
Эта статья изначально была написана Дерриком Мвити и размещена в блоге Neptune.
В бизнесе существует распространенная поговорка о том, что нельзя улучшить то, что не измеряешь. Это верно и для машинного обучения. Существуют различные инструменты для измерения производительности модели глубокого обучения: Neptune AI, MLflow, Weights and Biases, Guild AI, и это лишь некоторые из них. В этой части мы сосредоточимся на наборе инструментов визуализации TensorFlow с открытым исходным кодом TensorBoard.
Инструмент позволяет отслеживать различные показатели, такие как точность и потери журнала при обучении или проверочном наборе. Как мы увидим в этой части, TensorBoard предоставляет несколько инструментов, которые мы можем использовать в экспериментах по машинному обучению. Инструмент также довольно прост в использовании.
См. также: Лучшие инструменты для визуализации моделей машинного обучения
Вот некоторые вещи, которые мы рассмотрим в этом тексте:
- Визуализация изображений в TensorBoard
- Проверка веса и смещения модели на TensorBoard
- визуализация архитектуры модели
- отправка изображения матрицы путаницы в TensorBoard
- профилирование вашего приложения, чтобы увидеть его производительность, и
- использование TensorBoard с Keras, PyTorch и XGBoost
Приступим к делу.
Как использовать Тензорборд
Этот раздел посвящен тому, чтобы помочь вам понять, как использовать TensorBoard в рабочем процессе машинного обучения.
Как установить Тензорборд
Прежде чем вы сможете начать использовать TensorBoard, вы должны установить его либо через pip, либо через conda.
pip install tensorboard conda install -c conda-forge tensorboard
Использование TensorBoard с блокнотами Jupyter и Google Colab
Установив TensorBoard, вы можете загрузить его в свой ноутбук. Обратите внимание, что вы можете использовать его в Jupyter Notebook или Google Colab.
%load_ext tensorboard
Как только это будет сделано, вы должны установить каталог журнала. Здесь TensorBoard будет хранить все журналы. Он будет считывать данные из этих журналов, чтобы отображать различные визуализации.
log_folder = 'logs'
Если вы хотите перезагрузить расширение TensorBoard, приведенная ниже команда сделает волшебство — без каламбура.
%reload_ext tensorboard
Возможно, вы захотите очистить текущие журналы, чтобы вы могли записывать новые в папку. Вы можете добиться этого, запустив эту команду в Google Colab
!rm -rf /logs/
на ноутбуках Jupyter
rm -rf logs
Если вы проводите несколько экспериментов, вы можете сохранить все журналы, чтобы иметь возможность сравнивать их результаты. Этого можно достичь путем создания журналов с временными метками. Для этого используйте команду ниже:
import datetime
log_folder = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
Как запустить TensorBoard
Для запуска Tensorboard требуется всего одна строка кода. В этом разделе вы увидите, как это сделать.
Давайте теперь рассмотрим пример, в котором вы будете использовать TensorBoard для визуализации метрик модели. Для этого вам нужно построить простую модель классификации изображений.
import tensorflow as tf mnist = tf.keras.datasets.mnist (X_train, y_train), (X_test, y_test) = mnist.load_data() X_train, X_test = X_train / 255.0, X_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax')]) model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Затем загрузите расширение ноутбука TensorBoard и создайте переменную, указывающую на папку журнала.
%load_ext tensorboard log_folder = 'logs'
Как использовать обратный вызов TensorBoard
Следующим шагом является указание обратного вызова TensorBoard во время метода подгонки модели. Для этого вам сначала нужно импортировать обратный вызов TensorBoard.
Этот обратный вызов отвечает за регистрацию событий, таких как гистограммы активации, сводные графики метрик, профилирование и визуализация обучающих графиков.
from tensorflow.keras.callbacks import TensorBoard
Теперь вы можете создать обратный вызов TensorBoard и указать каталог журнала с помощью log_dir. Обратный вызов TensorBoard также принимает другие параметры:
- histogram_freq — частота, с которой вычисляются гистограммы активации и веса для слоев модели. Установка этого параметра на 0 означает, что гистограммы не будут вычисляться. Чтобы это работало, вы должны установить проверочные данные или разделение проверки.
- write_graph определяет, будет ли граф отображаться в TensorBoard.
- write_images, если установлено значение true, веса модели визуализируются как изображение в TensorBoard.
- update_freq определяет, как потери и метрики записываются в TensorBoard. Если задано целое число, например 100, потери и показатели регистрируются каждые 100 пакетов. При пакетной настройке потери и показатели устанавливаются после каждой партии. При установке на эпоху они записываются после каждой эпохи
- profile_batch определяет, какие пакеты будут профилированы. По умолчанию профилируется вторая партия. Вы также можете установить, например, от 5 до 10, чтобы профилировать партии от 5 до 10, т.е. profile_batch=’5,10’. Установка для profile_batch значения 0 отключает профилирование.
- embeddings_freq частота, с которой будут отображаться встраиваемые слои. Установка этого параметра в ноль означает, что вложения не будут визуализированы.
callbacks = [TensorBoard(log_dir=log_folder,
histogram_freq=1,
write_graph=True,
write_images=True,
update_freq='epoch',
profile_batch=2,
embeddings_freq=1)]
Следующим пунктом является соответствие модели и передача обратного вызова.
model.fit(X_train, y_train,
epochs=10,
validation_split=0.2,
callbacks=callbacks)
Как запустить TensorBoard
Если вы установили TensorBoard через pip, вы можете запустить его через командную строку.
tensorboard -- logdir=log
На ноутбуке вы можете запустить его, используя:
%tensorboard -- logdir={log_folder}
TensorBoard также доступен через браузер по следующему URL-адресу.
http://localhost:6006
Удаленный запуск TensorBoard
При работе на удаленном сервере вы можете использовать туннелирование SSH для переадресации порта удаленного сервера на ваш локальный компьютер через порт (в данном примере это порт 6006). Вот как это будет выглядеть:
ssh -L 6006:127.0.0.1:6006 your_user_name@my_server_ip
После этого вы можете запустить TensorBoard обычным способом.
Просто помните, что порт, который вы указываете в команде tensorboard (по умолчанию это 6006), должен быть таким же, как и в туннелировании ssh.
tensorboard --logdir=/tmp --port=6006
Примечание. Если вы используете порт по умолчанию 6006, вы можете удалить –port=6006. Вы сможете увидеть TensorBoard на локальном компьютере, но на самом деле TensorBoard будет работать на удаленном сервере.
Приборная панель TensorBoard
Давайте теперь посмотрим на различные вкладки на TensorBoard.
Скаляры TensorBoard
Вкладка Скаляры показывает изменение потерь и метрик по эпохам. Его можно использовать для отслеживания других скалярных значений, таких как скорость обучения и скорость обучения.
