Комплексный анализ алгоритмов обнаружения объектов

Обзор
Механизм человеческого видения завораживает. Зрительные сенсоры воспринимают изображение и преобразуют его в электрические сигналы, которые передают нейронным системам. Затем мозг обрабатывает сигналы, что в конечном итоге позволяет людям видеть, а также понимать контекст изображения, в том числе, какие объекты находятся на изображении, где и сколько их находится. Все эти сложные процессы происходят мгновенно. Если дать ручку и попросить нарисовать рамку вокруг всех видимых объектов, это легко сделать.
Однако сомнительно, что машина может выполнять этот процесс так же эффективно, как люди. Сверточные нейронные сети (ConvNets или CNN) хорошо извлекают признаки из заданного изображения и, наконец, классифицируют его как кошку или собаку. Этот процесс известен как классификация изображений. Это простая задача, если объекты расположены по центру, а на изображении всего несколько объектов. Если количество объектов увеличивается и объекты принадлежат к разным классам, их необходимо различать и локализовать на изображении. Это известно как обнаружение и локализация объекта. Чжао утверждает, что обнаружение объектов — это процесс построения полного понимания, включая классификацию и оценку концепций и местоположения объектов на каждом изображении. (Чжао и др., 2019). Обнаружение объектов также включает в себя подзадачи, такие как обнаружение лиц, обнаружение пешеходов и обнаружение ключевых точек. Эти подзадачи используются во многих приложениях, включая анализ человеческого поведения, распознавание лиц и автономное вождение (Zhao, et al., 2019).
В этой статье я сосредоточусь на алгоритмах обнаружения объектов, которые являются алгоритмами семейства R-CNN; R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, однократный многоблочный детектор (SSD), RetinaNet и YOLO сильные > семейные алгоритмы; YOLO, YOLO-9000, YOLOv3, YOLOv4 и YOLOv5.
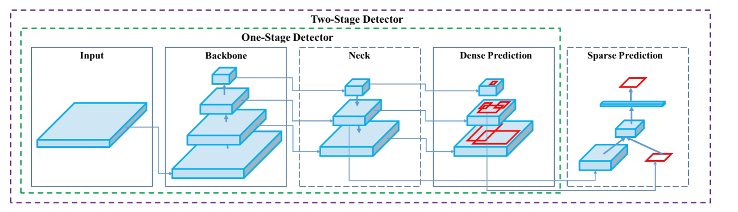
По словам Бочковского и др., детекторы объектов состоят из двух основных частей: основы, обученной на ImageNet, и головы, используемой для предсказателей ограничительной рамки. В первую очередь VGG, ResNet, ResNeXt и Darknet используются для платформ GPU, а SqueezeNet, MobileNet или ShuffleNet — для платформ CPU в качестве архитектуры «базовой». Большинство детекторов объектов вставляют соединительные слои между магистралью и головкой для сбора карт признаков с разных стадий. Это известно как «шея». Можно использовать различные шейки, такие как Feature Pyramid Networks, PANet или Bi-FPN. В зависимости от детектора объектов могут использоваться различные «головы», в том числе YOLO, SSD или RetinaNet в качестве одноэтапных детекторов или семейство R-CNN в качестве двухэтапных детекторов (Бочковский и др., 2020).
R-CNN — сверточные нейронные сети на основе регионов
R-CNN и быстрый R-CNN
В первой версии сверточные нейронные сети на основе регионов (R-CNN) состоят из трех этапов. Первым этапом является генерация предложения по региону, на котором определяется набор обнаружений-кандидатов. Второй этап — извлечение признаков для каждого региона, а последний этап — классификация (Girshick et al., 2013). Гиршик и др. используйте алгоритм выборочного поиска для создания предложений по регионам и используйте архитектуру AlexNet CNN в качестве средства извлечения признаков. На заключительном этапе извлеченные функции передаются в линейные машины опорных векторов (SVM), которые оптимизируются для каждого класса, чтобы классифицировать присутствие объектов в предложении региона-кандидата. В дополнение к прогнозированию класса предложения области алгоритм также прогнозирует четыре значения, которые являются значениями смещения для повышения точности ограничивающей рамки. Несколько недостатков сопровождают алгоритмы R-CNN. Во-первых, они медленно обучаются, а классификация каждого предложения региона (~ 2000) для каждого изображения требует больших затрат. Во-вторых, R-CNN нельзя использовать в сценариях реального времени, поскольку для проверки изображения требуется около 47 секунд. В-третьих, исправлен алгоритм выборочного поиска R-CNN. Таким образом, на этом этапе нет обучения, что может привести к плохому предложению кандидата.
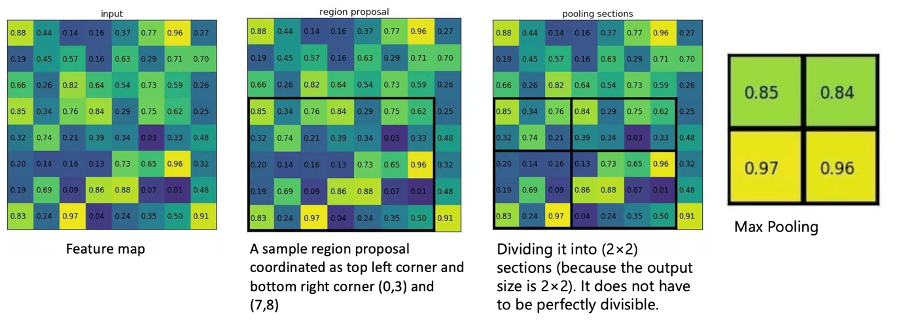
В 2015 г. Гиршик предложил улучшенную версию R-CNN, известную также как Fast R-CNN (Girshick, 2015).Этот подход аналогично оригиналу, но вместо того, чтобы передавать предложения регионов в сверточный слой, исходное изображение используется для создания сверточной карты объектов. Предложения по регионам идентифицируются на карте объектов, а затем обрабатываются объединяющим слоем RoI (область интереса), чтобы придать им фиксированный размер; затем они передаются в полносвязный слой. Есть два двойных выходных слоя. Первый слой выводит дискретное распределение вероятностей по ROI по категориям. Второй слой выводит смещения регрессии ограничивающей рамки. Это достигается за счет так называемой потеря многозадачности.

