ПЕРЕДАЧА ОБУЧЕНИЯ
Получите точную настройку прямо сейчас
Для задач NTCIR-15 FinNum-2 и DialEval-1
Заявление об ограничении ответственности: в этом сообщении не используются авторские или редакционные мы . Самоуверенное название и содержание самоуверенны. Описанная здесь работа является коллективной работой, но мои слова не выражают точку зрения моего работодателя и соавторов.
14 декабря 2020 года успешно завершилась конференция НТКИР-15. Я руководил двумя командами, которые работали над общей задачей конференции, а именно DialEval-1 и FinNum-2. Работы моих команд заняли первое и второе места в DialEval-1 и FinNum-2 соответственно. После моего предыдущего поста, в котором представлены NTCIR и DialEval, в этом будет описываться, что такое FinNum-2, сообщаться о вкладе работы команды и предлагаться рабочий процесс, который обобщает, как я применяю трансферное обучение для таких задач, как DialEval и FinNum.
Дорога так далеко
Поскольку я работаю инженером по NLP-ML в ZEALS, решение практических вопросов, связанных с трансфертным обучением, является частью моей должностной инструкции. Несмотря на все внимание к Transformers и BERTology, точная настройка этих моделей все еще нетривиальна, и некоторые перспективы точной настройки менее изучены, чем другие. В этом посте мы будем использовать DialEval-1 и FinNum-2 в качестве примеров, чтобы показать, что это за недоинвестированные темы. (Если это какая-то необъяснимая аббревиатура, пожалуйста, обратитесь к предыдущему посту.)
FinNum - это задача для точного понимания чисел в финансовых текстах онлайн. Что касается твитов о цене акций, FinNum-1 в NTCIR-14 попытался устранить неоднозначность значений цифр и нашел его недостаточным для прагматического использования, так что FinNum-2 в NTCIR-15 хочет определить связь между кэштегами. и цифры. На рисунке 1 показан пример связи.

Хотя есть несколько способов сделать это, организаторы FinNum-2 формулируют задачу как проблему бинарной классификации. Хотя DialEval-1 не применяет конкретную схему для своих подзадач ND и DQ, все участники моделируют их как классификацию по нескольким классам и классификацию по нескольким меткам соответственно. Таким образом, эти две задачи дают возможность изучить один общий и практический подход с различными настройками классификации и наборами данных, по крайней мере, так я их вижу.
Дьявольская сделка
Объявление чего-то общего и практического может быть субъективным, поэтому позвольте мне процитировать официальные отчеты о фактических результатах моих команд IMTKU и CYUT *. (Подробную статистику смотрите в статьях организаторов задания: ДиалЕва-1, ФинНум-2.)
Для DialEval-1:
В STC-3 ни один из прогонов участников не был статистически значимо лучше, чем модель BL-LSTM. Однако в DialEval-1 IMTKU-run2 значительно (0,5) превосходит базовые показатели в китайской подзадаче DQ с точки зрения NMD.
Для FinNum-2:
(CYUT) эксперимент на BERT и RoBERTa. … Мы обнаружили, что ванильные BERT и RoBERTa обладают хорошими характеристиками.
(На самом деле это XLM-RoBERTa, и я скоро объясню разницу.)
Все это звучит хорошо, за исключением того, что я торгую временем и энергией с большими, плохо подготовленными моделями. Если применять их вслепую, способность этих моделей к обобщению может разочаровать, не говоря уже о том, что «практический» иногда подразумевает особые подходы, которые не подходят для новых задач. Итак, я полагаю, по крайней мере, повторяемая процедура может быть базовой линией, которую я могу улучшить.
Я писатель
Некоторые могут посчитать это очевидным: чем больше модель, тем лучше производительность, не так ли? Однако, как отмечают организаторы FinNum-2,
«Разница в производительности разных команд, использующих одну и ту же архитектуру, может быть вызвана процедурами предварительной обработки и настройками гиперпараметров».
По моему опыту, помимо предварительной обработки и гиперпараметров есть еще несколько факторов. На диаграмме ниже показан процесс моего решения.