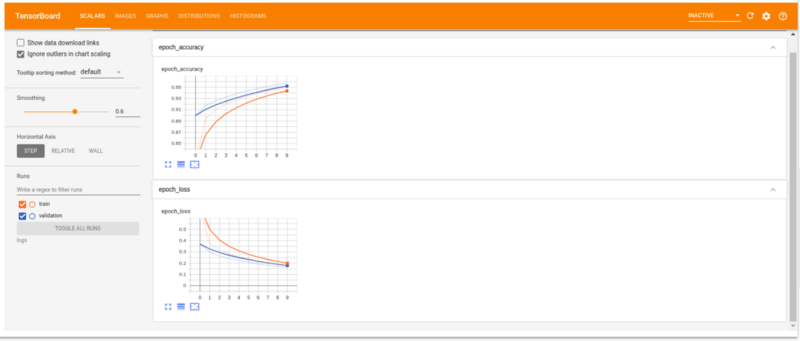
TensorBoard фото
На этой панели есть изображения, которые показывают веса. Регулировка ползунка отображает веса в разные эпохи.
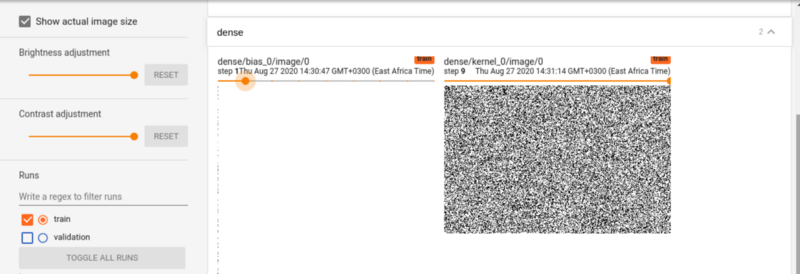
Графики TensorBoard
На этой вкладке отображаются слои вашей модели. Вы можете использовать это, чтобы проверить, выглядит ли архитектура модели так, как задумано.
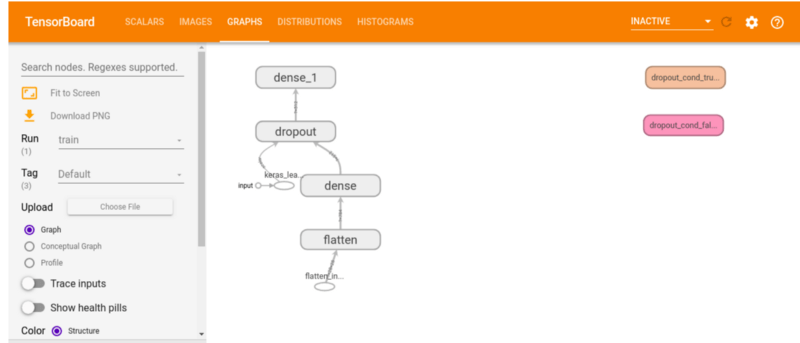
Дистрибутивы TensorBoard
На вкладке распределения показано распределение тензоров. Например, в плотном слое ниже вы можете увидеть распределение весов и смещений по каждой эпохе.
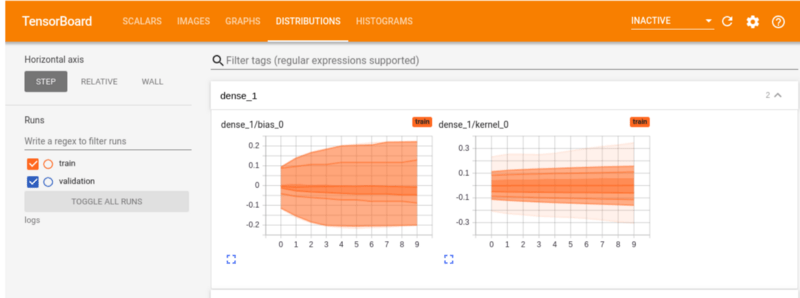
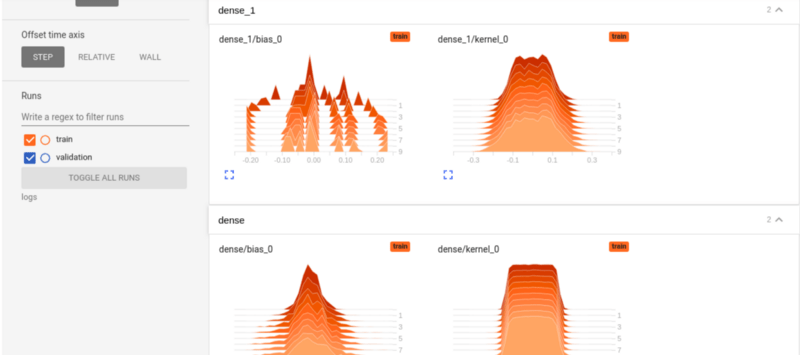
Гистограммы TensorBoard
Гистограммы показывают распределение тензоров во времени. Например, взглянув на плотное_1 ниже, вы можете увидеть распределение смещений по каждой эпохе.
Использование проектора TensorBoard
Вы можете использовать проектор TensorBoard для визуализации любого векторного представления, например. встраивания слов и изображения.
Вложения слов — это числовые представления слов, которые фиксируют их семантические отношения. Проектор поможет вам увидеть эти представления. Вы можете найти его в раскрывающемся списке «Неактивные».
Создавайте обучающие примеры с помощью TensorBoard
Вы можете использовать TensorFlow Image Summary API для визуализации обучающих изображений. Это особенно полезно при работе с данными изображения, как в этом случае.
Теперь создайте новый каталог журнала для изображений, как показано ниже.
logdir = "logs/train_data/"
Следующий шаг — создать средство записи файлов и указать ему этот каталог.
file_writer = tf.summary.create_file_writer(logdir)
В начале этой статьи (в разделе «Как запустить TensorBoard») вы указали, что форма изображения 28 на 28. Это важная информация при изменении формы изображений перед их записью в TensorBoard. Вам также необходимо указать канал равным 1, поскольку изображения имеют оттенки серого. После этого вы используете file_write для записи изображений в TensorBoard.
В этом примере изображения с индексами от 10 до 30 будут записаны в TensorBoard.
import numpy as np
with file_writer.as_default():
images = np.reshape(X_train[10:30], (-1, 28, 28, 1))
tf.summary.image("20 Digits", images, max_outputs=25, step=0)
Визуализируйте изображения в TensorBoard
Помимо визуализации тензоров изображений, вы также можете визуализировать реальные изображения в TensorBoard. Чтобы проиллюстрировать это, вам нужно преобразовать тензоры MNIST в изображения с помощью Matplotlib. После этого вам нужно использовать tf.summary.image для построения изображений в Tensorboard.