В результате из вектора признаков области интереса, показанного на рисунке 2, прогнозируются значения класса и смещения для каждой предлагаемой области. Важным компонентом Fast R-CNN является RoIPooling, который позволяет повторно использовать карту объектов из предыдущей сверточной сети; этот метод значительно сокращает время обучения и тестирования и позволяет обучать систему обнаружения объектов от начала до конца (Grel, 2017).
Проблема с Fast R-CNN заключается в том, что он по-прежнему использует алгоритм выборочного поиска для генерации предложений по регионам. Поскольку этот процесс является дорогостоящим и трудоемким, создание предложения по региону стало узким местом для алгоритма.
Быстрее R-CNN
В 2015 году Рен и соавт. предложил Faster R-CNN, который устраняет алгоритм выборочного поиска предложений регионов и использует сети предложений регионов (RPN) для изучения предложений регионов (Ren, et al., 2015).
В своей оригинальной статье Ren et al. используйте модель Цейлера и Фергуса, которая имеет 5 общих сверточных слоев, а также VGG16, которая имеет 13 общих сверточных слоев, в качестве экстракторов признаков, также известных как магистральные сети. В реализации PyTorch Faster R-CNN использует ResNet с FPN или MobileNetV3 с FPN в качестве экстракторов функций; архитектура показана на рисунке 4.

Сеть региональных предложений (RPN) — это небольшая сеть, которая скользит по сверточной карте объектов, выводимой последним общим сверточным слоем. Он генерирует предложения прямоугольных объектов с оценками объектности, беря пространственное окно 3 x 3 входных сверточных карт признаков, сгенерированных экстрактором признаков. В каждом месте скользящего окна RPN генерирует k различных возможных предложений. Эти k различных предложений приводят к 2k показателям объектности и 4k координатам. Кроме того, эти k различных предложений относятся к k различным эталонным блокам, называемым якорями. Эти якоря бывают разных размеров и форм (Ren, et al., 2015). В своей статье Ren et al. укажите, что они использовали 3 масштаба и 3 соотношения сторон, всего 9 якорей. RPN обучаются путем присвоения меток двоичного класса каждому якорю, чтобы проверить, есть ли какой-либо объект или нет. Положительные метки предназначены для привязок с самым высоким IoU и для привязок с перекрытием IoU выше 0,7 с полем достоверности. Отрицательные метки присваиваются неположительному якорю с IoU 0,3 для всех полей достоверности. В соответствии с этими определениями функция потерь для RPN определяется, как показано в уравнении 1:

где i — индекс якоря в мини-пакете, а pi — вероятность того, что в этом якоре есть объект. Метка достоверности p*i равна 1, если привязка положительна, и 0, если привязка отрицательна; ti — вектор, представляющий 4 параметризованные координаты ограничивающей рамки; а t*i — поле истинности основания, связанное с положительной привязкой. Потеря классификации представляет собой бинарную кросс-энтропию, а потеря регрессии — гладкую L1. Потеря регрессии активируется только для положительных привязок, где p*i не равно нулю. Для 4 координат ограничивающей рамки используются следующие параметры, как определено в уравнении 2:
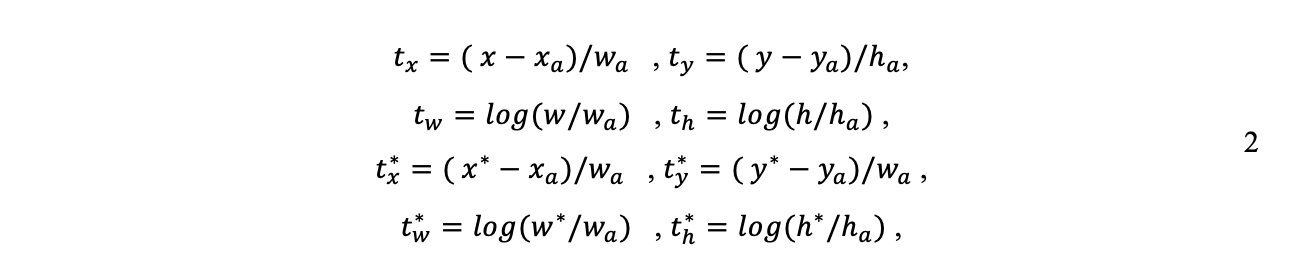
где x и y обозначают координаты центра коробки, а h и w обозначают высоту и ширину; x, xa и x* обозначают предсказанную ограничивающую рамку, привязку и истину.
После того, как RPN генерирует предложения по регионам, Faster R-CNN также использует ROI Pooling — как и в Fast R-CNN — для объединения региональных предложений и карт функций для задач обнаружения.
Маска R-CNN
Он и др. разработал Mask R-CNN в 2017 году, расширив Faster R-CNN и добавив ветвь для прогнозирования маски объекта параллельно с прогнозированием ограничивающей рамки (He, et al., 2017). Mask R-CNN работает со скоростью 5 кадров в секунду. Основная цель — сегментация экземпляров. Новая ветвь модели Mask R-CNN предсказывает пиксели с помощью масок сегментации пикселей в каждой интересующей области (RoI). RoIAlign используется вместо RoIPool, потому что он не требует квантования и исправляет рассогласование и сохраняет пространственное положение.
В реализации PyTorch Mask R-CNN использует ResNet с FPN или MobileNetV3 с FPN в качестве экстракторов функций; архитектура показана на рисунке 5.

