Использование DeepShap для понимания и улучшения модели автономного автомобиля

Автономные автомобили меня пугают. Вокруг летают большие куски металла, и нет людей, которые могли бы их остановить, если что-то пойдет не так. Чтобы уменьшить этот риск, недостаточно оценить модели, приводящие в действие этих зверей. Нам также необходимо понять, как они делают прогнозы. Это делается для того, чтобы избежать любых крайних случаев, которые могут привести к непредвиденным авариям.
Итак, наша заявка не так важна. Мы будем отлаживать модель, используемую для питания мини-автомобиля (худшее, что вы можете ожидать, это ушиб лодыжки). Тем не менее, методы IML могут быть полезны. Мы увидим, как они могут даже улучшить производительность модели.
В частности, мы будем:
- Точная настройка ResNet-18 с использованием PyTorch с данными изображения и непрерывной целевой переменной
- Оцените модель с помощью MSE и точечных диаграмм
- Интерпретируйте модель с помощью DeepSHAP
- Исправить модель за счет лучшего сбора данных
- Обсудите, как увеличение изображения может еще больше улучшить модель
Попутно мы обсудим некоторые ключевые фрагменты кода Python. Вы также можете найти полный проект на GitHub.
Если вы новичок в SHAP, посмотрите видеониже. Если вы хотите узнать больше, ознакомьтесь с моим Курсом SHAP. Вы можете получить бесплатный доступ, если подпишитесь на мою Информационную рассылку :)
Пакеты Python
# Imports import numpy as np import pandas as pd import matplotlib.pyplot as plt import glob import random from PIL import Image import cv2 import torch import torchvision from torchvision import transforms from torch.utils.data import DataLoader import shap from sklearn.metrics import mean_squared_error
Набор данных
Начинаем проект со сбора данных только в одной комнате (это нам еще аукнется). Как уже упоминалось, мы используем изображения для питания автоматизированного автомобиля. Вы можете найти такие примеры на Kaggle. Все эти изображения имеют размер 224 x 224 пикселя.
Мы отображаем один из них с кодом ниже. Обратите внимание на название изображения (строка 2). Первые два числа — это координаты x и y в кадре 224 x 224. На Рис. 1 вы можете видеть, что мы отобразили эти координаты с помощью зеленого круга (строка 8).
#Load example image
name = "32_50_c78164b4-40d2-11ed-a47b-a46bb6070c92.jpg"
x = int(name.split("_")[0])
y = int(name.split("_")[1])
img = Image.open("../data/room_1/" + name)
img = np.array(img)
cv2.circle(img, (x, y), 8, (0, 255, 0), 3)
plt.imshow(img)