Начните с очистки журналов, в качестве альтернативы вы можете использовать папки журналов с отметками времени. После этого укажите каталог журнала и создайте `tf.summary.create_file_writer`, который будет использоваться для записи изображений в TensorBoard.
!rm -rf logs # if Juypter Notebook remove ! import io import matplotlib.pyplot as plt class_names = ['Zero','One','Two','Three','Four','Five','Six','Seven','Eight','Nine'] logdir = "logs/plots/" file_writer = tf.summary.create_file_writer(logdir)
Затем создайте сетку, которая будет содержать изображения. В этом случае сетка будет содержать 36 цифр.
def image_grid():
figure = plt.figure(figsize=(12,8))
for i in range(36):
plt.subplot(6, 6, i + 1)
plt.xlabel(class_names[y_train[i]])
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i], cmap=plt.cm.coolwarm)
return figure
figure = image_grid()
Теперь преобразуйте цифры в одно изображение, чтобы визуализировать его в TensorBoard.
def plot_to_image(figure):
buf = io.BytesIO()
plt.savefig(buf, format='png')
plt.close(figure)
buf.seek(0)
digit = tf.image.decode_png(buf.getvalue(), channels=4)
digit = tf.expand_dims(digit, 0)
return digit
Следующим шагом является использование средства записи и `plot_to_image` для отображения изображений на TensorBoard.
with file_writer.as_default():
tf.summary.image("MNIST Digits", plot_to_image(figure), step=0)
%tensorboard -- logdir logs/plots

Записать матрицу путаницы в TensorBoard
Используя тот же пример, вы можете записать матрицу путаницы для всех эпох. Во-первых, определите функцию, которая будет возвращать фигуру Matplotlib, содержащую матрицу путаницы.
import itertools
def plot_confusion_matrix(cm, class_names):
figure = plt.figure(figsize=(8, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Accent)
plt.title("Confusion matrix")
plt.colorbar()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=45)
plt.yticks(tick_marks, class_names)
cm = np.around(cm.astype('float') / cm.sum(axis=1)[:, np.newaxis], decimals=2)
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
color = "white" if cm[i, j] > threshold else "black"
plt.text(j, i, cm[i, j], horizontalalignment="center", color=color)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
return figure
Затем очистите предыдущие журналы, определите каталог журнала для матрицы путаницы и создайте переменную записи для записи в папку журнала.
!rm -rf logs logdir = "logs" file_writer_cm = tf.summary.create_file_writer(logdir)
Следующим шагом является создание функции, которая будет делать прогнозы на основе модели и регистрировать матрицу путаницы в виде изображения.
После этого используйте `file_writer_cm, чтобы записать` матрицу путаницы в каталог журнала.
from tensorflow import keras
from sklearn import metrics
def log_confusion_matrix(epoch, logs):
predictions = model.predict(X_test)
predictions = np.argmax(predictions, axis=1)
cm = metrics.confusion_matrix(y_test, predictions)
figure = plot_confusion_matrix(cm, class_names=class_names)
cm_image = plot_to_image(figure)
with file_writer_cm.as_default():
tf.summary.image("Confusion Matrix", cm_image, step=epoch)
За этим последует определение обратного вызова TensorBoard и файл LambdaCallback.
LambdaCallback будет регистрировать матрицу путаницы в каждой эпохе. Наконец, подгоните модель, используя эти два обратных вызова.
Поскольку вы уже подгоняли модель ранее, было бы целесообразно перезапустить среду выполнения и убедиться, что вы подгоняете модель только один раз.
callbacks = [
TensorBoard(log_dir=log_folder,
histogram_freq=1,
write_graph=True,
write_images=True,
update_freq='epoch',
profile_batch=2,
embeddings_freq=1),
keras.callbacks.LambdaCallback(on_epoch_end=log_confusion_matrix)
]
model.fit(X_train, y_train,
epochs=10,
validation_split=0.2,
callbacks=callbacks)
Теперь запустите TensorBoard и проверьте матрицу путаницы на вкладке «Изображения».
%tensorboard -- logdir logs
Настройка гиперпараметров с TensorBoard
Еще одна интересная вещь, которую вы можете сделать с TensorBoard, — использовать ее для визуализации оптимизации параметров. Придерживаясь того же примера MNIST, вы можете попытаться настроить гиперпараметры модели (вручную или с помощью автоматической оптимизации гиперпараметров) и визуализировать их в TensorBoard.
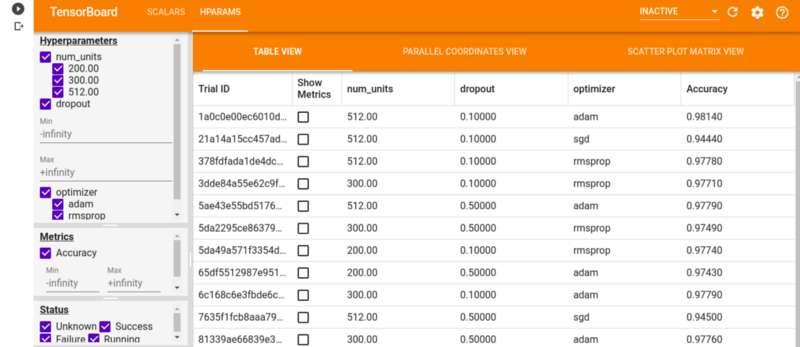
Вот конечный результат, который вы ожидаете получить. Панель мониторинга доступна на вкладке HPARAMS.
Для этого вам нужно очистить предыдущие журналы и импортировать плагин hparams.
!rm -rvf logs logdir = "logs" from tensorboard.plugins.hparams import api as hp
ЧИТАЙТЕ ТАКЖЕ
Настройка гиперпараметров в Python: полное руководство 2020
Следующим шагом является определение параметров для настройки. В этом случае будут настроены единицы в плотном слое, скорость отсева и функция оптимизатора.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([300, 200,512]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1,0.5))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd', 'rmsprop']))
Затем используйте tf.summary.create_file_writer, чтобы определить папку, в которой будут храниться журналы.
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],)
После этого вам нужно определить модель, как вы это делали ранее. Единственное отличие состоит в том, что количество нейронов в первом плотном слое, частота отсева и функция оптимизатора не будут жестко запрограммированы.