Как показано в таблице 1, Mask-RCNN также превосходит Faster RCNN в задачах обнаружения объектов в mAP. Он и др. предполагают, что это улучшение связано с RoIAlign (+1,1AP), многозадачным обучением (+0,9AP) и ResNeXt101 (+1,6AP) (He, et al., 2017).

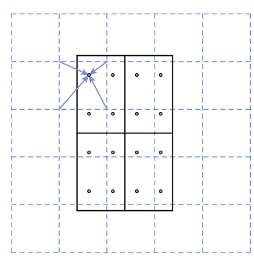
Он и др. предложить RoIAlign для решения проблемы квантования, вызванной RoIPooling (RoIPool представлен в разделе 1.1.1.1. RoIAlign просто избегает любого квантования границ RoI; он использует билинейную интерполяцию для вычисления точных значений функций в каждом бине RoI и агрегирует результаты. Как показано на рисунке 6, пунктирная сетка представляет собой карту объектов, сплошные линии — области интереса (RoI), а четыре точки — точки выборки.RoI вычисляет билинейную интерполяцию точки из ближайшей сетки на объекте Таким образом, во время этих операций квантование не происходит.
Mask R-CNN использует ту же функцию потерь, что и Faster R-CNN. Кроме того, у него есть потеря маски, как определено уравнением 3:

Lcls и Lbox определены как в Faster R-CNN. Ветвь маски имеет двоичную маску K для каждой ROI, и каждая маска представляет собой разрешение m x m, которое является результатом размерного вывода Km2 для каждой ROI. Поэтому есть возможность создавать сетью маски для каждого класса, что предотвращает конкуренцию между классами. Он и др. применять сигмоид для каждого пикселя и использовать Lmask как бинарную кросс-энтропийную потерю (He, et al., 2017).
Однокадровый детектор MultiBox (SSD)
Детекторы объектов на основе регионов, такие как семейство R-CNN, требуют, по крайней мере, двухэтапных детекторов объектов, где первый этап — это генерация предложения, а второй этап состоит из обнаружения объекта для каждого предложения. Детектор Single Shot MultiBox, также известный как SSD, является одноступенчатым детектором, что означает, что и локализация объекта, и классификация выполняются за один проход сети с прямой связью, который создает набор ограничивающих рамок фиксированного размера и оценки для наличие экземпляров класса объекта, за которым следует подавление не-max для удаления одинаковых обнаружений для объекта (Liu, et al., 2016). SSD работает со скоростью 59 кадров в секунду (FPS) с mAP 74,3% в тестовом наборе данных VOC2007. Для сравнения, Faster R-CNN работал со скоростью 7 кадров в секунду с mAP 73,2%, а YOLO работал со скоростью 45 кадров в секунду с mAP 63,4% (Liu, et al., 2016).
Согласно Лю и соавт. наибольшее улучшение достигается за счет устранения предложений ограничивающих рамок и повторной выборки признаков. Вклад SSD тройной. Во-первых, он быстрее и значительно точнее, чем современный однократный детектор (YOLO). Во-вторых, он прогнозирует оценки категорий и смещения ограничивающей рамки для фиксированного набора bbox по умолчанию, используя небольшие сверточные фильтры, применяемые к картам объектов. В-третьих, он генерирует прогнозы для разных масштабов из карт объектов разных масштабов и разделяет прогнозы по соотношению сторон.
Архитектура SSD основана на VGG-16, хотя в ней отсутствуют полносвязные слои. Дополнительные сверточные слои добавляются для извлечения признаков из разных масштабов и постепенного уменьшения размера входных данных на каждом слое. Это заявлено как многомасштабные карты признаков для обнаружения. SSD вычисляет оценки местоположения и класса, используя небольшие сверточные фильтры размером 3x3, которые производят либо оценку для категории, либо смещение формы относительно координат блока по умолчанию для каждой ячейки (Liu, et al., 2016). Эти фильтры известны как сверточные предикторы для обнаружения. SSD использует ограничивающие рамки по умолчанию, такие как привязки в Faster R-CNN.

Лю и др. также опишите технику, называемую жестким негативным майнингом, которая использует некоторые негативные и позитивные примеры во время обучения. Поскольку большинство ограничивающих рамок имеют низкий уровень пересечения над объединением (IoU) и интерпретируются как отрицательные примеры, Liu et al. используйте соотношение 3:1 между отрицательными и положительными примерами, чтобы сбалансировать обучающие примеры. Это также помогает сети обучаться неверным обнаружениям (Liu et al., 2016).
Также применяются методы увеличения данных, такие как переворачивание и исправление, как и во многих других приложениях нейронных сетей. Лю и др. используйте горизонтальное отражение с вероятностью 0,5, чтобы потенциальные объекты появлялись как слева, так и справа с одинаковой вероятностью.
Функция потерь для модели SSD представляет собой взвешенную сумму потерь локализации (loc) и потерь достоверности (conf), как описано в уравнении 4:

где x — индикатор соответствия поля по умолчанию истинному положению; l — предсказанный блок, а N — количество соответствующих блоков по умолчанию истинному. Потеря достоверности — это выход SoftMax для достоверности нескольких классов ©, а потеря локализации — это потеря Smooth L1 между предсказанным полем и истинностью основания (Liu, et al., 2016).
RetinaNet
Функция Focal Loss для обнаружения плотных объектов, также известная как RetinaNet, была предложена в 2018 году Lin et al. По словам Лина и др., причиной более низкой точности одноступенчатых детекторов является крайний дисбаланс классов переднего плана и фона. Дисбаланс классов решается в семействе R-CNN и других двухступенчатых детекторах. Состояние предложения, такое как предложения выборочного поиска или RPN, отвечает за фильтрацию большинства фоновых выборок путем сужения количества местоположений объектов-кандидатов до небольшого числа (1–2 тыс.), В то время как одноэтапные детекторы должны обрабатывать ~ 100 тыс. На втором этапе эвристика выборки, такая как фиксированное соотношение переднего плана к фону (1:3) или онлайн-анализ сложных примеров, помогает сбалансировать передний план и фон. Хотя одноэтапные детекторы используют бутстрэппинг или интеллектуальный анализ жестких примеров, Liu et al. утверждают, что этих методов недостаточно для борьбы с ним. Таким образом, Лин и соавт. предложить измененную кросс-энтропийную потерю таким образом, чтобы она уменьшала вес потери для достижения хорошо классифицированной потери (Lin, et al., 2018).

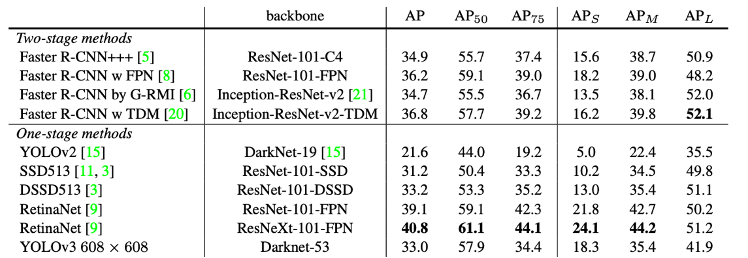
RetinaNet использует сеть ResNet + Feature Pyramid Network (FPN) в качестве основы, которая отвечает за извлечение богатых и многомасштабных карт функций из всего изображения. Затем RetinaNet использует одну подсеть для прогнозирования классов, а другую — для прогнозирования ограничивающей рамки. Как видно из таблицы 2, RetinaNet является первым одноэтапным детектором, который превосходит двухэтапные детекторы не только по времени вывода (FPS), но и по точности для своего времени.

Фокусная потеря была предложена для устранения дисбаланса между классами переднего плана и фона. Как заявил Лин и др., Весовой коэффициент является распространенным методом изменения кросс-энтропии (Лин и др., 2018). Поэтому добавляют модулирующий коэффициент (1-pt)y, где - параметр фокусировки:


You Only Look Once (YOLO) Семья
ЙОЛО, V1
Алгоритм YOLO был впервые предложен в 2015 году Редмоном и соавт. Он использует подход, отличный от других алгоритмов обнаружения объектов того времени. Он определяет обнаружение объектов как проблему регрессии, в то время как другие используют подход классификации. Редмон и др. утверждают, что, поскольку одна сеть предсказывает как ограничивающую рамку, так и вероятности классов за один проход, ее можно оптимизировать от начала до конца (Redmon, et al., 2015).
YOLO (v1) может обрабатывать изображения со скоростью 45 кадров в секунду, а уменьшенная версия YOLO может обрабатывать изображения со скоростью 155 кадров в секунду, при этом удваивая mAP по сравнению с другими детекторами объектов в реальном времени (Redmon, et al., 2015).
Идея алгоритма YOLO состоит в том, чтобы взять изображение в качестве входных данных и разбить его на ячейки, которые можно представить наложенными на сетку (S x S); если центр объекта попадает в ячейку сетки, эта ячейка сетки отвечает за предсказания.

Каждая ячейка сетки генерирует B ограничивающих прямоугольников и показатель достоверности для этих прямоугольников, отражающий уверенность модели в отношении прямоугольника относительно того, содержит ли он объект или нет. Редмон и др. сформулируйте уверенность, как в формуле 6 (Redmon, et al., 2016):
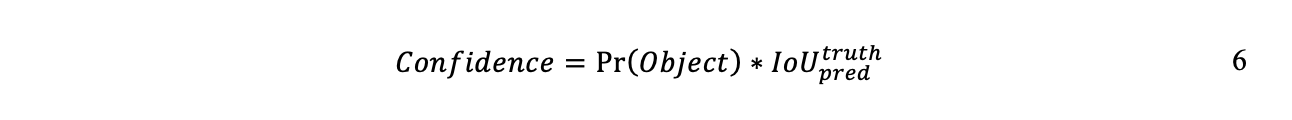
Согласно этой формуле, если в ячейке нет объекта, то показатель достоверности должен быть равен нулю. Если объект присутствует в ячейке, то вероятность равна 1, а достоверность равна IoU между предсказанной ограничивающей рамкой и земной истиной.
Как упоминалось выше, каждая ячейка предсказывает ограничивающую рамку B, и для каждой ограничивающей рамки имеется 5 значений. Это x, y, w и h ограничивающей рамки, а также оценка достоверности. (x, y) — это центр ограничивающей рамки, а w и h — ширина и высота ограничивающей рамки относительно всего изображения. Наряду с ограничивающей рамкой каждая ячейка сетки также предсказывает вероятности класса, если есть объект — другими словами, вероятности C-условного класса Pr (Classi | Object) — поэтому формула отображается следующим образом (Redmon, et al. , 2015):
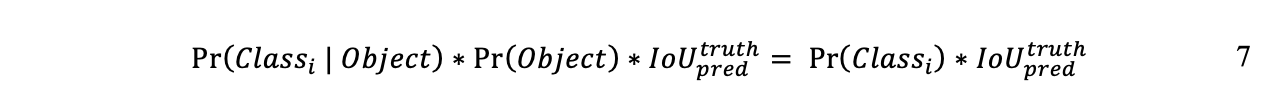
Общие прогнозы для изображения равны S x S x (B * 5 + C). В своей статье Redmon et al. заявить, что они использовали S = 7 и B = 2 в наборе данных PASCAL VOC, который имеет 20 классов; таким образом, окончательное предсказание представляет собой тензор 7 x 7 x 30. На заключительном этапе YOLO применяет немаксимальное подавление для устранения дубликатов (Redmon, et al., 2016).

