В последние годы в области глубокого обучения произошел беспрецедентный прогресс, вызванный желанием имитировать сложную работу человеческого мозга. По своей сути глубокое обучение направлено на воспроизведение способности мозга обрабатывать информацию из различных источников и получать значимые идеи. Это глубокое вдохновение привело к разработке новых архитектур, которые не только позволяют решать сложные задачи, но и раскрывают более глубокие уровни представления данных. В результате архитектуры имеют решающее значение для нас не только потому, что многие задачи зависят от задач, которые мы можем с их помощью выполнить. Фактически, сама конструкция сетей указывает нам на представление, которое исследователи искали, чтобы лучше учиться на данных. .
Ленет
Новаторская работа
Прежде чем начать, отметим, что мы не добились бы успеха, если бы просто использовали необработанный многослойный перцептрон, подключенный к каждому пикселю изображения. Помимо того, что эта прямая операция быстро становится трудновыполнимой, она не очень эффективна, поскольку пиксели пространственно коррелированы.
Поэтому сначала нам необходимо извлечь
- значимый и
- низкоразмерные функции, над которыми мы можем работать.
И вот здесь в игру вступают сверточные нейронные сети!
Чтобы решить эту проблему, идея Янна Ле Куна состоит из нескольких этапов.
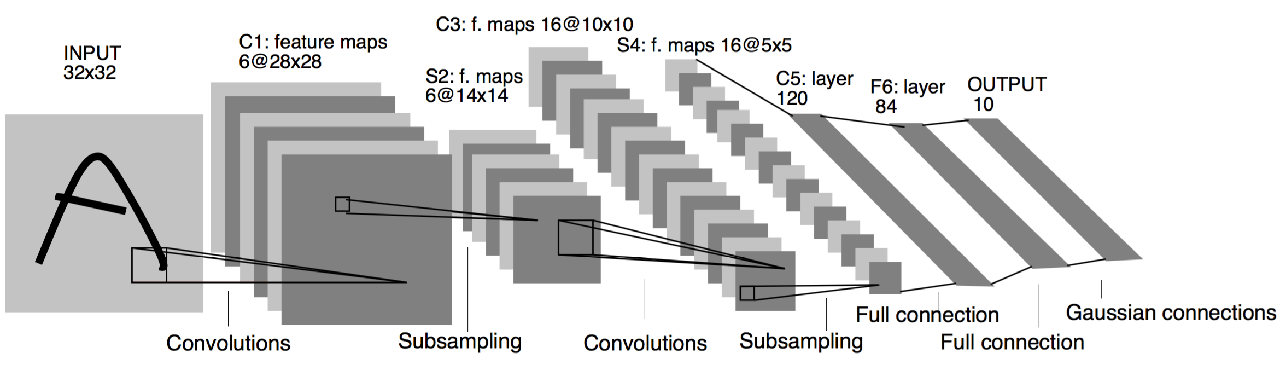
Как замечено, размеры функций постепенно уменьшаются в сетевой архитектуре. В конечном итоге эти усовершенствованные функции высокого уровня сглаживаются и передаются в полностью связанные слои. Эти слои, в свою очередь, генерируют вероятности для разных классов через слой softmax.
На этапе обучения сеть приобретает способность различать отличительные особенности, которые относят конкретную выборку к определенной категории. Этот процесс обучения облегчается за счет обратного распространения ошибки, когда сеть корректирует свои внутренние параметры на основе различий между прогнозируемыми и фактическими результатами.
Чтобы проиллюстрировать эту концепцию, рассмотрим изображение лошади. Первоначально фильтры сети могут концентрироваться на общем контуре животного. По мере того, как сеть углубляется, она переходит на более высокий уровень абстракции, позволяя инкапсулировать более мелкие детали, такие как глаза и уши лошади.
По сути, сверточные нейронные сети (ConvNets) служат механизмом для создания функций, которые в отсутствие такой архитектуры потребовали бы ручной разработки. Это подчеркивает возможности ConvNets в автоматизации процесса извлечения признаков, тем самым производя революцию в сфере глубокого обучения.
АлексНет
Подъем Convolution к славе
Естественно, можно задаться вопросом, почему сверточные нейронные сети (ConvNets) не приобрели широкой популярности до 1998 года. Краткий ответ на этот вопрос заключается в том, что их полные возможности не использовали весь свой потенциал обратно.
