некоторые в английском.
Лучшим подходом для этого случая было бы использование CGAN (цикл GAN). Задача здесь - преобразование изображения в изображение, то есть передача цветового стиля. Дело не в том, что условный Ган нельзя использовать в этом использовании, просто курирование данных и проверка каждого изображения по отдельности, если оно одинаковое, займет много времени. времени, учитывая, что есть более 1000 глав.
В следующем блоге, во второй части, мы будем использовать CGAN для раскрашивания манги.
Код будет опубликован на Github вместе со второй частью.