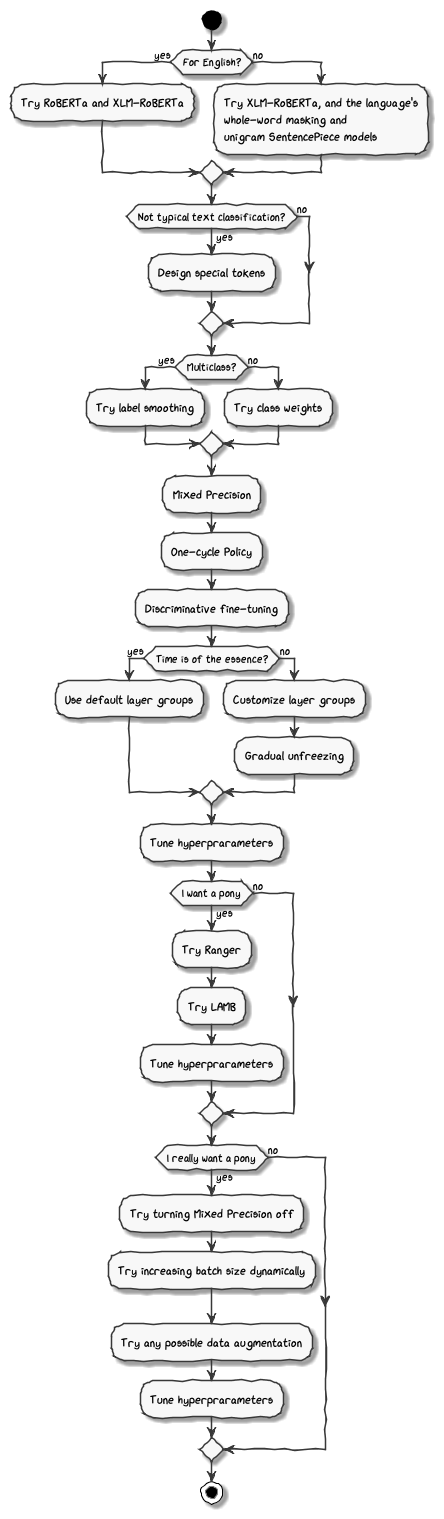
Здесь я хотел бы подчеркнуть тонкие различия между токенизаторами. Например, XLM-RoBERTa использует униграмму SentencePiece, тогда как RoBERTa использует кодирование пар байтов (BPE). Грубо говоря, BPE рекурсивно связывает байты слева направо. Для некоторых языков результирующие подслова могут быть не идеальными. При этом, поскольку разные модели предопределяют свои собственные токенизации с вариациями наборов обучающих данных и схем обучения, я не знаю универсального ответа. Опытным путем я обнаружил, что модели, основанные на униграмме SentencePiece и маскировке всего слова, с большей вероятностью будут превосходить модели на основе WordPiece и BPE.
По общему признанию, этот процесс не идеален. Например, я обнаружил интригующий случай ошибки «2С»:
В тестовом наборе твит использует [it] для обозначения связи между глобальным потеплением и курсом акций Tesla. Однако в обучающих и развивающих наборах все «2C» и «2c» означают «видеть». Этот случай показывает, что как неформальное использование твита, так и знание предметной области акций могут потребовать дополнительных усилий.
Поможет ли полировка остальных шагов на приведенной выше диаграмме решить эту проблему? Я еще не знаю, но мне хотелось бы думать, что увеличение объема данных многообещающе. Что касается ключевых слов этих шагов, я просто объединю здесь список с гиперссылками для вашей справки:
- BPE, WordPiece и SentencePiece
- Маскировка всего слова
- Когда помогает Label Smoothin g?
- Смешанная точность
- Политика одного цикла
- Дискриминационная тонкая настройка / Постепенное размораживание
- Группы слоев По умолчанию и Пользовательский.
- Рейнджер; "ЯГНЕНОК"
- Не снижайте скорость обучения, увеличивайте размер партии.
- Дополнения к текстовым данным: EDA, nlpaug, TextAttack и др.

Продолжать
Еще одна вещь, о которой, возможно, стоит упомянуть, это то, что с помощью политики одного цикла мне удалось точно настроить модели для DialEval-1 и FinNum-2 с меньшим количеством эпох, чем в других командах. Например, мне нужно всего 5 эпох для FinNum-2, в то время как другим обычно требуется 30. Это не только приносит мне пользу за счет экономии времени, но и меньшее потребление энергии может также внести небольшой вклад в мир. Недавний спор напомнил мне, что стремление к трансферному обучению происходит за счет окружающей среды. Честно говоря, я не знаю, действительно ли моя попытка найти более эффективные способы переноса обучения может иметь значение, но это, безусловно, заставляет меня чувствовать себя менее виноватым. Интересно, что некоторые попытки машинного обучения могут также косвенно способствовать общему благу. Например, чтобы выйти за рамки смешанной точности, модели обучения с 4-битным чипом могут высвободить личные данные из облака, а затем персонализированные и объединенные модели могут расширить возможности большего числа недостаточно представленных людей.
* Обычно почти все участники NTCIR называют команды по колледжам, независимо от отрасли, даже если я являюсь первым автором от имени своей компании.