
OneHotEncoder. Это одна из техник, о которых я говорил и использовал во многих своих предыдущих блогах, но никогда особо не говорил об этой концепции. Так что же такое One Hot Encoding.
OneHotEncoding - это в основном метод, который используется для преобразования ваших категориальных текстовых данных в числовую форму. Но зачем нам это делать?
Итак, ответ на этот вопрос довольно прост. Алгоритмы машинного обучения хорошо работают с числовыми данными, но они не могут действительно обрабатывать или понимать текстовые данные, если мы передадим их модели как есть. Я попытаюсь объяснить это на примере.
Рассмотрим столбец Пол в наборе данных, и значения в этом столбце - [«Мужской», «Женский»]. Теперь, если я передам эту гендерную колонку моей модели напрямую, она не сможет обработать или понять что-либо вне модели. Вот почему нам нужно использовать OneHotEncoding, который может помочь с преобразованием этих данных в числовые столбцы, такие как [0,1], где 0 представляет мужчину, а 1 представляет женщину. Теперь следующий процесс также можно выполнить с помощью labelencoder, но они принимают только один столбец в качестве параметра, тогда как, с другой стороны, OneHotEncoder принимает все столбцы функций и преобразует их в категориальные числовые данные. . После того, как мы закодировали наши данные, мы можем легко продолжить с MinMaxScaler (), чтобы повысить точность и эффективность модели, которая у нас есть. Я соберу короткую демонстрацию, чтобы понять основы OneHotEncoding.
Хорошо, приступим к реализации. Я запускаю этот блокнот на Kaggle, поэтому ссылка на набор данных указана ниже (ранее использованный набор данных):
Начнем с импорта нашего набора данных и необходимых библиотек.
import pandas as pd
import numpy as np
data=pd.read_csv('../input/customer-segmentation-tutorial-in-python/Mall_Customers.csv')
print("The given data has dimension of {}".format(data.shape))
data.head()

Если мы посмотрим на столбец выше, у нас есть столбец под названием Пол. Они содержат двоичные значения "Мужской" и "Женский", поэтому я попытаюсь преобразовать их в двоичные значения, такие как 0 и 1.
Для реализации я собираюсь импортировать sklearn .preprocessing библиотек, которые необходимы для процесса кодирования.
from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder
Давайте выберем данный столбец Gender и сохраним его как переменную.
cat_data=data['Gender']
Далее необходимо создать объект типа LabelEncoder (), который мы импортировали, и подогнать наши данные к этому объекту, чтобы произошло преобразование.
labelEncoder=LabelEncoder() integer_encoded = labelEncoder.fit_transform(cat_data) print(integer_encoded)
Мы сохранили преобразованные значения в переменной с именем integer_encoded, и когда мы печатаем значения, они выглядят примерно так:

Мы можем заметить, что значения уже были преобразованы по мере необходимости, но вы поймете разницу между этим значением и значением OneHotEncoded после того, как преобразование будет выполнено. Не забудьте преобразовать integer_encoded после преобразования массива в двумерный массив с помощью функции array.reshape ().
integer_encoded=integer_encoded.reshape(-1,1) onehot_encoder = OneHotEncoder(sparse=False) onehot_encoded = onehot_encoder.fit_transform(integer_encoded) print(onehot_encoded)
Когда мы печатаем значения OneHotEncoded, мы получаем следующие значения:
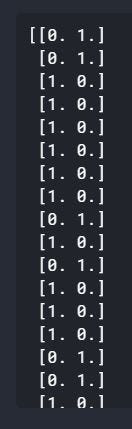
Разница в том, что для каждого значения или каждой записи в наборе данных значения OneHotEncoded представляют 0 в мужской позиции и 1 в женской позиции, и каждая строка имеет атрибуты Male и Female. Имейте в виду, что использовать две переменные для onehotencoder не очень полезно, и в основном это используется вместе с многоклассовыми переменными.
На этом этапе вы можете прикрепить этот OneHotEncoded, прикрепив этот столбец к фрейму данных или используя переменную в столбце функции.
На сегодня все. Продолжай учиться.
Ваше здоровье.