YOLO v1 имеет 24 сверточных слоя и 2 полносвязных слоя, вдохновленных GoogLeNet. Однако вместо начальных модулей YOLO использует слой сокращения 1x1, за которым следуют сверточные слои 3x3. Сверточные слои предварительно обучаются в ImageNet с половинным разрешением (224 x 224), а затем удваивают разрешение для обнаружения.
YOLO v1 имеет известные в то время ограничения. Поскольку каждая ячейка сетки предсказывает только два ограничивающих прямоугольника и один класс, трудно обнаружить близкие объекты. YOLO v1 также сложно обнаруживать мелкие объекты. Функция потерь создает риск повторяющихся ошибок как для больших, так и для малых объектов. Небольшие ошибки на мелких объектах имеют больший эффект.
YOLO использует функцию потерь, состоящую из нескольких частей, которая представляет собой сумму потерь локализации, потерь достоверности и потерь классификации. Потеря локализации измеряет ошибки в прогнозируемых положениях и размерах ограничительных рамок;
уделяет больше внимания точности ограничивающей рамки. Кроме того, потеря доверия измеряет наличие объекта в ячейках; это называется объектностью. Если объект обнаружен, потеря классификации предсказывает класс объекта в каждой ячейке путем вычисления квадратичной ошибки условных вероятностей класса для каждого класса.

В то время, когда YOLO был предложен, он превосходил двухэтапные детекторы как в mAP, так и в FPS, как видно из таблицы 3.

ЙОЛО v2 (ЙОЛО 9000)
SSD был сильным конкурентом, когда он был предложен. У YOLO были более высокие ошибки локализации, в то время как его отзыв, который измеряет, насколько хорошо он находит все объекты, был ниже. Таким образом, YOLO v2 направлен на улучшение отзыва и локализации при сохранении точности классификации (Redmon & Farhadi, 2016).
Редмон и Фархади используют несколько методов для улучшения YOLO v2, описывая в своей статье путь от YOLO к YOLO v2. Первым из этих методов является нормализация партии, которая обеспечивает значительное улучшение сходимости и устраняет другие методы нормализации. Применив нормализацию партии, Редмон и Фархади добились улучшения mAP на 2% и устранили отсев; нормализация партии также улучшила регуляризацию и предотвратила переобучение. Второй метод использует классификатор с более высоким разрешением. Все современные детекторы объектов используют классификаторы, предварительно обученные в ImageNet. В YOLO v1 это 224 x 224; но в YOLO v2 сеть классификации обучается на ImageNet с входными изображениями с разрешением 448 x 448 для 10 эпох. Более высокое разрешение дает дополнительное увеличение mAP на 4%. Третий метод — свертка с блоками привязки, как в Faster R-CNN: сеть прогнозирует смещения только для заданных вручную блоков привязки (приоритеты). Поэтому Редмон и Фархади удаляют полностью связанные слои и используют блоки привязки для предсказания ограничивающих прямоугольников. Один объединяющий слой удаляется для увеличения разрешения, а изображение сжимается до 416 x 416 вместо 448 x 448. Мотивация для этого процесса сжатия заключается в использовании нечетного количества местоположений в сетке, чтобы гарантировать единую центральную ячейку. YOLO уменьшает изображение в 32 раза; таким образом, 448 заканчивается 14, тогда как 416 заканчивается 13. Наконец, Редмон и Фархади утверждают, что они могли бы добиться лучших результатов, начав с лучших якорных ящиков. Поэтому они используют кластеризацию k-средних в наборе данных, чтобы найти поля привязки.

Вместо предсказания смещения в соответствии с блоками привязки Редмон и Фархади используют прямое предсказание местоположения, которое смещено к сетке. Это помогает устранить нестабильность модели на ранних итерациях. Для каждой ограничивающей рамки сеть предсказывает 5 координат (tx, ty, tw, th и to). Если ячейка смещена на (cx, cy) от верхнего левого угла, и если ширина привязки (pw) и высота (ph), то прогнозы ограничивающей рамки и объектности следующие:

Редмон и Фархади также используют детализированные функции, которые являются функциями из более ранних слоев. Другие детекторы объектов используют другие шкалы, которые вносят свой вклад в прогнозы. Поэтому Редмон и Фархади также применяют аналогичный подход, используя функции из более ранних слоев в разрешении 26x26; они объединяют функции высокого и низкого разрешения, такие как сопоставления идентификации, как в ResNet. Они также используют мультимасштабное обучение, которое влечет за собой изменение размера ввода во время обучения. Они сообщают, что используют набор, кратный 32 ({320, 352, …, 608}), и что этот режим заставляет сеть учиться более эффективно прогнозировать по различным входным измерениям (Redmon & Farhadi, 2016).