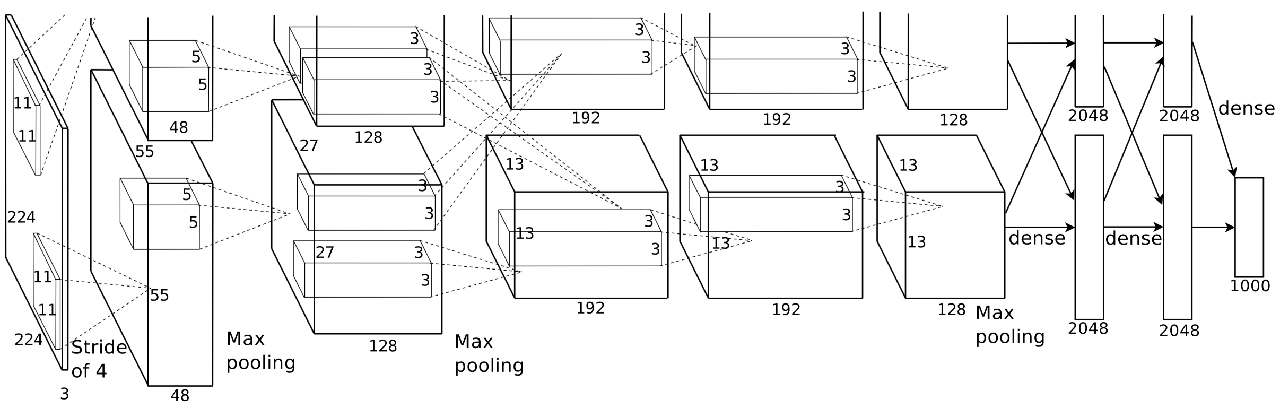
Здесь AlexNet использует тот же нисходящий подход, при котором последовательные фильтры предназначены для улавливания все более и более тонких функций. Но здесь в его работе было изучено несколько важных деталей.
- Во-первых, Крижевский ввел лучшую нелинейность в сети с активацией ReLU, производная которой равна 0, если функция ниже 0 и 1 для положительных значений. Это оказалось эффективным для распространения градиента.
- Во-вторых, в его статье была представлена концепция отсева как регуляризации. С точки зрения представления вы заставляете сеть забывать вещи в случайном порядке, чтобы она могла увидеть ваши следующие входные данные с лучшей точки зрения.
Просто приведу пример: после того, как вы закончите читать этот пост, вы, скорее всего, забудете некоторые его части. И все же это нормально, потому что вы будете помнить только о том, что важно.
Ну, надеюсь. То же самое происходит и с нейронными сетями, что делает модель более надежной.
3. Кроме того, было введено дополнение данных. При подаче в сеть изображения показываются со случайным переводом, поворотом, обрезкой. Таким образом, сеть будет лучше осведомлена об атрибутах изображений, а не о самих изображениях.
Наконец, еще один трюк, используемый AlexNet, — это быть глубже. Здесь вы можете видеть, что перед объединением операций в пул они собрали больше сверточных слоев. Представление последовательно отражает более мелкие характеристики, которые оказываются полезными для классификации.
Эта сеть во многом превзошла то, что было самым современным в 2012 году, с ошибкой топ-5 в наборе данных ImageNet на 15,4%.
ВГГНет
Чем глубже, тем лучше
Следующей важной вехой в классификации изображений стало дальнейшее изучение последнего пункта, о котором я упомянул: углубление.
И это работает. Это говорит о том, что такие сети могут обеспечить лучшее иерархическое представление визуальных данных с большим количеством слоев.