Эти координаты являются целевой переменной. Модель предсказывает их, используя изображение в качестве входных данных. Затем этот прогноз используется для управления автомобилем. В этом случае видно, что машина приближается к левому повороту. Идеальное направление - идти к координатам, указанным зеленым кругом.
Обучение модели PyTorch
Я хочу сосредоточиться на SHAP, поэтому мы не будем слишком углубляться в код моделирования. Если у вас есть какие-либо вопросы, не стесняйтесь задавать их в комментариях.
Начнем с создания класса ImageDataset. Это используется для загрузки данных изображения и целевых переменных. Он делает это, используя пути к нашим изображениям. Следует отметить, как масштабируются целевые переменные: значения x и y будут находиться в диапазоне от -1 до 1.
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, paths, transform):
self.transform = transform
self.paths = paths
def __getitem__(self, idx):
"""Get image and target (x, y) coordinates"""
# Read image
path = self.paths[idx]
image = cv2.imread(path, cv2.IMREAD_COLOR)
image = Image.fromarray(image)
# Transform image
image = self.transform(image)
# Get target
target = self.get_target(path)
target = torch.Tensor(target)
return image, target
def get_target(self,path):
"""Get the target (x, y) coordinates from path"""
name = os.path.basename(path)
items = name.split('_')
x = items[0]
y = items[1]
# Scale between -1 and 1
x = 2.0 * (int(x)/ 224 - 0.5) # -1 left, +1 right
y = 2.0 * (int(y) / 244 -0.5)# -1 top, +1 bottom
return [x, y]
def __len__(self):
return len(self.paths)
На самом деле, когда модель развернута, для управления автомобилем используются только прогнозы x. Из-за масштабирования знак предсказания x будет определять направление автомобиля. Когда x ‹ 0, машина должна повернуть налево. Точно так же, когда x › 0, машина должна повернуть направо. Чем больше значение x, тем круче поворот.
Мы используем класс ImageDataset для создания загрузчиков данных для обучения и проверки. Это делается путем случайного 80/20 разделения всех путей изображения из комнаты 1. В итоге у нас есть 1217 и 305 изображения в обучающем и проверочном наборе соответственно.
TRANSFORMS = transforms.Compose([
transforms.ColorJitter(0.2, 0.2, 0.2, 0.2),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
paths = glob.glob('../data/room_1/*')
# Shuffle the paths
random.shuffle(paths)
# Create a datasets for training and validation
split = int(0.8 * len(paths))
train_data = ImageDataset(paths[:split], TRANSFORMS)
valid_data = ImageDataset(paths[split:], TRANSFORMS)
# Prepare data for Pytorch model
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
valid_loader = DataLoader(valid_data, batch_size=valid_data.__len__())
Обратите внимание на batch_size для valid_loader. Мы используем длину проверочного набора данных (т.е. 305). Это позволяет нам загружать все данные проверки за одну итерацию. Если вы работаете с большими наборами данных, вам может понадобиться использовать меньший размер пакета.
Мы загружаем предварительно обученную модель ResNet18 (строка 5). Установив model.fc, мы обновляем последний слой (строка 6). Это полностью подключенный слой от 512 узлов до двух наших целевых переменных узлов. Мы будем использовать оптимизатор Adam для точной настройки этой модели (строка 9).
output_dim = 2 # x, y
device = torch.device('mps') # or 'cuda' if you have a GPU
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(512, output_dim)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
Я обучил модель с помощью графического процессора (строка 2). Вы по-прежнему сможете запускать код на процессоре. Точная настройка не так затратна в вычислительном отношении, как обучение с нуля!