Редмон и Фархади также используют специальный экстрактор базовых функций, отличный от VGG-16. Хотя VGG-16 мощная и точная, она также сложна — она имеет 30,69 миллиарда FLOP за один проход, тогда как пользовательская сеть, разработанная для YOLO v2, имеет 8,52 миллиарда FLOP. Точность пользовательской сети немного хуже, чем у VGG-16: в то время как VGG-16 имеет точность 90% в ImageNet, точность пользовательской сети составляет 88% (Redmon & Farhadi, 2016). Окончательная модель называется Darknet-19 с 19 сверточными слоями и 5 слоями максимального объединения.
Редмон и Фархади также используют иерархическую классификацию, которая позволяет объединять наборы данных классификации и наборы данных обнаружения, позволяя использовать метки изображений. Иерархическая классификация и комбинированные наборы данных позволяют обнаруживать объекты в реальном времени по более чем 9000 категориям объектов.
ЙОЛО v3
В 2018 году Редмон и Фархади предложили несколько обновлений алгоритма YOLO. YOLO v3 имеет новую сетевую архитектуру извлечения функций под названием Darknet-53, которая представляет собой вариант Darknet с 53 уровнями, обученными на ImageNet. Для обнаружения задач на него накладываются 53 дополнительных слоя. Он имеет 106 полностью сверточных слоев. Из-за такой тяжелой архитектуры он не быстрее YOLO-v2, хотя и более точен (Redmon & Farhadi, 2018). Редмон и Фархади утверждают, что Darknet-53 лучше, чем RestNet-101, и в 1,5 раза быстрее, с аналогичной производительностью ResNet-152, хотя и в 2 раза быстрее.

Благодаря новой архитектуре YOLO v3 с Darknet53 лучше, чем SSD, и близок к современному RetinaNet на AP50, хотя и в 3 раза быстрее.
Из соображений производительности Редмон и Фархади обновляют предсказание класса, используемое в независимых логистических классификаторах, вместо использования SoftMax. При таком подходе они могут использовать классификацию по нескольким меткам и решить проблему перекрывающихся меток (например, «женщина» и «человек»). Они также предлагают прогнозы в разных масштабах в своей статье. YOLO v3 генерирует предсказания ограничительной рамки в 3 разных масштабах. Таким образом, тензор S x S x [3 * (4+1 + 80)] для набора данных COCO для каждой шкалы (Redmon & Farhadi, 2018). Как видно на рис. 14, предсказание по нескольким масштабам помогает обнаруживать объекты в разных масштабах. Они используют кластеризацию k-средних в наборе данных COCO, чтобы найти поля привязки для каждой шкалы, которые представляют собой следующие 9 полей привязки (по 3 для каждой шкалы): (10 × 13), (16 × 30), (33 × 23) , (30 × 61), (62 × 45), (59 × 119), (116 × 90), (156 × 198) и (373 × 326) (Redmon & Farhadi, 2018).

Кстати, после разработки YOLO v3 в 2020 году Редмон решил прекратить исследования в области компьютерного зрения из-за его военных приложений и связанных с этим проблем с конфиденциальностью.