Это будет сделано в функции, которая будет использоваться позже при проведении экспериментов.
def create_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation='relu'),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation='softmax')])
model.compile(optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5)
loss, accuracy = model.evaluate(X_test, y_test)
return accuracy
Следующая функция, которую вам нужно создать, будет запускать функцию, указанную выше, с параметрами, определенными ранее. Затем он будет регистрировать точность.
def experiment(experiment_dir, hparams):
with tf.summary.create_file_writer(experiment_dir).as_default():
hp.hparams(hparams)
accuracy = create_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
После этого вам нужно запустить эту функцию для всех комбинаций параметров, определенных выше. Каждый из экспериментов будет храниться в отдельной папке.
experiment_no = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,}
experiment_name = f'Experiment {experiment_no}'
print(f'Starting Experiment: {experiment_name}')
print({h.name: hparams[h] for h in hparams})
experiment('logs/hparam_tuning/' + experiment_name, hparams)
experiment_no += 1

Наконец, запустите TensorBoard, чтобы увидеть визуализацию, которую вы видели в начале этого раздела.
%tensorboard -- logdir logs/hparam_tuning
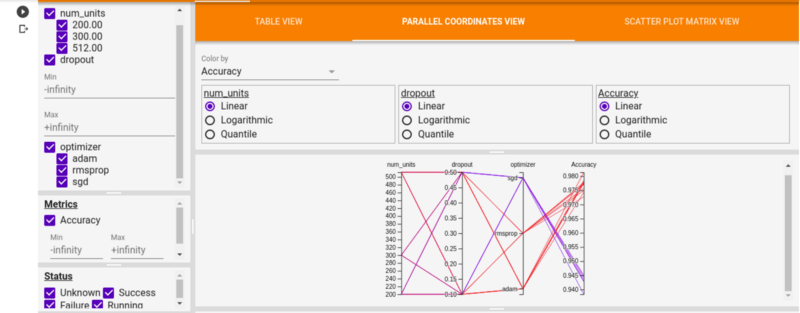
На вкладке HPARAMS в табличном представлении показаны все прогоны модели и их соответствующая точность, частота отсева и нейроны плотного слоя. В представлении «Параллельные координаты» каждый запуск отображается в виде линии, проходящей через ось для каждого гиперпараметра и показателя точности.
Щелчок по одному из них отобразит испытания и гиперпараметры, как показано ниже.
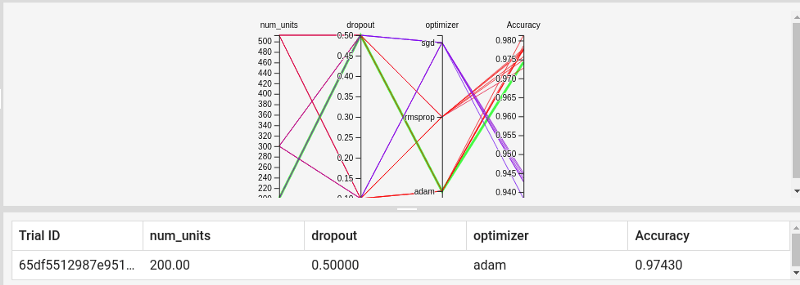
Представление точечной диаграммы визуализирует сравнение между гиперпараметрами и метриками.
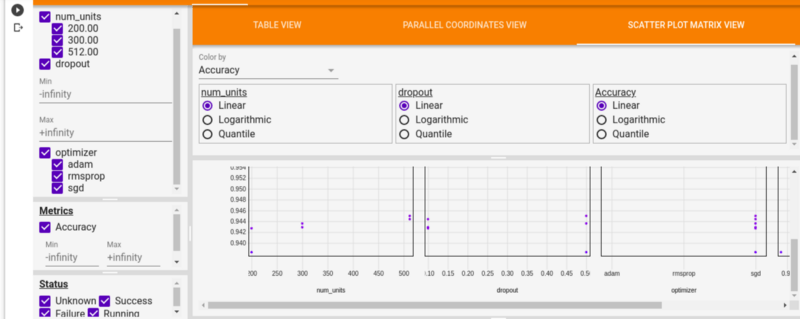
Профилировщик TensorFlow
Вы также можете отслеживать производительность моделей TensorFlow с помощью Profiler. Профилирование имеет решающее значение для понимания потребления аппаратных ресурсов операциями TensorFlow. Прежде чем вы сможете это сделать, вам нужно установить плагин профилировщика.
pip install -U tensorboard-plugin-profile
После установки он будет доступен в раскрывающемся списке «Неактивные». Вот снимок одного из многих визуальных элементов, которые можно увидеть в профилировщике.
Единственное, что вам нужно сделать сейчас, это определить обратный вызов и включить пакеты, которые будут профилированы.
После этого вы передаете обратный вызов по мере соответствия модели. Не забудьте вызвать TensorBoard, чтобы увидеть визуализации.
callbacks = [tf.keras.callbacks.TensorBoard(log_dir=log_folder,
profile_batch='10,20')]
model.fit(X_train, y_train,
epochs=10,
validation_split=0.2,
callbacks=callbacks)
%tensorboard --logdir=logs
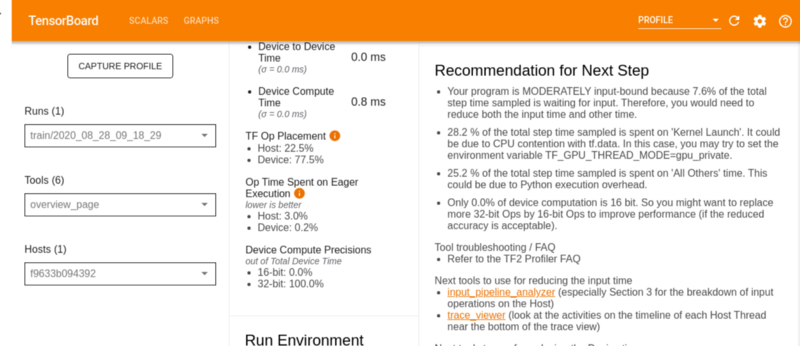
Обзорная страница
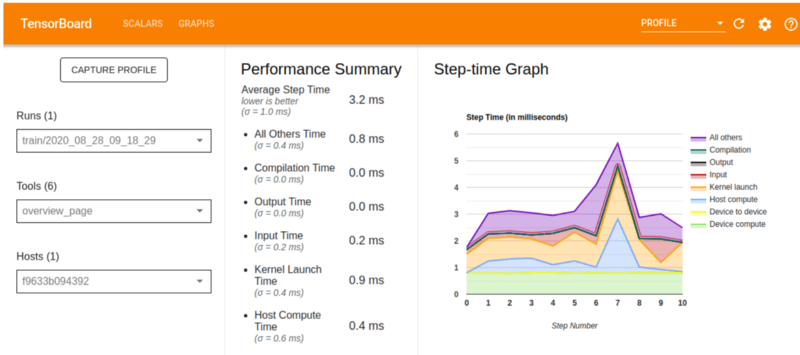
Страница «Обзор» на вкладке «Профиль» показывает общий обзор производительности модели. Как вы можете видеть на изображении ниже, сводка производительности показывает:
- время, потраченное на компиляцию ядер,
- время, потраченное на чтение данных,
- время, потраченное на запуск ядер,
- время, затраченное на производство продукции,
- время вычислений на устройстве и
- время вычислений хоста
На графике времени шага отображается время шага устройства по всем выбранным шагам. Различные цвета на графике отображают различные категории, на которые тратится время:
- красная часть соответствует времени шага, когда устройства бездействовали, ожидая ввода данных.