Наконец, у нас есть обучающий код модели. Мы тренируемся в течение 10 эпох, используя MSE в качестве функции потерь. Наша окончательная модель имеет самую низкую MSE в проверочном наборе.
name = "direction_model_1" # Change this to save a new model
# Train the model
min_loss = np.inf
for epoch in range(10):
model = model.train()
for images, target in iter(train_loader):
images = images.to(device)
target = target.to(device)
# Zero gradients of parameters
optimizer.zero_grad()
# Execute model to get outputs
output = model(images)
# Calculate loss
loss = torch.nn.functional.mse_loss(output, target)
# Run backpropogation to accumulate gradients
loss.backward()
# Update model parameters
optimizer.step()
# Calculate validation loss
model = model.eval()
images, target = next(iter(valid_loader))
images = images.to(device)
target = target.to(device)
output = model(images)
valid_loss = torch.nn.functional.mse_loss(output, target)
print("Epoch: {}, Validation Loss: {}".format(epoch, valid_loss.item()))
if valid_loss < min_loss:
print("Saving model")
torch.save(model, '../models/{}.pth'.format(name))
min_loss = valid_loss
Метрики оценки
На этом этапе мы хотим понять, как работает наша модель. Мы смотрим на MSE и графики рассеяния фактических и прогнозируемых значений x. Мы пока игнорируем y, так как он не влияет на направление движения автомобиля.
Набор для обучения и проверки
Рисунок 2 показывает эти показатели для обучающего и проверочного набора. Диагональная красная линия дает идеальные прогнозы. Аналогичная вариация вокруг этой линии для x ‹ 0 и x › 0. Другими словами, модель способна предсказывать левый и правый повороты с одинаковой точностью. Аналогичная производительность на обучающем и проверочном наборе также указывает на то, что модель не переоснащена.
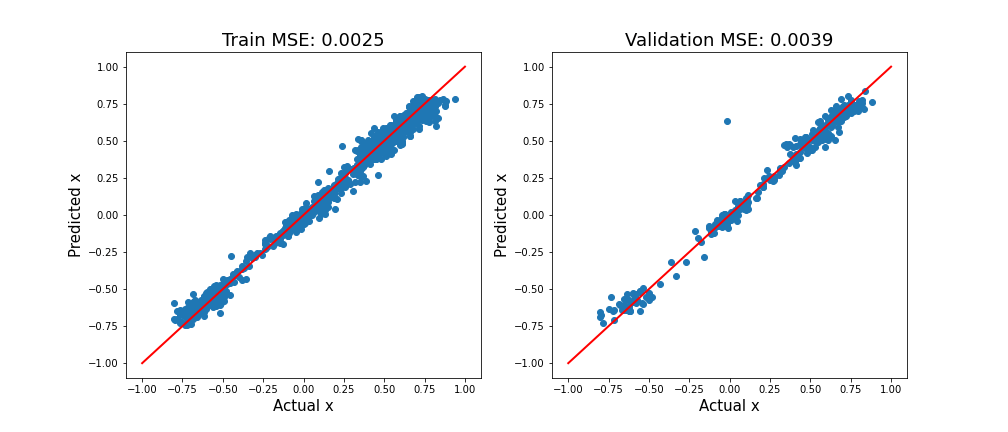
Чтобы создать приведенный выше график, мы используем функцию model_evaluation. Обратите внимание, что загрузчики данных должны быть созданы так, чтобы они загружали все данные в первой итерации.
def model_evaluation(loaders,labels,save_path = None):
"""Evaluate direction models with mse and scatter plots
loaders: list of data loaders
labels: list of labels for plot title"""
n = len(loaders)
fig, axs = plt.subplots(1, n, figsize=(7*n, 6))
# Evalution metrics
for i, loader in enumerate(loaders):
# Load all data
images, target = next(iter(loader))
images = images.to(device)
target = target.to(device)
output=model(images)
# Get x predictions
x_pred=output.detach().cpu().numpy()[:,0]
x_target=target.cpu().numpy()[:,0]
# Calculate MSE
mse = mean_squared_error(x_target, x_pred)
# Plot predcitons
axs[i].scatter(x_target,x_pred)
axs[i].plot([-1, 1],
[-1, 1],
color='r',
linestyle='-',
linewidth=2)
axs[i].set_ylabel('Predicted x', size =15)
axs[i].set_xlabel('Actual x', size =15)
axs[i].set_title("{0} MSE: {1:.4f}".format(labels[i], mse),size = 18)
if save_path != None:
fig.savefig(save_path)
Вы можете видеть, что мы имеем в виду, когда используем функцию ниже. Мы создали новый train_loader, задав размер пакета равным длине обучающего набора данных. Также важно загрузить сохраненную модель (строка 2). В противном случае вы в конечном итоге будете использовать модель, обученную в течение последней эпохи.
# Load saved model
model = torch.load('../models/direction_model_1.pth')
model.eval()
model.to(device)
# Create new loader for all data
train_loader = DataLoader(train_data, batch_size=train_data.__len__())
# Evaluate model on training and validation set
loaders = [train_loader,valid_loader]
labels = ["Train","Validation"]
# Evaluate on training and validation set
model_evaluation(loaders,labels)
Переезд на новые локации
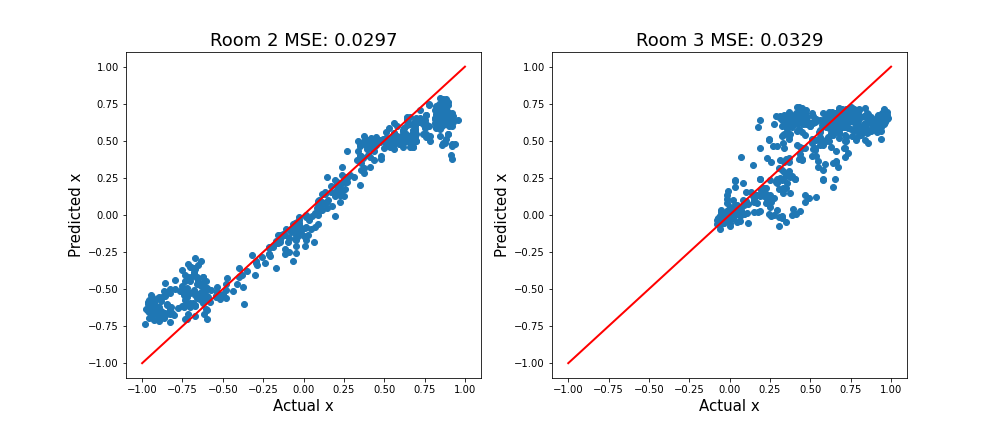
Результаты выглядят хорошо! Мы ожидали, что машина будет работать хорошо, и так оно и было. Пока мы не переместили его в новое место:

Мы собираем некоторые данные из новых локаций (комната 2 и комната 3). Выполнив оценку этих изображений, вы увидите, что наша модель работает не так хорошо. Это странно! Машина находится на той же самой трассе, так какое значение имеет комната?
Отладка модели с помощью SHAP
Мы смотрим на SHAP для ответа. Его можно использовать, чтобы понять, какие пиксели важны для данного прогноза. Мы начинаем с загрузки нашей сохраненной модели (строка 2). SHAP не был реализован для GPU, поэтому мы устанавливаем устройство на CPU (строки 5–6).
# Load saved model
model = torch.load('../models/direction_model_1.pth')
# Use CPU
device = torch.device('cpu')
model = model.to(device)
Чтобы рассчитать значения SHAP, нам нужно получить несколько фоновых изображений. SHAP будет интегрировать эти изображения при расчете значений. Мы используем batch_size из 100 изображений. Это должно дать нам разумные приближения. Увеличение количества изображений улучшит аппроксимацию, но также увеличит время вычисления.
#Load 100 images for background shap_loader = DataLoader(train_data, batch_size=100, shuffle=True) background, _ = next(iter(shap_loader)) background = background.to(device)
Мы создаем объект объяснения, передавая нашу модель и фоновые изображения в функцию DeepExplainer. Эта функция эффективно аппроксимирует значения SHAP для нейронных сетей. В качестве альтернативы вы можете заменить его функцией GradientExplainer.
#Create SHAP explainer explainer = shap.DeepExplainer(model, background)
Мы загружаем 2 примера изображений — поворот направо и налево (строка 2) и трансформируем их (строка 6). Это важно, так как изображения должны быть в том же формате, что и для обучения модели. Затем мы вычисляем значения SHAP для прогнозов, сделанных с использованием этих изображений (строка 10).
# Load test images of right and left turn
paths = glob.glob('../data/room_1/*')
test_images = [Image.open(paths[0]), Image.open(paths[3])]
test_images = np.array(test_images)
test_input = [TRANSFORMS(img) for img in test_images]
test_input = torch.stack(test_input).to(device)
# Get SHAP values
shap_values = explainer.shap_values(test_input)
Наконец, мы можем отобразить значения SHAP с помощью функции image_plot. Но сначала нам нужно их реструктурировать. Значения SHAP возвращаются с размерами:
( #targets, #images, #channels, #width, #height)
Мы используем функцию транспонирования, поэтому у нас есть размеры:
( #targets, #images, #width, #height, #channels)
Обратите внимание, что мы также передали исходные изображения в функцию image_plot. Изображения test_input выглядели бы странно из-за преобразований.
# Reshape shap values and images for plotting shap_numpy = list(np.array(shap_values).transpose(0,1,3,4,2)) test_numpy = np.array([np.array(img) for img in test_images]) shap.image_plot(shap_numpy, test_numpy,show=False)
Результат вы можете увидеть на Рис. 4. В первом столбце приведены исходные изображения. Второй и третий столбцы — это значения SHAP для предсказания x и y соответственно. Синие пиксели уменьшили предсказание. Для сравнения, красные пиксели увеличили предсказание. Другими словами, для предсказания x красные пиксели привели к более резкому повороту направо.