ЙОЛО v4
Бочковский и др. продолжили исследования алгоритма YOLO и предложили YOLO v4 в 2020 году. Их вклад в YOLO v4 заключается, прежде всего, в разработке эффективной и мощной модели обнаружения объектов, проверке методов «мешок халявы» и «мешок специальных предложений», а также в изменении состояния -art для запуска на одном графическом процессоре для всех. Они добились выдающихся результатов с 43,5% AP (65,7% AP50) для набора данных MS COCO при скорости в реальном времени 65 кадров в секунду (Бочковский и др., 2020) за счет сочетания некоторых из следующих методов: Взвешенные остаточные связи ( WRC), межстадийные частичные соединения (CSP), кросс-мини-пакетная нормализация (CmBN), самосостязательное обучение (SAT), активация Mish, увеличение мозаичных данных и регуляризация отбрасываемых блоков.
Их сверточные нейронные сети обучались в автономном режиме, а исследователи разрабатывали модели и использовали методы, помогающие повысить точность модели во время вывода без ущерба для стоимости вывода. Поэтому такой подход называется мешком халявы.
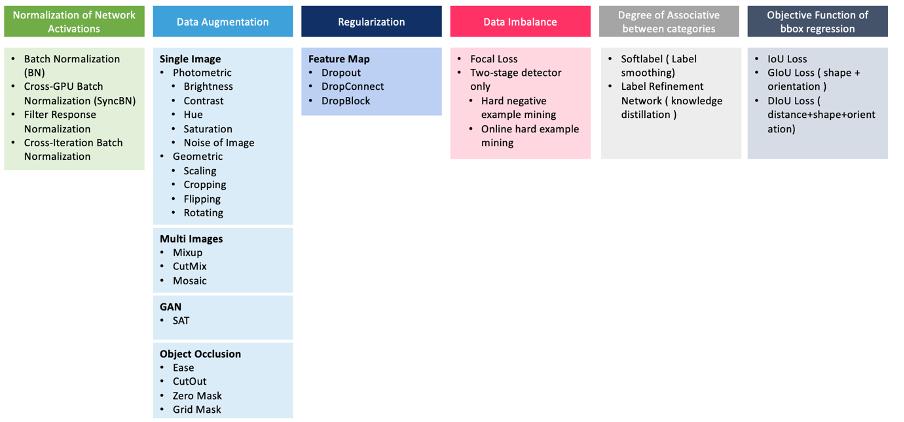
Увеличение данных помогает обучать модель изменчивости входных изображений для повышения надежности. Этот подход в основном основан на фотометрических искажениях (таких как изменение яркости, контраста, оттенка, насыщенности и шума изображения) и геометрических искажениях (таких как вращение, отражение, обрезка и случайное масштабирование); это одна из техник из категории халявы (Бочковский и др., 2020). В дополнение к попиксельному увеличению некоторые исследователи предлагают обрабатывать несколько изображений одновременно с помощью MixUp, который использует два изображения для умножения и наложения в разных соотношениях, или CutMix, который покрывает некоторые части изображения другими изображениями, и Mosaic, который смешивает 4 разных изображения. тренировочные образы. Как упоминалось ранее в отношении RetinaNet, несбалансированные/предвзятые наборы данных приводят к низкопроизводительным моделям; таким образом, они имеют низкую точность. С другой стороны, помеченные данные могут быть неверными. Если набор данных небольшой, возможна ручная проверка; но для больших наборов данных сглаживание меток — это математический способ улучшить обучение на неправильно помеченных образцах в наборе данных (Szegedy, et al., 2015). Хотя среднеквадратическая ошибка в основном используется как функция потерь для задач регрессии, Бочковский и др. также заявляют, что при использовании координат ограничивающей рамки в качестве независимых переменных нарушается целостность объекта (Бочковский и др., 2020).
Бочковский и др. также предложите набор специальных возможностей, который незначительно увеличивает затраты на логические выводы, но значительно повышает точность обнаружения объектов.
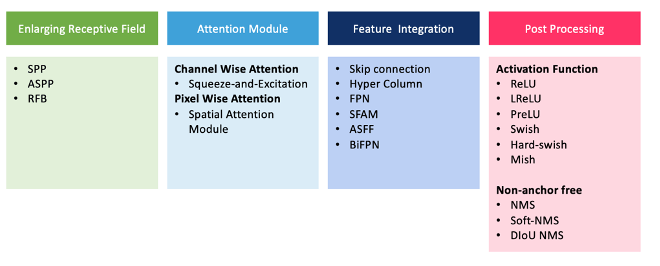
Увеличивающиеся рецептивные поля — это SSP (Spatial Pyramid Pooling), предложенный He et al. чтобы устранить ограничение ввода сети фиксированного размера путем создания представлений изображений фиксированной длины (He, et al., 2015), а также ASPP (Atrous Spatial Pyramid Pooling), который был предложен Ченом. и другие. (Chen, et al., 2017), чтобы помочь эффективно увеличить поле зрения фильтров для включения большего контекста без значительного увеличения количества параметров или объема вычислений — и RFB (Receptive Field Block) , предложенный Liu et al. и был вдохновлен зрительными системами человека. RFB учитывает взаимосвязь между размером и эксцентриситетом рецептивных полей для повышения различимости и надежности признаков (Liu, et al., 2018).
Модули внимания — в первую очередь модуль внимания по каналам и модуль внимания по пикселям — также используются при обнаружении объектов. Сжатие и возбуждение, представитель внимания по каналам, был предложен Hu et al. чтобы позволить моделям/сетям создавать информативные функции, передавая пространственную и канальную информацию в локальные рецептивные поля на каждом уровне (Hu, et al., 2019). Как Бочковский и соавт. отчет, модуль SE является дорогостоящим для графического процессора (стоимость +10%), хотя его можно использовать для процессора/мобильных устройств (стоимость +2%) (Бочковский и др., 2020). SAM (Модуль пространственного внимания), представляющий попиксельное внимание, был предложен Woo et al. в качестве строительного блока для модуля внимания сверточных блоков (Woo, et al., 2018). SAM создает маску, которая улучшает важные функции, определяющие объект, и уточняет карты функций.
Интеграция функций, таких как пропуск соединений и FPN, помогает интегрировать функции низкого уровня в функции высокого уровня. Функции активации обеспечивают нелинейность, и целью выбора активации является эффективное обратное распространение градиента. Другим процессом постобработки является NMS (Non-Max Suppression), который представляет собой процесс устранения ограничивающих рамок с низкими оценками.
Таким образом, архитектура YOLO v4 выглядит следующим образом: магистраль — CSPDarknet53, шея — SPP и PAN, голова — такая же, как в YOLOv3. Бесплатными подходами для магистрали являются CutMix, Mosaic Data Augmentation, регуляризация DropBlock и Label Smoothing. Набор специальных методов для магистрали — это активация Mish, частичные соединения между этапами (CSP) и взвешенные остаточные соединения с несколькими входами (MiWRC). Бесплатными методами для детектора являются CIoU-потеря, CmBN, регуляризация DropBlock, увеличение данных Mosaic, самосостязательное обучение, устранение чувствительности к сетке, использование нескольких привязок для одной основной истины, оптимальные гиперпараметры планировщика косинусного отжига и случайные тренировочные формы. К набору специальных методов для детектора относятся активация Mish, SPP-блок, SAM-блок, блок агрегации путей PAN и DIoU-NMS (Бочковский и др., 2020).
В обсуждении на Github.com Бочковский указал на вклад в mAP методов «мешка халявы» и «мешка специальных предложений», таких как SPP (+3%), CSP+PAN (+2%), SAM (+0,3%). , CIoU+S (+1,5%), настройка мозаики и гиперпараметров (+2%), масштабированные привязки (+1%), всего примерно +10% (Бочковский, 2020). Таким образом, 5% общего улучшения приходится на архитектуру, еще 5% — на халяву (Бочковский, 2020).
ЙОЛО v5
YOLO v4 стал большим шагом вперед по сравнению с YOLO v3. Всего несколько месяцев спустя, 9 июня 2020 года, Гленн Джохер, который был упомянут в документе YOLO v4 для увеличения данных Mosaic Бочковским и др. и внес значительный вклад в архитектуру YOLOv3 (более 2000 коммитов и создание mAP из 33 до 45.6.) — выпущена YOLO v5 без официальной бумаги. Он просто открыл исходный код YOLO v5 на Github.com (Jocher, 2020).