- В зеленой части отображается количество времени, в течение которого устройство действительно работало.
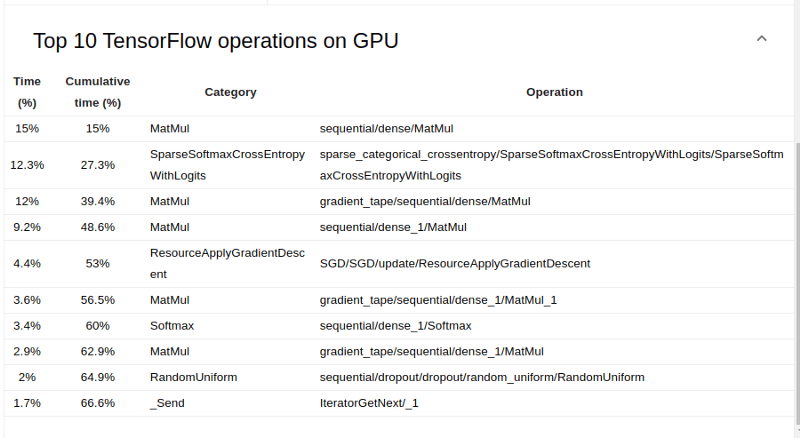
Тем не менее, на обзорной странице вы можете увидеть операции TensorFlow, выполнение которых заняло больше всего времени.
Среда выполнения показывает информацию о среде, такую как количество используемых хостов, тип устройства и количество ядер устройства. В случае, если вы видите, что во время выполнения Colab есть 1 хост с графическим процессором, содержащим 1 ядро.

Еще одна вещь, которую вы можете увидеть на этой странице, — это рекомендации по оптимизации производительности модели.
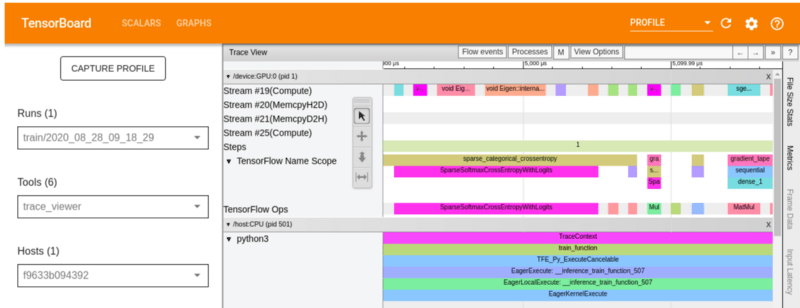
Средство просмотра трассировки
Средство просмотра трассировки можно использовать для выявления узких мест производительности во входном конвейере. Он показывает временную шкалу различных событий, произошедших с GPU или CPU в период профилирования.
По вертикальной оси показаны различные группы событий и трассировки событий по горизонтальной оси. На изображении ниже я использовал сочетание клавиш w, чтобы увеличить масштаб событий. Чтобы уменьшить масштаб, используйте сочетание клавиш S. A и D можно использовать для перемещения влево и вправо соответственно.
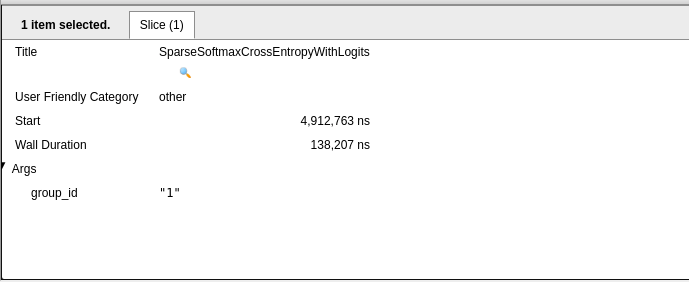
Вы можете нажать на отдельное событие, чтобы проанализировать его дальше. Используйте курсор на плавающей панели инструментов или используйте сочетание клавиш 1.
На изображении ниже показан результат анализа события SparseSoftmaxCrossEntropyWithLogits (расчет потерь на пакете данных), который показывает время начала и стенки.
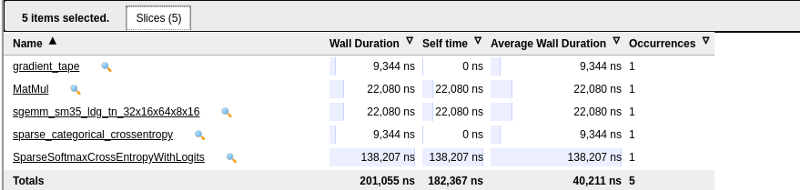
Вы также можете просмотреть сводку различных событий, удерживая клавишу Ctrl и выбирая их.
Анализатор входного конвейера
Анализатор входного конвейера можно использовать для анализа неэффективности входного конвейера вашей модели.
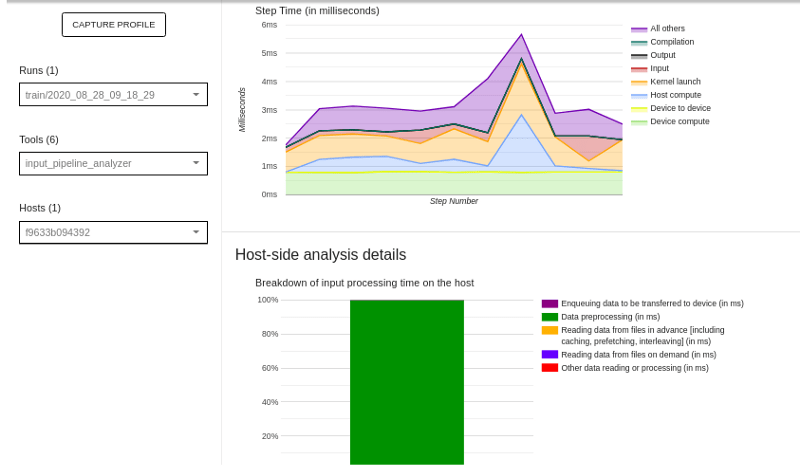

Функциональность показывает сводку анализа входного конвейера, детали анализа на стороне устройства и детали анализа на стороне хоста.
