Введение
В недавнем прошлом был отмечен рост использования твиттера в качестве платформы социальных сетей, где люди делятся мнениями о различных сферах жизни. По состоянию на май 2020 года среднее количество твитов, отправляемых в минуту, составляет около 350000. В этом блоге мы предлагаем методику классификации тональности текста с использованием частотности терминов в тексте документа (TF-IDF) и сравниваем различные модели классификации при обучении на разных встраиваемых словах Word2Vec и предварительно обученной Glove.
Набор данных
Используемый набор данных - это набор данных Sentiment140 с 1,6 млн твитов из набора данных Sentiment140 с 1,6 млн твитов | Kaggle
Он содержит 1 600 000 твитов, извлеченных с помощью twitter api. Твиты имеют аннотацию (0 = отрицательный, 1 = положительный), и их можно использовать для определения настроений.


Подход 1. Извлечение функций с помощью Word2Vec:
Word2Vec создает распределенные числовые представления функций слова, например контекста отдельных слов.
Модели машинного обучения:
Различные модели машинного обучения обучаются на функциях, извлеченных Word2vec. Точность XGBClassifier оказалась лучше, чем у других моделей машинного обучения, как показано в таблице ниже.
Модели глубокого обучения:
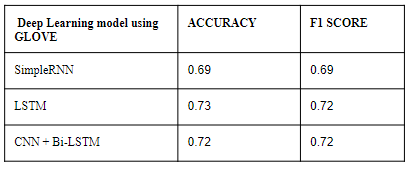
Различные модели нейронных сетей обучены функции, извлеченной Word2vec. Точность CNN + двунаправленного LSTM составила 0,76, что лучше, чем у других классических моделей машинного обучения.

Подход 2 - извлечение признаков с помощью Tf-idf:
Использование униграммы: основная рассматриваемая функция заключалась в использовании униграммы, которая учитывала одно слово за раз для создания вектора признаков.
Использование биграммы. Биграмма - это последовательность двух слов. Таким образом, вектор tf-idf строится с использованием двух слов для создания вектора признаков.
Использование униграммы и биграммы: в этом подходе и униграммы, и биграммы используются для построения вектора tf-idf, а затем модель обучается на этом векторе.
Сравнение приведенных выше вариантов. Обучающие модели с использованием функций униграммы и биграммы вместе работали лучше, чем обучение только функциям униграммы или биграммы. Точность SVM и логистической регрессии на тестовой выборке составила 0,79.

Подход 3. Извлечение признаков с помощью предварительно обученного GloVe:
GloVe означает глобальные векторы для представления слов. Это альтернативный метод для встраивания слов.
Сравнение модели, обученной встраиванию слов Word2Vec и GloVe: Word2Vec работает лучше, чем предварительно обученное встраивание слов GloVe в модели нейронной сети. CNN + двунаправленный LSTM достиг точности 0,76 при извлечении функции Word2Vec.
Сравнение точности разных моделей
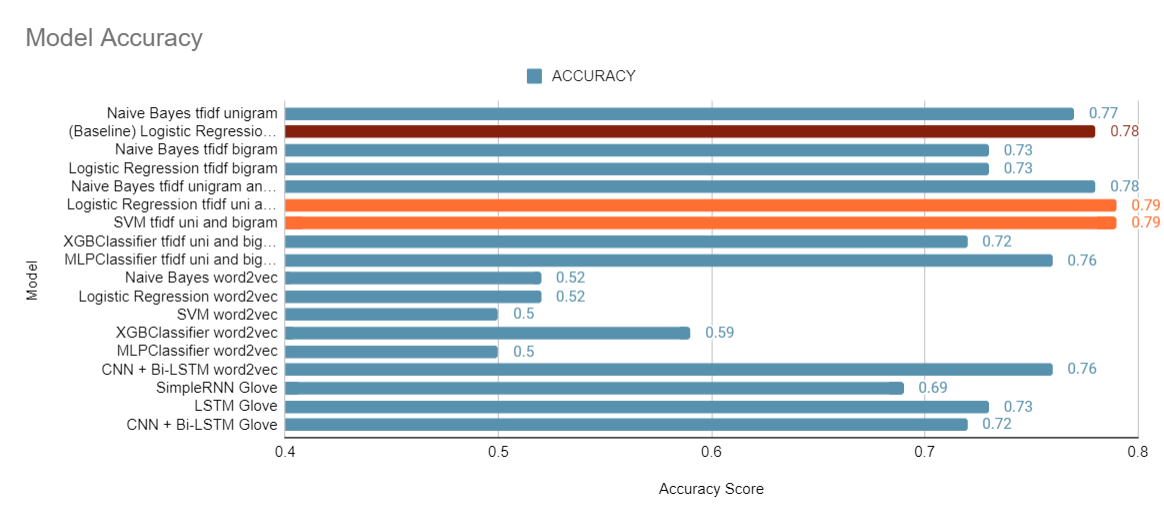