YOLOv5 не основан на даркнете, а полностью реализован в PyTorch. Согласно результатам mAP, показанным для YOLO v4 в наборе данных MS COCO, значения mAP YOLO v5 почти такие же высокие. Самая большая модель YOLO v5x имеет несколько более высокое значение mAP (Kin-Yiu, 2020).

Джохер также обсудил эффективность обучения на Github.com Repo/Issues, заявив, что «наш самый маленький YOLOv5 обучается на COCO всего за 3 дня на одном 2080Ti и выполняет вывод быстрее и точнее, чем EfficientDet D0, который был обучен на 32 ядрах TPUv3 компанией Команда Google Brain. Кроме того, мы стремимся сравнимо превзойти D1, D2 и т. д. с остальной частью семейства YOLOv5 »(Jocher, 2020)
В следующей статье я рассмотрю эффективность обучения и логического вывода на разных аппаратных платформах.
Следите за обновлениями!
Рекомендации
Ахмад Р., 2020 г. Все о YOLO — Часть 4 — YOLOv3, постепенное улучшение. [В сети]
Доступно по адресу: https://medium.com/analytics-vidhya/all-about-yolos-part4-yolov3-an-incremental-improvement-36b1eee463a2
Бочковский А., 2020. Github.com, YOLOv5 О воспроизведенных результатах Обсуждение. [В сети]
Доступно по адресу: https://github.com/ultralytics/yolov5/issues/6#issuecomment-643644347
Бочковский А., Ван С.-Ю. и Ляо, Х.-Ю. М., 2020. YOLOv4: Оптимальная скорость и точность обнаружения объектов. arXiv,том arXiv:2004.10934v1.
Чен, Л.-К., Папандреу, Г., Мерфи, К. и Юилле, А.Л., 2017. DeepLab: сегментация семантического изображения с помощью глубоких сверточных сетей, Atrous Convolution и полносвязных CRF. arXiv,том arXiv:1606.00915v2.
Гиршик, Р., 2015. Fast R-CNN. arXiv,выпуск 1504.08083v2.
Гиршик Р., Донахью Дж., Даррелл Т. и Малик Дж., 2013 г. Многочисленные иерархии функций для точного обнаружения объектов и семантической сегментации. [Онлайн]
Доступно по адресу: https://arxiv.org/pdf/1311.2524.pdf
Грель Т., 2017 г. Объяснение области объединения интересов. [Онлайн]
Доступно по адресу: https://deepsense.ai/region-of-interest-pooling-explained/
Он, К., Гкиоксари, Г., Доллар, П. и Гиршик, Р., 2017. Маска R-CNN. arXiv,том arXiv:1703.06870v3.
Хе, К., Чжан, X., Рен, С. и Сан, Дж., 2015. Объединение пространственных пирамид в глубоких сверточных сетях для визуального распознавания.
Ху, Дж. и др., 2019. Сети сжатия и возбуждения. arXiv,том arXiv:1709.01507v4.
Джохер Г., 2020 г. Github.com, Issues. [В сети]
Доступно по адресу: https://github.com/ultralytics/yolov5/issues/2#issuecomment-642425558
Джохер, Г., 2020. YOLOv5. [В сети]
Доступно по адресу: https://github.com/ultralytics/yolov5
Кин-Ю, В., 2020 г. Github.com. [В сети]
Доступно по адресу: https://github.com/ultralytics/yolov5/issues/6#issuecomment-647069454
Лин, Т.-Ю. и др., 2018. Потеря фокуса для обнаружения плотных объектов. arXiv,том arXiv:1708.02002v2.
Лю С., Хуанг Д. и Ван Ю., 2018. Сеть блоков рецептивного поля для точного и быстрого обнаружения объектов. arXiv,том arXiv:1711.07767v3 .
Лю, В. и др., 2016. SSD: однократный детектор MultiBox.
Редмон, Дж., Диввала, С., Гиршик, Р. и Фархади, А., 2015. Вы только посмотрите один раз: унифицированное обнаружение объектов в реальном времени. arXiv,выдайте arXiv:1506.02640v5.
Редмон, Дж., Диввала, С., Гиршик, Р. и Фархади, А., 2016. Вы только посмотрите один раз: унифицированное обнаружение объектов в реальном времени.
Редмон, Дж. и Фархади, А., 2016 г. YOLO9000: лучше, быстрее, сильнее. arXiv,выдайте arXiv:1612.08242v1.
Редмон, Дж. и Фархади, А., 2018 г. YOLOv3: постепенное улучшение. arXiv,том arXiv:1804.02767v1.
Рен, С., Хе, К., Гиршик, Р. и Сан, Дж., 2015. Быстрее R-CNN: на пути к обнаружению объектов в реальном времени с сетями региональных предложений. arXiv,том 1506.01497v3.
Сегеди, К., Ванхуке, В., Иоффе, С. и Шленс, Дж., 2015. Переосмысление исходной архитектуры для компьютерного зрения. arXiv,том arXiv:1512.00567v3 .
Твиттер, 2020 г. Твиттер. [В сети]
Доступно по адресу: https://twitter.com/pjreddie/status/1230524770350817280?s=20
Ву, С., Парк, Дж., Ли, Дж.-Ю. и Квеон, И. С., 2018. CBAM: модуль внимания сверточных блоков. arXiv,том arXiv:1807.06521v2.
Чжао, З.-К., Чжэн, П., Сюй, С.-т. & Wu, X., 2019. Обнаружение объектов с помощью глубокого обучения: обзор. arXiv,том arXiv:1807.05511v2.