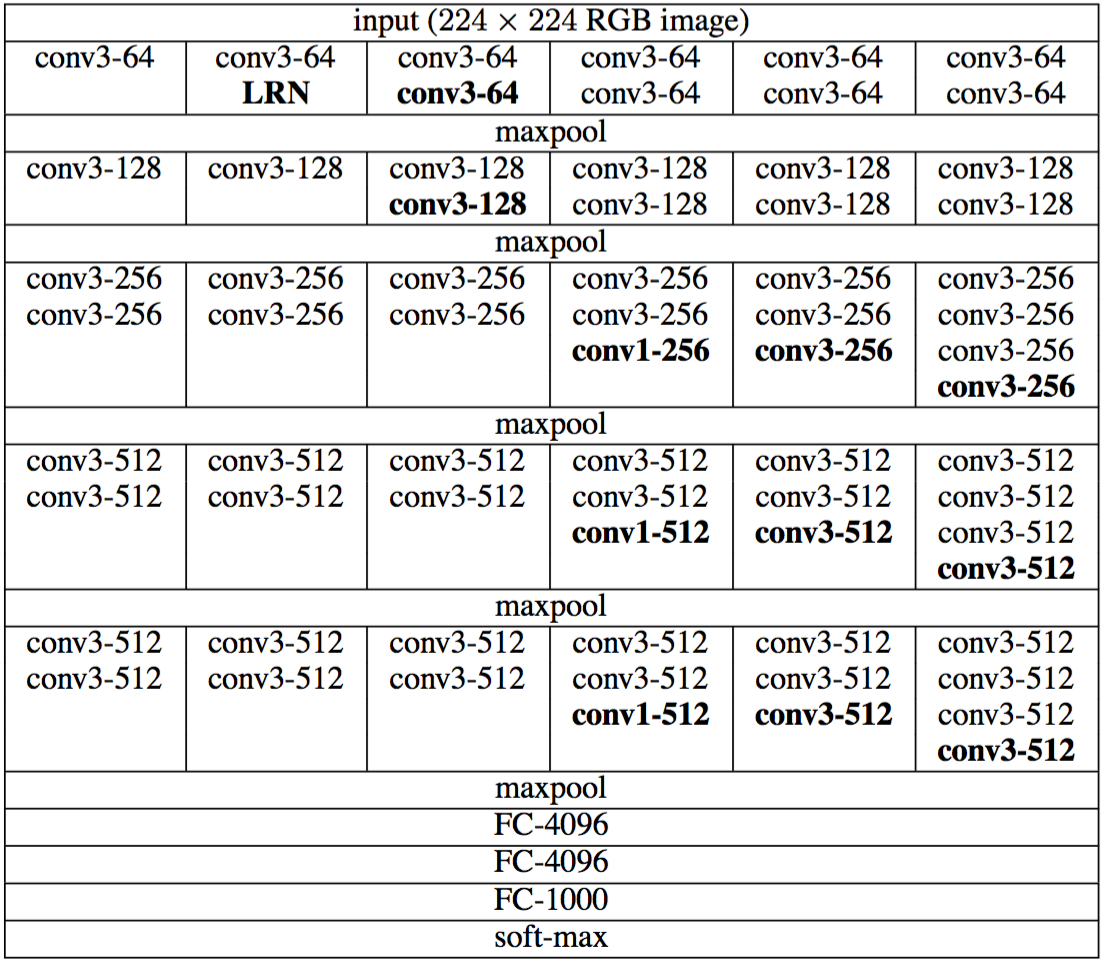
Как видите, в этой сети есть еще кое-что особенное. Он содержит почти исключительно свертки 3 на 3. Это любопытно, не так ли?
Фактически, авторы руководствовались тремя основными причинами сделать это:
- Во-первых, использование небольших фильтров приводит к большей нелинейности, что означает больше степеней свободы для сети.
- Во-вторых, факт составления этих уровней вместе позволяет сети видеть больше вещей, чем кажется. Например, при наличии двух из них сеть фактически видит рецептивное поле размером 5x5. И когда вы объединяете 3 таких фильтра, у вас фактически получается рецептивное поле 7х7! Таким образом, в этой архитектуре могут быть достигнуты те же возможности извлечения признаков, что и в предыдущих примерах.
- В-третьих, использование только небольших фильтров также ограничивает количество параметров, что хорошо, если вы хотите углубиться в суть вопроса.
Количественно говоря, эта архитектура достигла 7,3% ошибок в топ-5 на ImageNet.
ГуглЛеНет
Время для начала
Затем в игру вступил GoogLeNet. Его успех основан на начальных модулях.