Базовая модель Логистическая регрессия, обученная на извлеченных функциях tf-idf с использованием ngram в качестве униграммы, окрашена в коричневый цвет, а полосы, окрашенные в оранжевый цвет, являются лучшей моделью с точностью 0,79, которая была достигнута для извлеченных функций tf-idf, когда ngram был установлен на униграмму и биграмму вместе.
Заключение
Поскольку это задача классификации, мы реализовали линейный SVC и логистическую регрессию, модели Naïve Bayes, MLP, XGB и нейронные сети. Различная реализация вектора tf-idf в n-граммах помогла нам проанализировать различия подходов униграммы, биграммы и униграммы + биграммы. Сами по себе униграмма и биграмма дают разумную точность, но модель униграмма + биграмма достигла наилучшей точности 79%. Реализация Word2Vec дает лучший результат для нейронных сетей, чем традиционные классификаторы машинного обучения, такие как Naïve Bayes и Logistic Regression. Модель достигла 76% точности в модели CNN + bi-LSTM. Модель, обученная встраиванию слов GloVe, достигла 73% максимальной точности при подаче в рекуррентную нейронную сеть LSTM.
Таким образом, мы приходим к выводу, что мы видим, что реализация tf-idf unigram + bigram для логистической регрессии и SVM показала лучшие результаты среди других моделей, которые мы обучили. Точность, достигаемая реализацией tf-idf unigram + bigram для логистической регрессии и SVM, составляет 79%.
Авторы блогов и их вклад
Рахул Гупта ( linkedin.com/in/rahul-gupta-68700a114): функции, извлеченные с помощью Word2Vec, и обученная традиционная модель машинного обучения, которая включает наивный байесовский метод, SVM, логистическую регрессию, XGBClassifier и MLP. Извлеченные функции с использованием предварительно обученной модели GloVe и рекуррентной нейронной сети, обученной этим функциям, включают SimpleRNN, LSTM и двунаправленный LSTM CNN.
Анджали (linkedin.com/in/anjali-b3169a1ab): предварительная обработка текста, которая включает удаление пользовательских ссылок, преобразование смайлов в соответствующие настроения, удаление любых гиперссылок, если таковые имеются. Извлеченные функции с использованием векторизатора Tf-idf и обучение модели традиционного машинного обучения, которая включает наивный байесовский метод, SVM, логистическую регрессию, XGBClassifier и MLP.
Под руководством
- Профессор: Танмой Чакраборти (linkedin.com/in/tanmoy-chakraborty-89553324)
- Сайт профессора: faculty.iiitd.ac.in/~tanmoy/
- Учитель: Ишита Баджадж
- Помощники учителя: Шив Кумар Гехлот, Вивек Редди, Прагья Шривастава, Чхави Джайн, Шикха Сингх и Нирав Диван.
Использованная литература:
[1] Биджоян Дас, Сарит Чакраборти. Улучшенная модель классификации тональности текста с использованием TF-IDF и отрицания следующего слова. Студент-член IEEE.
[2] М. Ракибул Хасан, Майша Малиха, М. Арифуззаман. Анализ настроений с НЛП в Twitter Данные Компьютерная коммуникация Химические материалы и электронная инженерия (IC4ME2) Международная конференция 2019, стр. 1–4, 2019.
[3] Эдилсон А. Корреа младший, Ванесса Кейруш Мариньо, Леандро Борхес душ Сантуш. NILC-USP на SemEval-2017 Задача 4: Многовидовой ансамбль для анализа настроений в Twitter Институт математики и компьютерных наук Университета Сан-Паулу (USP) Сао-Карлос, Сан-Паулу, Бразилия.
[4] Хуан Рамос. «Использование TF-IDF для определения релевантности слов в запросах документов» стр. 1–4.
[5] Эндрю Л. Маас, Рэймонд Э., Дейли, Питер Т. Фам, Дэн Хуанг, Эндрю Й. Нг и Кристофер Поттс. «Изучение векторов слов для определения настроений» (2011 г.).
[6] Майкл Вейганд, Александра Балахур, Бенджамин Рот, Дитрих Клаков, Андрес Монтойо. «Роль отрицания в опросе при анализе настроений», стр. 1–9.