Сводка анализа входного конвейера показывает общий входной конвейер. Это часть, которая сообщает, привязано ли приложение к вводу и насколько.

Детали анализа на стороне устройства показывают время шага устройства и время, затраченное устройством на ожидание входных данных.
Анализ на стороне хоста отображает анализ на стороне хоста, например разбивку времени обработки ввода на хосте.
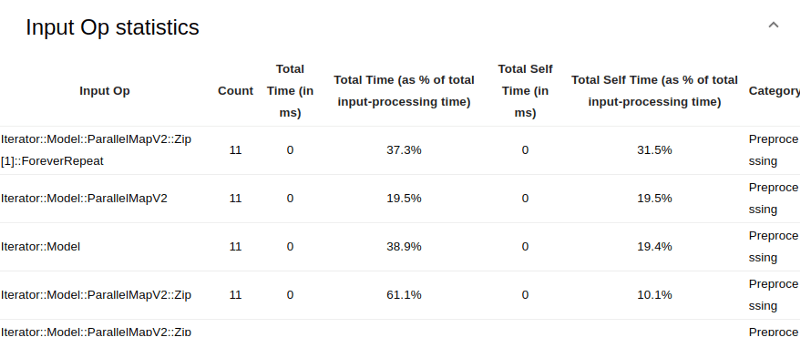
В анализаторе входных конвейеров вы также можете увидеть статистику по отдельным операциям ввода, затраченному времени и их категории. Вот что представляют различные столбцы:
- Input Op — имя операции TensorFlow для операции ввода.
- Count — количество экземпляров выполнения операции за время профилирования.
- Общее время — совокупная сумма времени, затраченного на каждый экземпляр, упомянутый выше.
- Общее время, % — общее время, затраченное на операцию, в процентах от общего времени, затраченного на обработку ввода.
- Общее время на себя — совокупная сумма времени, потраченного на себя в каждом случае.
- Общее время на себя, % — общее время на себя в процентах от общего времени, затраченного на обработку ввода.
- Категория — категория обработки операции ввода.
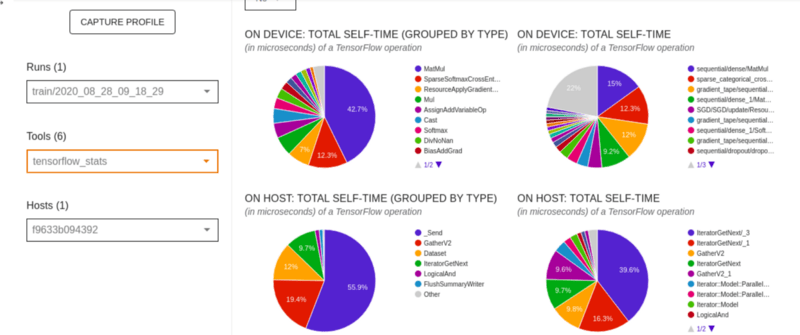
Статистика TensorFlow
Эта панель мониторинга показывает производительность каждой операции TensorFlow, выполненной на хосте.
- На первой круговой диаграмме показано распределение времени самостоятельного выполнения каждой операции на хосте.
- Второй показывает распределение времени самовыполнения для каждого типа операции на хосте.
- Третий отображает распределение времени самостоятельного выполнения каждой операции на устройстве.
- Четвертый показывает распределение времени самовыполнения по каждому типу операции на устройстве.
В таблице под круговыми диаграммами показаны операции TensorFlow. Каждая строка — это операция. Столбцы показывают различные аспекты каждой операции. Вы можете отфильтровать таблицу, используя любой из столбцов.
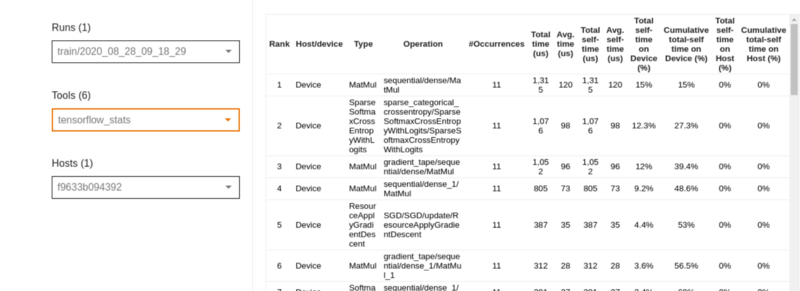
Под таблицей выше вы можете увидеть различные операции TensorFlow, сгруппированные по типу.
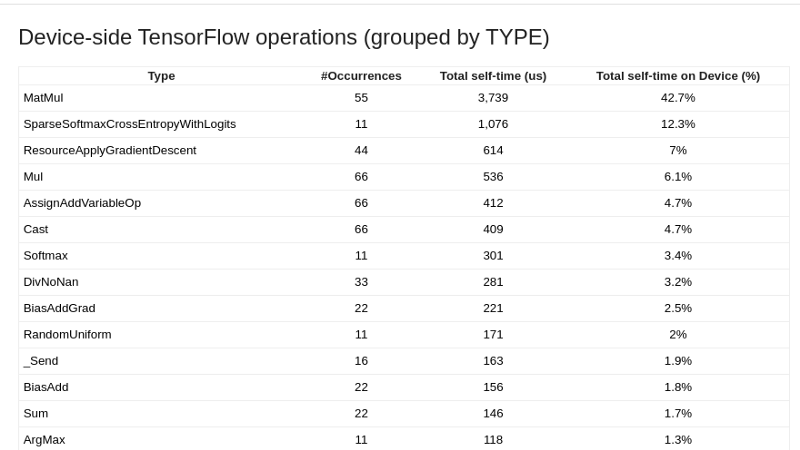
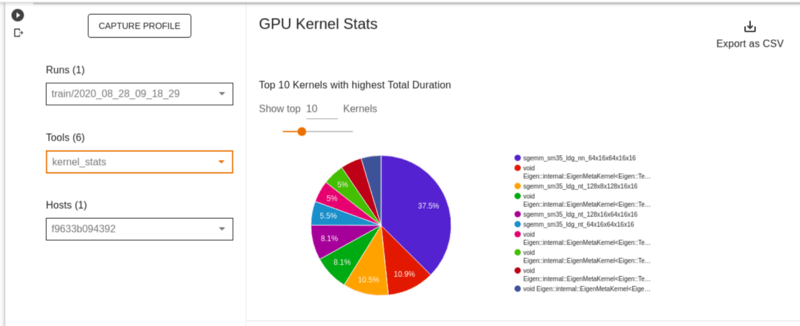
Статистика ядра графического процессора
На этой странице показана статистика производительности и исходная операция для каждого ядра с ускорением на GPU.