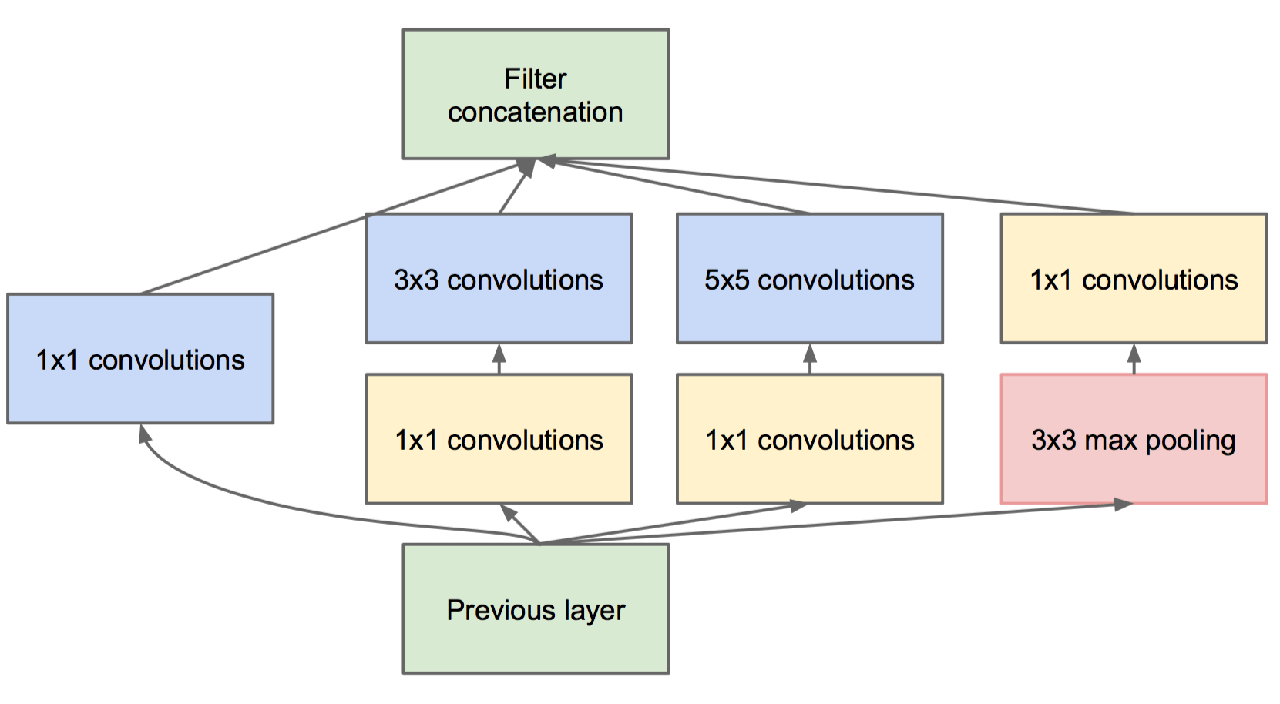
Как видите, свертки с фильтрами разных размеров обрабатываются на одном и том же входе, а затем объединяются вместе.
С точки зрения представления это позволяет модели использовать преимущества многоуровневого извлечения признаков на каждом этапе. Например, общие функции могут быть извлечены с помощью фильтров 5x5, в то время как дополнительные локальные функции могут быть извлечены с помощью сверток 3x3.
Но тогда ты мог бы сказать мне. Ну вот и отлично. Но разве это не безумно дорого для вычислений?
И я бы сказал: очень хорошее замечание! На самом деле у команды Google было блестящее решение для этой проблемы: свертки 1x1.
- С одной стороны, это уменьшает размерность ваших функций.
- С другой стороны, он объединяет карты объектов таким образом, что это может быть выгодно с точки зрения представления.
Тогда вы могли бы спросить, почему это называется начало? Что ж, вы можете рассматривать все эти модули как сети, наложенные друг на друга внутри более крупной сети.
И, к сведению, лучший ансамбль GoogLeNet достиг ошибки 6,7% на ImageNet.
РесНет
Соедините слои
Итак, все эти сети, о которых мы говорили ранее, следовали одной и той же тенденции: углубляться. Но в какой-то момент мы понимаем, что объединение большего количества слоев не приводит к повышению производительности. На самом деле происходит прямо противоположное. Но почему?
Одним словом: градиент, дамы и господа.
Но не волнуйтесь, исследователи нашли способ противостоять этому эффекту. Здесь ключевой концепцией, разработанной ResNet, является остаточное обучение.