Теперь мы куда-то движемся. Важным результатом является то, что модель использует фоновые пиксели. Вы можете видеть это на рис. 5, где мы увеличиваем прогноз x для правого поворота. Другими словами, фон важен для предсказания. Это объясняет плохую работу! Когда мы переехали в новую комнату, фон изменился, и наши прогнозы стали ненадежными.

Модель адаптирована к данным из комнаты 1. На каждом изображении присутствуют одни и те же объекты и фон. В результате модель связывает их с левым и правым поворотом. Мы не смогли определить это в нашей оценке, поскольку у нас одинаковый фон как на обучающих, так и на проверочных изображениях.

Улучшение модели
Мы хотим, чтобы наша модель хорошо работала в любых условиях. Чтобы достичь этого, мы ожидаем, что он будет использовать только пиксели из дорожки. Итак, давайте обсудим некоторые способы сделать модель более надежной.
Сбор новых данных
Лучшее решение — просто собрать больше данных. У нас уже есть кое-что из комнаты 2 и 3. Следуя тому же процессу, мы обучаем новую модель, используя данные из всех 3 комнат. Глядя на Рисунок 7, теперь он лучше работает с изображениями из новых комнат.

Мы надеемся, что, обучаясь на данных из нескольких комнат, мы разрушаем ассоциации между поворотами и фоном. На левых и правых поворотах теперь присутствуют разные объекты, но трасса остается прежней. Модель должна узнать, что трек — это то, что важно для прогноза.
Мы можем подтвердить это, взглянув на значения SHAP для новой модели. Это для тех же поворотов, которые мы видели на Рис. 4. Теперь фоновые пиксели имеют меньший вес. Хорошо, это не идеально, но мы к чему-то стремимся.

Мы могли бы продолжить сбор данных. Чем больше мест мы собираем, тем надежнее будет наша модель. Однако сбор данных может занять много времени (и скучно!). Вместо этого мы можем обратиться к дополнению данных.
Увеличение данных
Увеличение данных — это когда мы систематически или случайным образом изменяем изображения с помощью кода. Это позволяет нам искусственно вводить шум и увеличивать размер нашего набора данных.
Например, мы можем удвоить размер нашего набора данных, перевернув изображения по вертикальной оси. Мы можем это сделать, потому что наш трек симметричен. Как видно на рисунке 9, удаление также может быть полезным методом. Это включает в себя включение изображений, где объекты или весь фон были удалены.

При построении надежной модели следует также учитывать такие факторы, как условия освещения и качество изображения. Мы можем имитировать их, используя дрожание цвета или добавляя шум. Если вы хотите узнать обо всех этих методах, ознакомьтесь со статьей ниже.
В приведенной выше статье мы также обсуждаем, почему трудно сказать, сделали ли эти дополнения модель более надежной. Мы могли бы развернуть модель во многих средах, но это требует много времени. К счастью, в качестве альтернативы можно использовать SHAP. Как и в случае со сбором данных, это может дать нам представление о том, как дополнения изменили то, как модель делает прогнозы.
Надеюсь, вам понравилась эта статья! Вы можете поддержать меня, став одним из моих приглашенных участников :)
| Твиттер | Ютуб | Информационный бюллетень — подпишитесь на БЕСПЛАТНЫЙ доступ к Курсу Python SHAP
Набор данных
Изображения JatRacer (CC0: Public Domain) https://www.kaggle.com/datasets/conorsully1/jatracer-images
Рекомендации
SHAP, пример PyTorch Deep Explainer MNISThttps://shap.readthedocs.io/en/latest/example_notebooks/image_examples/image_classification/PyTorch%20Deep%20Explainer%20MNIST%20example.html