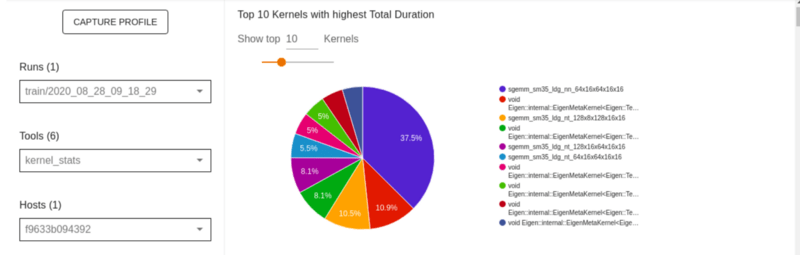
Под статистикой ядра находится таблица, которая показывает, среди прочего, ядра и время, затрачиваемое на различные операции.

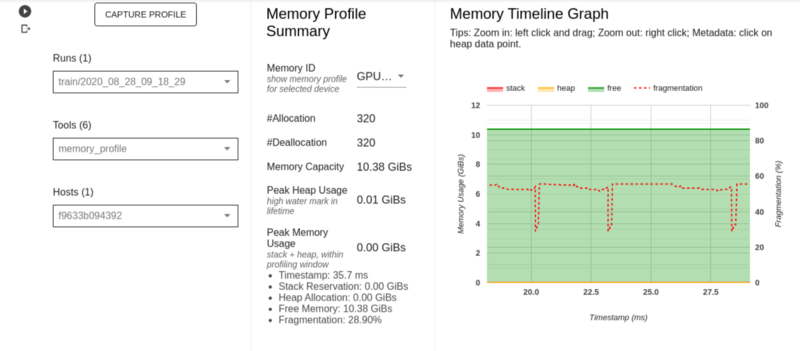
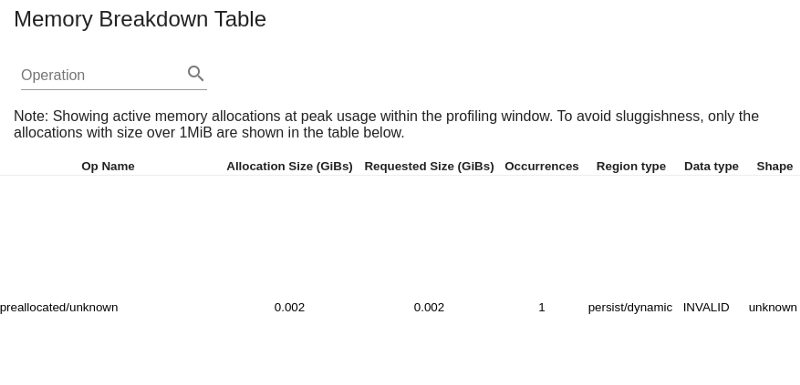
Страница профиля памяти
На этой странице показано использование памяти в период профилирования. Он имеет следующие разделы; Сводка профиля памяти, график временной шкалы памяти и таблица разбивки памяти.
- Сводка профиля памяти показывает сводку профиля памяти приложения TensorFlow.
- График временной шкалы памяти показывает график использования памяти в гигабайтах и процент фрагментации в зависимости от времени в миллисекундах. То
- Таблица разбивки памяти отображает активное выделение памяти в точке максимального использования памяти в интервале профилирования.
Как включить отладку на TensorBoard
Вы также можете сбросить отладочную информацию на свой TensorBoard. Для этого вам нужно включить отладку — она все еще находится в экспериментальном режиме.
tf.debugging.experimental.enable_dump_debug_info( logdir, tensor_debug_mode="FULL_HEALTH", circular_buffer_size=-1)
Информационную панель можно просмотреть в Debugger V2 в раскрывающемся списке Неактивно.
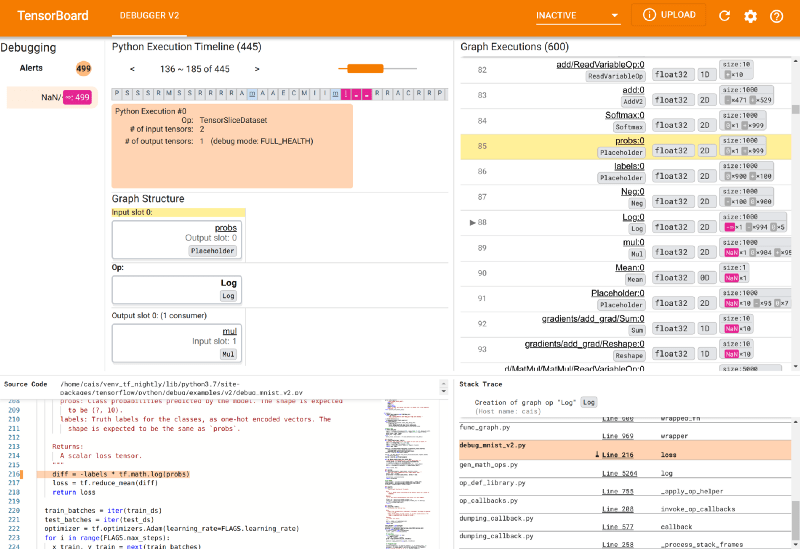
В графическом интерфейсе Debugger V2 есть оповещения, временная шкала выполнения Python, выполнение графика и структура графика. Раздел «Предупреждения» показывает аномалии вашей программы. В разделе «Временная шкала выполнения Python» показана история активного выполнения операций и графики.
Выполнение графа отображает историю всех тензоров с плавающим типом, которые были вычислены внутри графов. Раздел «Структура графика» содержит исходный код и трассировку стека, которые заполняются при взаимодействии с графическим интерфейсом.
Использование TensorBoard с фреймворками глубокого обучения
Вы не ограничены использованием TensorBoard только с TensorFlow. Вы также можете использовать его с другими фреймворками, такими как Keras, PyTorch и XGBoost, и это лишь некоторые из них.
TensorBoard в PyTorch
Вы начинаете с определения записывающего устройства, указывая на папку, в которую вы хотите записывать журналы.
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter(log_dir='logs')
Следующим шагом будет добавление элементов, которые вы хотели бы видеть на TensorBoard, с помощью средства записи резюме.
from torch.utils.tensorboard import SummaryWriter
import numpy as np
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
TensorBoard в Керасе
Поскольку TensorFlow использует Keras в качестве официального API высокого уровня, реализация TensorBoard аналогична его реализации в TensorFlow. Мы уже видели, как это сделать:
Создайте обратный вызов:
from tensorflow.keras.callbacks import TensorBoard tb_callback = TensorBoard(log_dir=log_folder,...)