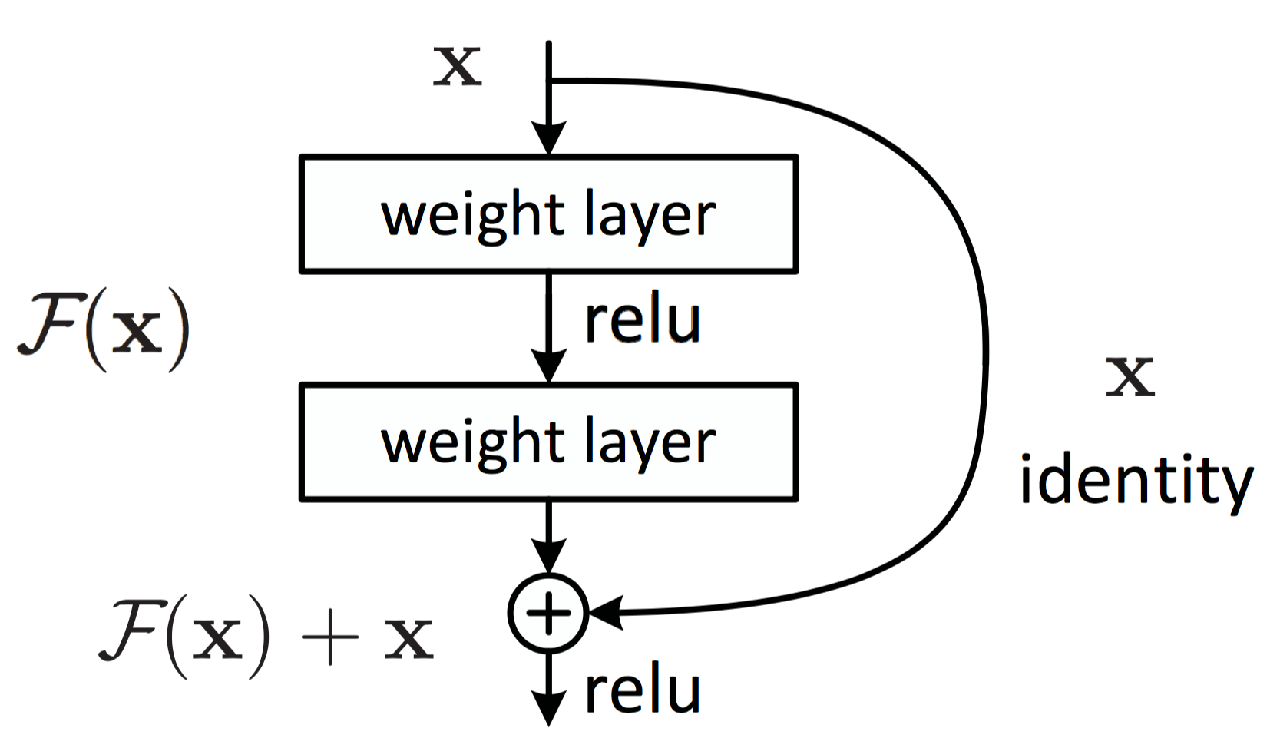
Как видите, каждые два слоя имеют сопоставление идентификаторов посредством поэлементного сложения. Это оказалось очень полезным для распространения градиента, поскольку ошибка может распространяться обратно по множеству путей.
Кроме того, с точки зрения представления, это помогает объединять различные уровни функций на каждом этапе сети, точно так же, как мы видели это с начальными модулями.
На сегодняшний день это одна из самых эффективных сетей в ImageNet с уровнем ошибок в топ-5 3,6%.
Плотная сеть
Подключайтесь больше!
Позднее было предложено расширение этого рассуждения. DenseNet предлагает целые блоки слоев, связанных друг с другом.