Передайте его в `model.fit`:
model.fit(X_train, y_train,
epochs=10,
validation_split=0.2,
callbacks=[tb_callback])
TensorBoard в XGBoost
При работе с XGBoost вы также можете регистрировать события в TensorBoard. Для этого необходим пакет tensorboardX. Например, для регистрации метрик и потерь вы можете использовать `SummaryWriter` и регистрировать скаляры.
from tensorboardX import SummaryWriter
def TensorBoardCallback():
writer = SummaryWriter()
def callback(env):
for k, v in env.evaluation_result_list:
writer.add_scalar(k, v, env.iteration)
return callback
xgb.train(callbacks=[TensorBoardCallback()])
Tensorboard.dev
Tensorboard.dev — это управляемая платформа TensorBoard, которая упрощает размещение, отслеживание и совместное использование экспериментов по машинному обучению. Это позволяет публиковать свои эксперименты с TensorBoard, устранять неполадки, а также сотрудничать с членами команды. Если у вас есть эксперимент с TensorBoard, загрузить его на TensorBoard.dev довольно просто.
tensorboard dev upload --logdir logs \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters"
После запуска этой команды вы получите запрос на авторизацию TensorBoard.dev с помощью вашей учетной записи Google. Как только вы это сделаете, вы получите проверочный код, который нужно будет ввести для аутентификации.
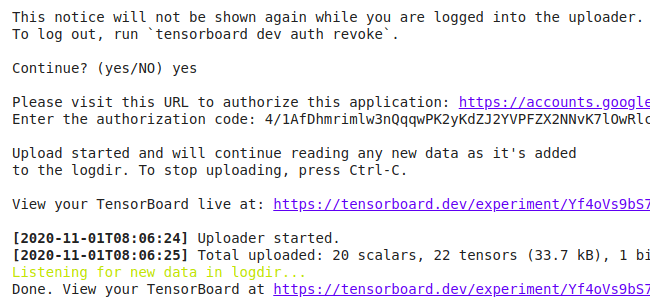
Это создаст для вас уникальную ссылку TensorBoard.Dev. Вот пример такой ссылки. Как видите, это очень похоже на просмотр TensorBoard на локальном хосте, только теперь вы просматриваете его онлайн.
Как только вы приземлитесь здесь, вы сможете взаимодействовать с TensorBoard так же, как и в предыдущих частях этой статьи.
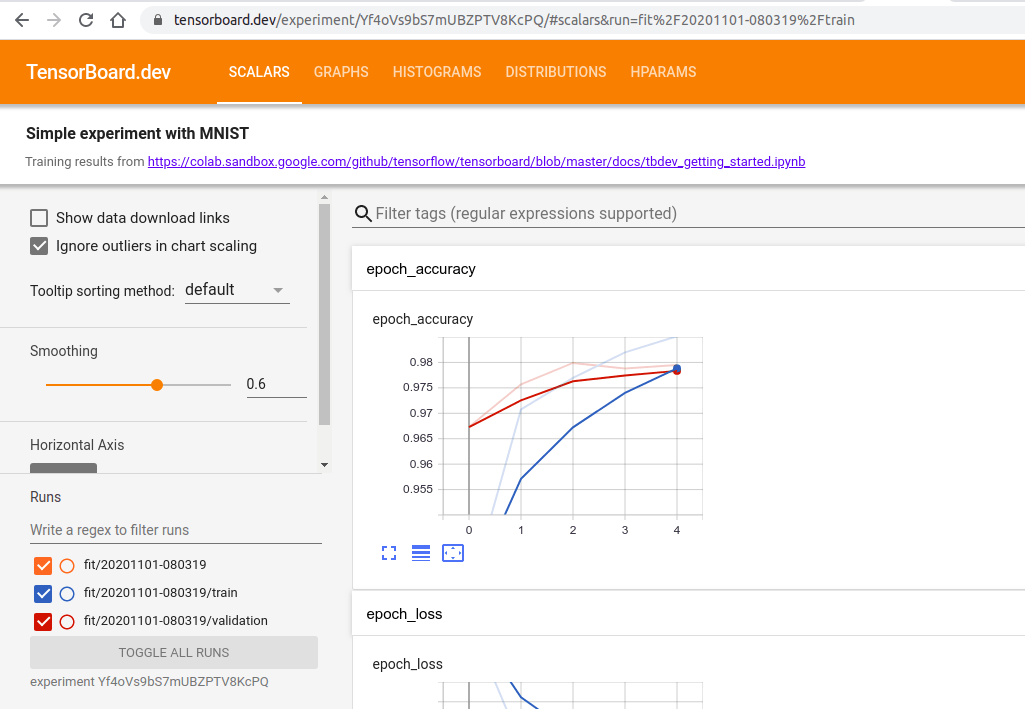
Важно отметить, что этот TensorBoard будет виден всем в Интернете, поэтому убедитесь, что вы не загружаете какие-либо конфиденциальные данные.
Ограничения использования TensorBoard
Как вы видели, TensorBoard дает вам множество замечательных функций. Тем не менее, использование TensorBoard не все так радужно.
Для него есть некоторые ограничения:
- трудно использовать в командной обстановке, где требуется сотрудничество
- отсутствует управление пользователями и рабочими пространствами: функции, которые часто требуются в крупных организациях
- вы не можете выполнять управление версиями данных и моделей, чтобы отслеживать различные эксперименты
- нельзя масштабировать до миллионов прогонов; вы начнете получать проблемы с пользовательским интерфейсом при слишком большом количестве запусков
- интерфейс для регистрации изображений немного неуклюж
- вы не можете регистрировать и визуализировать другие форматы данных, такие как аудио/видео или пользовательский HTML
Последние мысли
Есть несколько вещей, которые мы не рассмотрели в этой статье. Стоит упомянуть две интересные особенности:
- Панель Индикаторы честности (в настоящее время в бета-версии). Это позволяет вычислять показатели справедливости для бинарных и многоклассовых классификаторов.
- Инструмент Что, если (WIT) позволяет изучать и исследовать обученные модели машинного обучения. Это делается с помощью визуального интерфейса, который не требует никакого кода.
Надеемся, что со всем, что вы узнали здесь, вы сможете отслеживать и отлаживать свои тренировочные прогоны и в конечном итоге создавать лучшие модели!
Дальнейшее чтение:
- Наиболее используемые инструменты, фреймворки и библиотеки в индустрии машинного обучения (обзор)
- TensorBoard против Neptune: чем они НА САМОМ ДЕЛЕ отличаются
Эта статья изначально была написана Дерриком Мвити и размещена в блоге Neptune (в нем есть несколько видеороликов, так что не забудьте проверить). Там вы можете найти более подробные статьи для специалистов по машинному обучению.