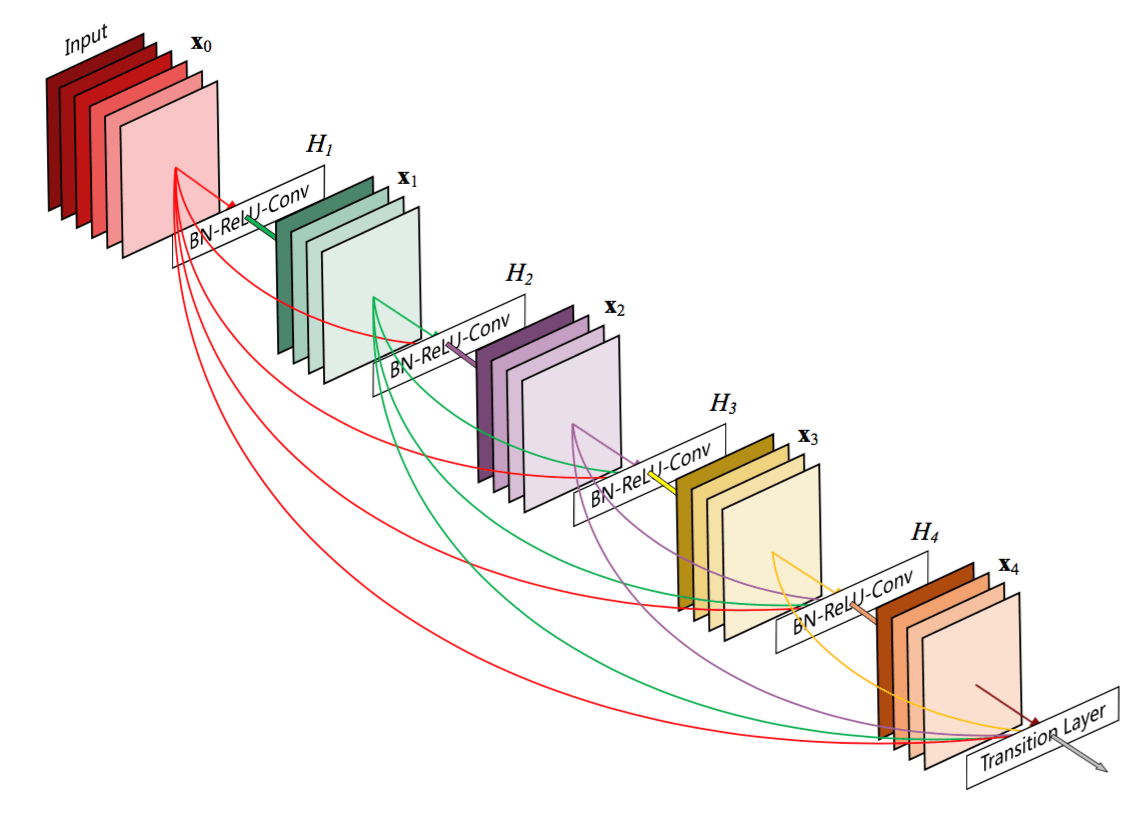
Это способствует разнообразию гораздо большего количества функций в этих блоках.
Заключение
Преобладающей глобальной тенденцией является постоянный прогресс в направлении все более глубокой сетевой архитектуры. Эта траектория была дополнена внедрением вычислительных усовершенствований, таких как выпрямленные линейные единицы (ReLU), отсев и пакетная нормализация. Эти стратегии в совокупности сыграли ключевую роль в повышении общей производительности этих сетей.
Одновременно появились новые модули, способные извлекать сложные функции на каждом этапе сетевой иерархии. Это нововведение не только расширило возможности представления моделей, но и проложило путь к более детальному пониманию.
Еще одним заслуживающим внимания событием является растущее внимание к взаимосвязям между различными уровнями сети. Эти связи играют двойную роль: во-первых, они облегчают создание разнообразных признаков; во-вторых, они способствуют плавному распространению градиентов в сетевой архитектуре, что является решающим фактором для эффективного обучения.
По сути, глобальная траектория глубокого обучения характеризуется двойным механизмом архитектурной глубины и вычислительной сложности в сочетании с изобретательными механизмами извлечения признаков и сложными взаимосвязями слоев. Этот многогранный подход привел к значительным достижениям в этой области, подняв ее на новые высоты производительности и понимания.
На простом английском языке
Спасибо, что вы являетесь частью нашего сообщества! Прежде чем уйти:
- Обязательно аплодируйте и следуйте за автором! 👏
- Еще больше контента вы можете найти на PlainEnglish.io 🚀
- Подпишитесь на нашу бесплатную еженедельную рассылку. 🗞️
- Следуйте за нами в Twitter, LinkedIn, YouTube > и Discord.